
New Tweets per second record, and how!
Friday, 16 August 2013
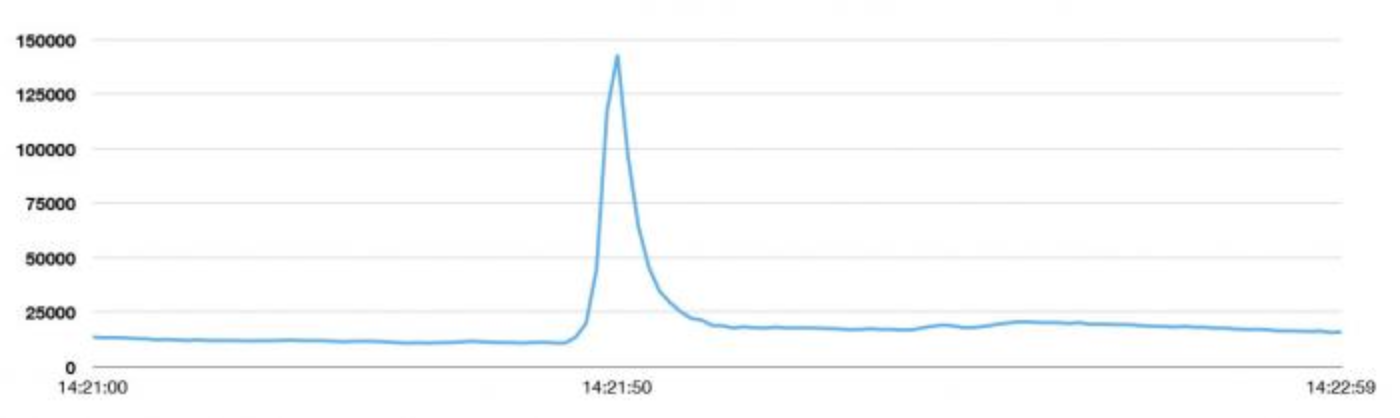
Recently, something remarkable happened on Twitter: On Saturday, August 3 in Japan, people watched an airing of Castle in the Sky, and at one moment they took to Twitter so much that we hit a one-second peak of 143,199 Tweets per second. (August 2 at 7:21:50 PDT; August 3 at 11:21:50 JST)
To give you some context of how that compares to typical numbers, we normally take in more than 500 million Tweets a day which means about 5,700 Tweets a second, on average. This particular spike was around 25 times greater than our steady state.
During this spike, our users didn’t experience a blip on Twitter. That’s one of our goals: to make sure Twitter is always available no matter what is happening around the world.
New Tweets per second (TPS) record: 143,199 TPS. Typical day: more than 500 million Tweets sent; average 5,700 TPS.
This goal felt unattainable three years ago, when the 2010 World Cup put Twitter squarely in the center of a real-time, global conversation. The influx of Tweets –– from every shot on goal, penalty kick and yellow or red card –– repeatedly took its toll and made Twitter unavailable for short periods of time. Engineering worked throughout the nights during this time, desperately trying to find and implement order-of-magnitudes of efficiency gains. Unfortunately, those gains were quickly swamped by Twitter’s rapid growth, and engineering had started to run out of low-hanging fruit to fix.
After that experience, we determined we needed to step back. We then determined we needed to re-architect the site to support the continued growth of Twitter and to keep it running smoothly. Since then we’ve worked hard to make sure that the service is resilient to the world’s impulses. We’re now able to withstand events like Castle in the Sky viewings, the Super Bowl, and the global New Year’s Eve celebration. This re-architecture has not only made the service more resilient when traffic spikes to record highs, but also provides a more flexible platform on which to build more features faster, including synchronizing direct messages across devices, Twitter cards that allow Tweets to become richer and contain more content, and a rich search experience that includes stories and users. And more features are coming.
Below, we detail how we did this. We learned a lot. We changed our engineering organization. And, over the next few weeks, we’ll be publishing additional posts that go into more detail about some of the topics we cover here.
Starting to re-architect
After the 2010 World Cup dust settled, we surveyed the state of our engineering. Our findings:
We concluded that we needed to start a project to re-envision our system. We set three goals and challenges for ourselves:
We prototyped the building blocks for a proof of concept re-architecture. Not everything we tried worked and not everything we tried, in the end, met the above goals. But we were able to settle on a set of principles, tools, and an infrastructure that has gotten us to a much more desirable and reliable state today.
