
Distributed Systems Tracing with Zipkin
Thursday, 7 June 2012
Zipkin is a distributed tracing system that we created to help us gather timing data for all the disparate services involved in managing a request to the Twitter API. As an analogy, think of it as a performance profiler, like Firebug, but tailored for a website backend instead of a browser. In short, it makes Twitter faster. Today we’re open sourcing Zipkin under the APLv2 license to share a useful piece of our infrastructure with the open source community and gather feedback.

Here’s the Zipkin web user interface. This example displays the trace view for a web request. You can see the time spent in each service compared to the scale on top and all the services involved in the request on the left. You can click on those for more detailed information.
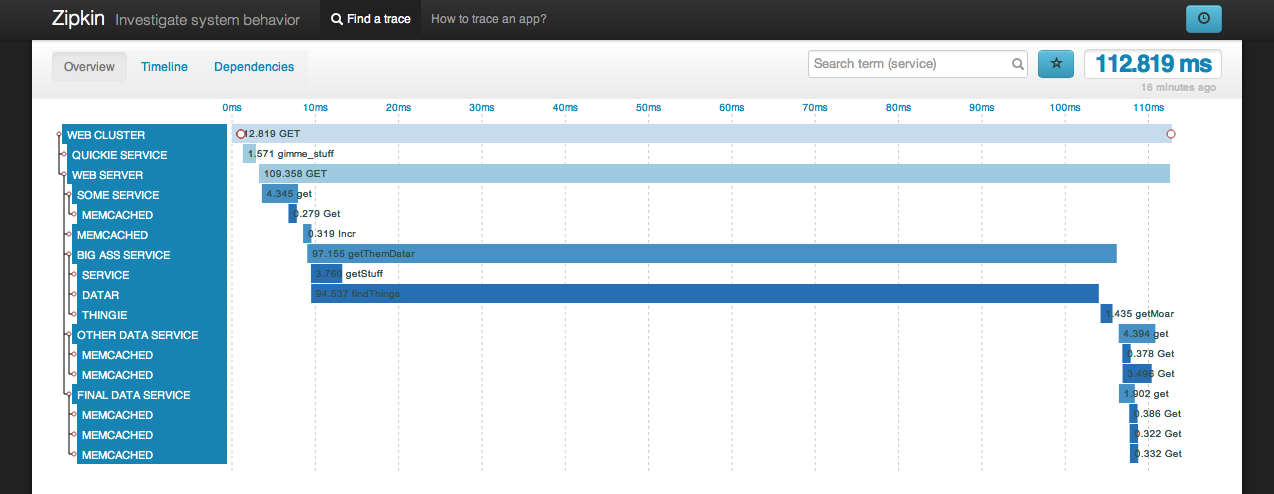
Zipkin has helped us find a whole slew of untapped performance optimizations, such as removing memcache requests, rewriting slow MySQL SELECTs, and fixing incorrect service timeouts. Finding and correcting these types of performance bottlenecks helps make Twitter faster.
Whenever a request reaches Twitter, we decide if the request should be sampled. We attach a few lightweight trace identifiers and pass them along to all the services used in that request. By only sampling a portion of all the requests we reduce the overhead of tracing, allowing us to always have it enabled in production.
The Zipkin collector receives the data via Scribe and stores it in Cassandra along with a few indexes. The indexes are used by the Zipkin query daemon to find interesting traces to display in the web UI.
Zipkin started out as a project during our first Hack Week. During that week we implemented a basic version of the Google Dapper paper for Thrift. Today it has grown to include support for tracing Http, Thrift, Memcache, SQL and Redis requests. These are mainly done via our Finagle library in Scala and Java, but we also have a gem for Ruby that includes basic tracing support. It should be reasonably straightforward to add tracing support for other protocols and in other libraries.
Zipkin was primarily authored by Johan Oskarsson (@skr) and Franklin Hu (@thisisfranklin). The project relies on a bunch of Twitter libraries such as Finagle and Scrooge but also on Cassandra for storage, ZooKeeper for configuration, Scribe for transport, Bootstrap and D3 for the UI. Thanks to the authors of those projects, the authors of the Dapper paper as well as the numerous people at Twitter involved in making Zipkin a reality. A special thanks to @iano, @couch, @zed, @dmcg, @marius and @a_a for their involvement. Last but not least we’d like to thank @jeajea for designing the Zipkin logo.
On the whole, Zipkin was initially targeted to support Twitter’s infrastructure of libraries and protocols, but can be extended to support more systems that can be used within your infrastructure. Please let us know on Github if you find any issues and pull requests are always welcome. If you want to stay in touch, follow @ZipkinProject and check out the upcoming talk at Strange Loop 2012. If distributed systems tracing interests you, consider joining the flock to make things better.
- Chris Aniszczyk, Manager of Open Source (@cra)
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.