
Fighting spam with BotMaker
Wednesday, 20 August 2014
Spam on Twitter is different from traditional spam primarily because of two aspects of our platform: Twitter exposes developer APIs to make it easy to interact with the platform and real-time content is fundamental to our user’s experience.
These constraints mean that spammers know (almost) everything Twitter’s anti-spam systems know through the APIs, and anti-spam systems must avoid adding latency to user-visible operations. These operating conditions are a stark contrast to the constraints placed upon more traditional systems, like email, where data is private and adding latency of tens of seconds goes unnoticed.
So, to fight spam on Twitter, we built BotMaker, a system that we designed and implemented from the ground up that forms a solid foundation for our principled defense against unsolicited content. The system handles billions of events every day in production, and we have seen a 40% reduction in key spam metrics since launching BotMaker.
In this post we introduce BotMaker and discuss our overall architecture. All of the examples in this post are used to illustrate the use of BotMaker, not actual rules running in production.
BotMaker architecture
Goals, challenges and BotMaker overview
The goal of any anti-spam system is to reduce spam that the user sees while having nearly zero false positives. Three key principles guided our design of Botmaker:
BotMaker achieves these goals by receiving events from Twitter’s distributed systems, inspecting the data according to a set of rules, and then acting accordingly. BotMaker rules, or bots as they are known internally, are decomposed into two parts: conditions for deciding whether or not to act on an event, and actions that dictate what the caller should do with this particular event. For example, a simple rule for denying any Tweets that contain a spam url would be:
Condition: HasSpamUrl(GetUrls(tweetText)) Action: Deny()
The net effect of this rule is that BotMaker will deny any Tweets that match this condition.
The main challenges in supporting this type of system are evaluating rules with low enough latency that they can run on the write path for Twitter’s main features (i.e., Tweets, Retweets, favorites, follows and messages), supporting computationally intense machine learning based rules, and providing Twitter engineers with the ability to modify and create new rules instantaneously.
For the remainder of this blog post, we discuss how we solve these challenges.
When we run BotMaker
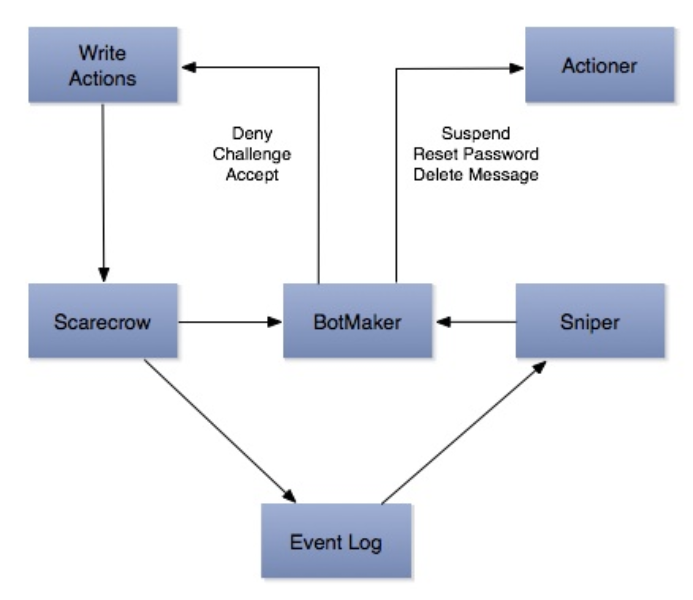
The ideal spam defense would detect spam at the time of creation, but in practice this is difficult due to the latency requirements of Twitter. We have a combination of systems (see figure above) that detect spam at various stages.
The BotMaker rule language
In addition to when BotMaker runs, we have put considerable time into designing an intuitive and powerful interface for guiding how BotMaker runs. Specifically: our BotMaker language is type safe, all data structures are immutable, all functions are pure except for a few well marked functions for storing data atomically, and our runtime supports common functional programming idioms. Some of the language highlights include:
Sample bot
Here is a bot that demonstrates some of the above features. Lets say we want to get all users that are receiving blocks due to mentions that they have posted in the last 24 hours.
Here is what the rule would look like:
Condition:
Count(
Intersection(
UsersBlocking(spammerId, 1day),
UsersMentionedBy(spammerId, 1day)
)
) >= 1
Actions:
Record(spammerId)
UsersBlocking and UsersMentionedBy are functions that return lists of users, which the bot intersects and gets a count of the result. If the count is more than one, then the user is recorded for analysis.