The JVM vs the Ruby VM
First, we evaluated our front-end serving tier across three dimensions: CPU, RAM, and network. Our Ruby-based machinery was being pushed to the limit on the CPU and RAM dimensions –– but we weren’t serving that many requests per machine nor were we coming close to saturating our network bandwidth. Our Rails servers, at the time, had to be effectively single threaded and handle only one request at a time. Each Rails host was running a number of Unicorn processes to provide host-level concurrency, but the duplication there translated to wasteful resource utilization. When it came down to it, our Rails servers were only capable of serving 200 - 300 requests / sec / host.
Twitter’s usage is always growing rapidly, and doing the math there, it would take a lot of machines to keep up with the growth curve.
At the time, Twitter had experience deploying fairly large scale JVM-based services –– our search engine was written in Java, and our Streaming Api infrastructure as well as Flock, our social graph system, was written in Scala. We were enamored by the level of performance that the JVM gave us. It wasn’t going to be easy to get our performance, reliability, and efficiency goals out of the Ruby VM, so we embarked on writing code to be run on the JVM instead. We estimated that rewriting our codebase could get us > 10x performance improvement, on the same hardware –– and now, today, we push on the order of 10 - 20K requests / sec / host.
There was a level of trust that we all had in the JVM. A lot of us had come from companies where we had experience working with, tuning, and operating large scale JVM installations. We were confident we could pull off a sea change for Twitter in the world of the JVM. Now, we had to decompose our architecture and figure out how these different services would interact.
Programming model
In Twitter’s Ruby systems, concurrency is managed at the process level: a single network request is queued up for a process to handle. That process is completely consumed until the network request is fulfilled. Adding to the complexity, architecturally, we were taking Twitter in the direction of having one service compose the responses of other services. Given that the Ruby process is single-threaded, Twitter’s “response time” would be additive and extremely sensitive to the variances in the back-end systems’ latencies. There were a few Ruby options that gave us concurrency; however, there wasn’t one standard way to do it across all the different VM options. The JVM had constructs and primitives that supported concurrency and would let us build a real concurrent programming platform.
It became evident that we needed a single and uniform way to think about concurrency in our systems and, specifically, in the way we think about networking. As we all know, writing concurrent code (and concurrent networking code) is hard and can take many forms. In fact, we began to experience this. As we started to decompose the system into services, each team took slightly different approaches. For example, the failure semantics from clients to services didn’t interact well: we had no consistent back-pressure mechanism for servers to signal back to clients and we experienced “thundering herds” from clients aggressively retrying latent services. These failure domains informed us of the importance of having a unified, and complementary, client and server library that would bundle in notions of connection pools, failover strategies, and load balancing. To help us all get in the same mindset, we put together both Futures and Finagle.
Now, not only did we have a uniform way to do things, but we also baked into our core libraries everything that all our systems needed so we could get off the ground faster. And rather than worry too much about how each and every system operated, we could focus on the application and service interfaces.
Independent systems
The largest architectural change we made was to move from our monolithic Ruby application to one that is more services oriented. We focused first on creating Tweet, timeline, and user services –– our “core nouns”. This move afforded us cleaner abstraction boundaries and team-level ownership and independence. In our monolithic world, we either needed experts who understood the entire codebase or clear owners at the module or class level. Sadly, the codebase was getting too large to have global experts and, in practice, having clear owners at the module or class level wasn’t working. Our codebase was becoming harder to maintain, and teams constantly spent time going on “archeology digs” to understand certain functionality. Or we’d organize “whale hunting expeditions” to try to understand large scale failures that occurred. At the end of the day, we’d spend more time on this than on shipping features, which we weren’t happy with.
Our theory was, and still is, that a services oriented architecture allows us to develop the system in parallel –– we agree on networking RPC interfaces, and then go develop the system internals independently –– but, it also meant that the logic for each system was self-contained within itself. If we needed to change something about Tweets, we could make that change in one location, the Tweet service, and then that change would flow throughout our architecture. In practice, however, we find that not all teams plan for change in the same way: for example, a change in the Tweet service may require other services to do an update if the Tweet representation changed. On balance, though, this works out more times than not.
This system architecture also mirrored the way we wanted, and now do, run the Twitter engineering organization. Engineering is set up with (mostly) self-contained teams that can run independently and very quickly. This means that we bias toward teams spinning up and running their own services that can call the back end systems. This has huge implications on operations, however.
