
hRaven and the @HadoopSummit
Wednesday, 26 June 2013
Today marks the start of the Hadoop Summit, and we are thrilled to be a part of it. A few of our engineers will be participating in talks about our Hadoop usage at the summit:
As Twitter’s use of Hadoop and MapReduce rapidly expands, tracking usage on our clusters grows correspondingly more difficult. With an ever-increasing job load (tens of thousands of jobs per day), and a reliance on higher level abstractions such as Apache Pig and Scalding, the utility of existing tools for viewing job history decreases rapidly.
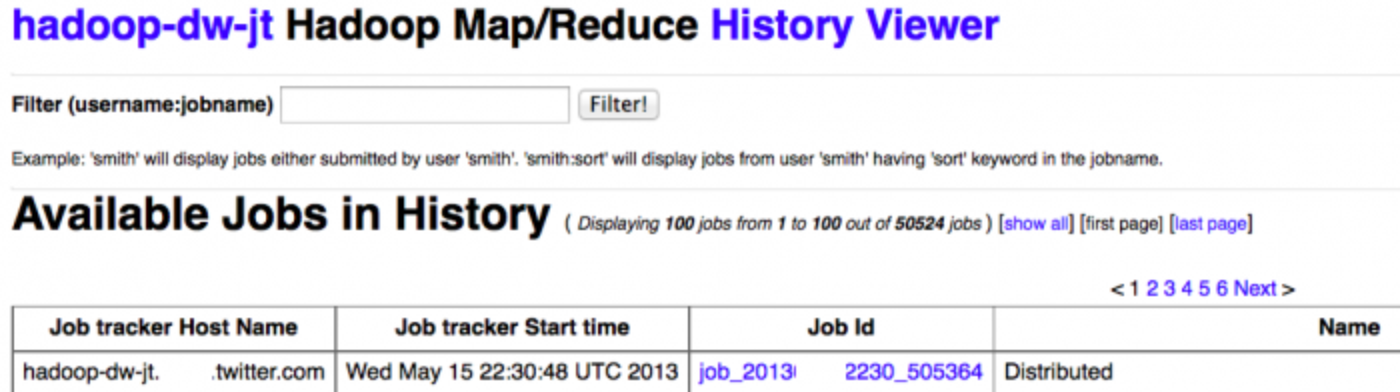
Note how paging through a very large number of jobs becomes unrealistic, especially when newly finished jobs push jobs rapidly through pages before you can navigate there.

Extracting insights and browsing thousands of jobs becomes a challenge using the existing JobTracker user interface. We created hRaven to improve this situation and are open sourcing the code on GitHub today at the Hadoop Summit under the Apache Public License 2.0 to share with the greater Hadoop community.

There were many questions we wanted to answer when we were created hRaven. For example, how many Pig versus Scalding jobs do we run? What cluster capacity do jobs in my pool take? How many jobs do we run each day? What percentage of jobs have more than 30,000 tasks? Why do I need to hand-tune these (hundreds) of jobs, can’t the cluster learn and do it?
We found that the existing tools were unable to start answering these questions at our scale.
hRaven archives the full history and metrics from all MapReduce jobs on clusters and strings together each job from a Pig or Scalding script execution into a combined flow. From this archive, we can easily derive aggregate resource utilization by user, pool, or application. Historical trending of an individual application allows us to perform runtime optimization of resource scheduling. The key concepts in hRaven are:
hRaven stores statistics, job configuration, timing and counters for every MapReduce job on every cluster. The key metrics stored are:
This structured data around the full DAG of MapReduce jobs allows you to query for historical trending information or better yet, job optimization based on historical execution information. A concrete example is a custom Pig parallelism estimator querying hRaven that we use to automatically adjust reducer count.
Data is loaded into hRaven into three steps, coordinated through ProcessRecords which record processing state in HBase:
First, the HDFS JobHistory location is scanned and the JobHistory and JobConfiguration file names of newly completed jobs are added to a sequence file. Then a mapreduce job runs on the source cluster to load the JobHistory and JobConfiguration files into HBase in parallel. Then in the third step a mapreduce job runs on the HBase cluster to parse the JobHistory and store individual stats and indexes.
hRaven provides access to all of its stored data via a REST API, allowing auxiliary services such as web UIs and other tools to be built on it with ease.