Impact and lessons learned
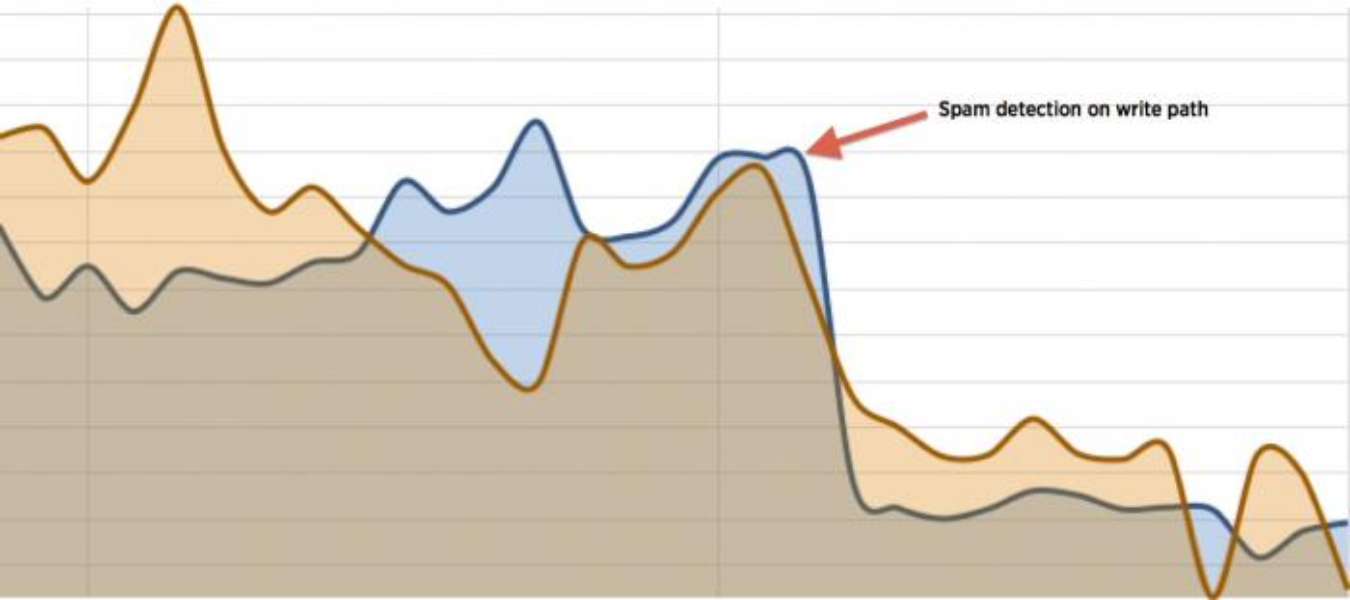
This figure shows the amount of spam we saw on Twitter before enabling spam checks on the write path for Twitter events. This graph spans 30 days with time on the x-axis and spam volume on the y-axis. After turning on spam checking on the write paths, we saw a 55% drop in spam on the system as a direct result of preventing spam content from being written.
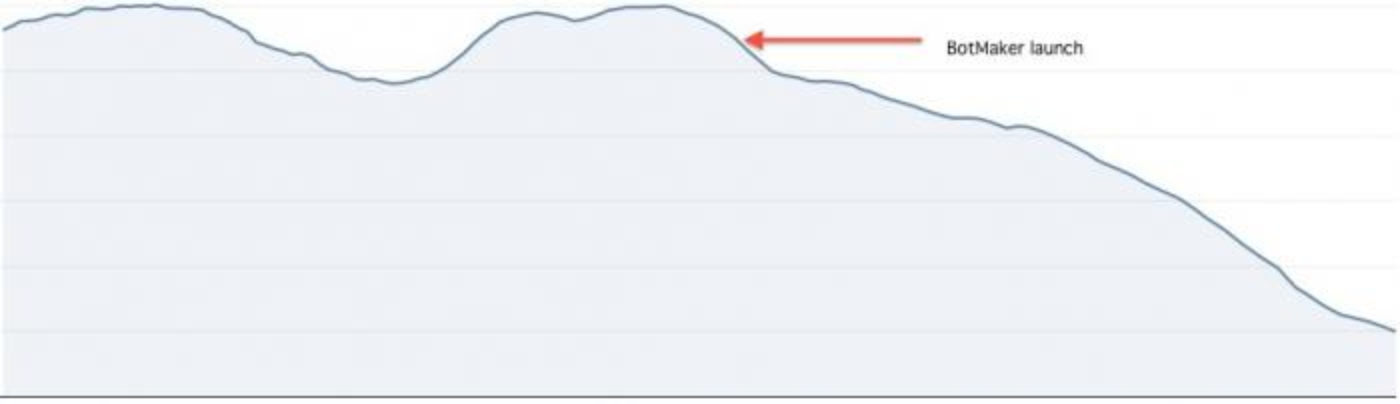
BotMaker has also helped us reduce our response time to spam attacks significantly. Before BotMaker, it took hours or days to make a code change, test and deploy, whereas using BotMaker it takes minutes to react. This faster reaction time has dramatically improved developer and operational efficiency, and it has allowed us to rapidly iterate and refine our rules and models, thus reducing the amount of spam on Twitter.
Once we launched BotMaker and started using it to fight spam, we saw a 40% reduction in a metric that we use to track spam.
Conclusion
BotMaker has ushered in a new era of fighting spam at Twitter. With BotMaker, Twitter engineers now have the ability to create new models and rules quickly that can prevent spam before it even enters the system. We designed BotMaker to handle the stringent latency requirements of Twitter’s real-time products, while still supporting more computationally intensive spam rules.
BotMaker is already being used in production at Twitter as our main spam-fighting engine. Because of the success we have had handling the massive load of events, and the ease of writing new rules that hit production systems immediately, other groups at Twitter have started using BotMaker for non-spam purposes. BotMaker acts as a fundamental interposition layer in our distributed system. Moving forward, the principles learned from BotMaker can help guide the design and implementation of systems responsible for managing, maintaining and protecting the distributed systems of today and the future.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.