Storage
Even if we broke apart our monolithic application into services, a huge bottleneck that remained was storage. Twitter, at the time, was storing tweets in a single master MySQL database. We had taken the strategy of storing data temporally –– each row in the database was a single tweet, we stored the tweets in order in the database, and when the database filled up we spun up another one and reconfigured the software to start populating the next database. This strategy had bought us some time, but, we were still having issues ingesting massive tweet spikes because they would all be serialized into a single database master so we were experiencing read load concentration on a small number of database machines. We needed a different partitioning strategy for Tweet storage.
We took Gizzard, our framework to create sharded and fault-tolerant distributed databases, and applied it to tweets. We created T-Bird. In this case, Gizzard was fronting a series of MySQL databases –– every time a tweet comes into the system, Gizzard hashes it, and then chooses an appropriate database. Of course, this means we lose the ability to rely on MySQL for unique ID generation. Snowflake was born to solve that problem. Snowflake allows us to create an almost-guaranteed globally unique identifier. We rely on it to create new tweet IDs, at the tradeoff of no longer having “increment by 1” identifiers. Once we have an identifier, we can rely on Gizzard then to store it. Assuming our hashing algorithm works and our tweets are close to uniformly distributed, we increase our throughput by the number of destination databases. Our reads are also then distributed across the entire cluster, rather than being pinned to the “most recent” database, allowing us to increase throughput there too.
Observability and statistics
We’ve traded our fragile monolithic application for a more robust and encapsulated, but also complex, services oriented application. We had to invest in tools to make managing this beast possible. Given the speed with which we were creating new services, we needed to make it incredibly easy to gather data on how well each service was doing. By default, we wanted to make data-driven decisions, so we needed to make it trivial and frictionless to get that data.
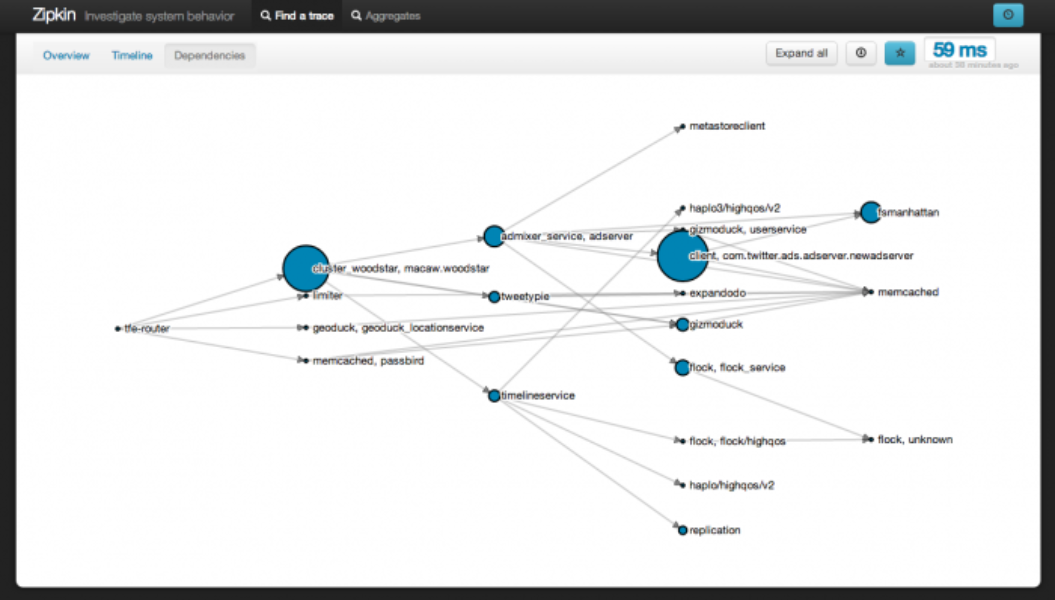
As we were going to be spinning up more and more services in an increasingly large system, we had to make this easier for everybody. Our Runtime Systems team created two tools for engineering: Viz and Zipkin. Both of these tools are exposed and integrated with Finagle, so all services that are built using Finagle get access to them automatically.
stats.timeFuture("request_latency_ms") {
// dispatch to do work
}
The above code block is all that is needed for a service to report statistics into Viz. From there, anybody using Viz can write a query that will generate a timeseries and graph of interesting data like the 50th and 99th percentile of request_latency_ms.
Runtime configuration and testing
Finally, as we were putting this all together, we hit two seemingly unrelated snags: launches had to be coordinated across a series of different services, and we didn’t have a place to stage services that ran at “Twitter scale”. We could no longer rely on deployment as the vehicle to get new user-facing code out there, and coordination was going to be required across the application. In addition, given the relative size of Twitter, it was becoming difficult for us to run meaningful tests in a fully isolated environment. We had, relatively, no issues testing for correctness in our isolated systems –– we needed a way to test for large scale iterations. We embraced runtime configuration.