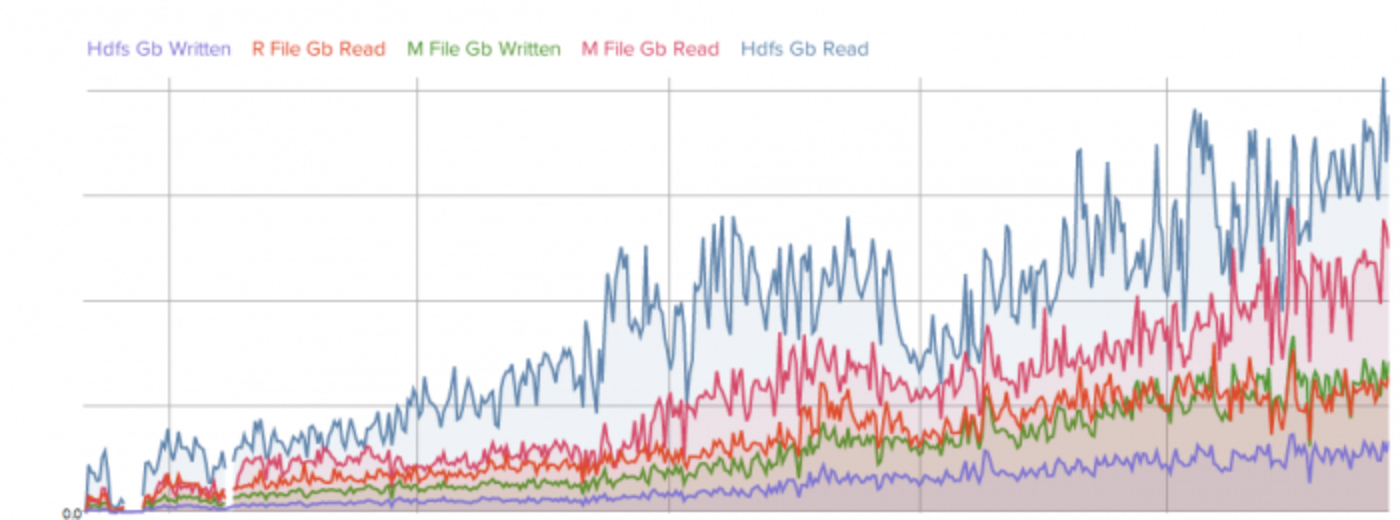
Below is a screenshot of an Twitter internal reporting application based on hRaven data showing overall cluster growth. Similarly we can visualize spikes in load over time, changes in reads and writes by application and by pool, as well as aspects such as pool usage vs. allocation. We also use hRaven data to calculate compute cost along varying dimensions.
In the near future, we want to add real time data loading from JobTracker and come up with a full flow-centric replacement for the JobTracker user interface (on top of integrating with the Ambrose project). We would also like hRaven be enhanced to capture flow information from jobs run by frameworks other than Pig and Cascading, for instance Hive. Furthermore, we are in the process of supporting Hadoop 2.0 and want to focus on building a community around hRaven.
The project is still young, so if you’d like to help work on any features or have any bug fixes, we’re always looking for contributions or people to join the flock to expand our @corestorage team. In particular, we are looking for engineers with Hadoop and HBase experience. To say hello, just submit a pull request, follow @TwitterHadoop or reach out to us on the mailing list. If you find something broken or have feature request ideas, report it in the issue tracker.
hRaven was primarily authored by Gary Helmling (@gario), Joep Rottinghuis (@joep), Vrushali Channapattan (@vrushalivc) and Chris Trezzo (@ctrezzo) from the Twitter @corestorage Hadoop team. In addition, we’d like to acknowledge the following folks who contributed to the project either directly or indirectly: Bill Graham (@billgraham), Chandler Abraham (@cba), Chris Aniszczyk (@cra), Michael Lin (@mlin) and Dmitriy Ryaboy (@squarecog).
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.