We integrated a system we call Decider across all our services. It allows us to flip a single switch and have multiple systems across our infrastructure all react to that change in near-real time. This means software and multiple systems can go into production when teams are ready, but a particular feature doesn’t need to be “active”. Decider also allows us to have the flexibility to do binary and percentage based switching such as having a feature available for x% of traffic or users. We can deploy code in the fully “off” and safe setting, and then gradually turn it up and down until we are confident it’s operating correctly and systems can handle the new load. All this alleviates our need to do any coordination at the team level, and instead we can do it at runtime.
Today
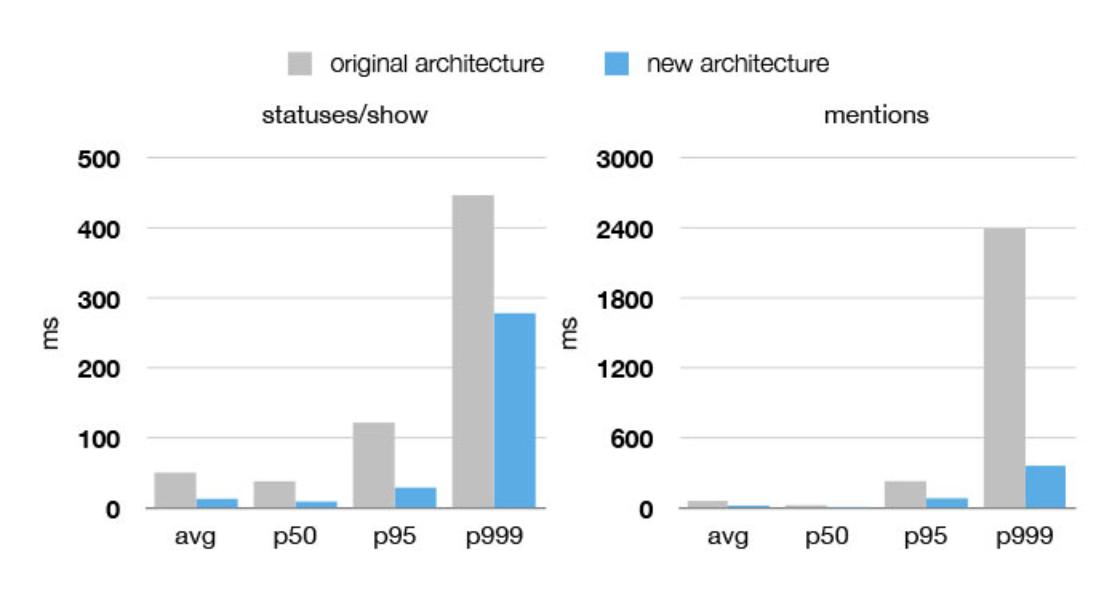
Twitter is more performant, efficient and reliable than ever before. We’ve sped up the site incredibly across the 50th (p50) through 99th (p99) percentile distributions and the number of machines involved in serving the site itself has been decreased anywhere from 5x-12x. Over the last six months, Twitter has flirted with four 9s of availability.
Twitter engineering is now set up to mimic our software stack. We have teams that are ready for long term ownership and to be experts on their part of the Twitter infrastructure. Those teams own their interfaces and their problem domains. Not every team at Twitter needs to worry about scaling Tweets, for example. Only a few teams –– those that are involved in the running of the Tweet subsystem (the Tweet service team, the storage team, the caching team, etc.) –– have to scale the writes and reads of Tweets, and the rest of Twitter engineering gets APIs to help them use it.
Two goals drive us as we did all this work: Twitter should always be available for our users, and we should spend our time making Twitter more engaging, more useful and simply better for our users. Our systems and our engineering team now enable us to launch new features faster and in parallel. We can dedicate different teams to work on improvements simultaneously and have minimal logjams for when those features collide. Services can be launched and deployed independently from each other (in the last week, for example, we had more than 50 deploys across all Twitter services), and we can defer putting everything together until we’re ready to make a new build for iOS or Android.
Keep an eye on this blog and @twittereng for more posts that will dive into details on some of the topics mentioned above.
Thanks goes to Jonathan Reichhold (@jreichhold), David Helder (@dhelder), Arya Asemanfar (@a_a), Marcel Molina (@noradio), and Matt Harris (@themattharris) for helping contribute to this blog post.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.