
Manhattan, our real-time, multi-tenant distributed database for Twitter scale
Wednesday, 2 April 2014
As Twitter has grown into a global platform for public self-expression and conversation, our storage requirements have grown too. Over the last few years, we found ourselves in need of a storage system that could serve millions of queries per second, with extremely low latency in a real-time environment. Availability and speed of the system became the utmost important factor. Not only did it need to be fast; it needed to be scalable across several regions around the world.
Over the years, we have used and made significant contributions to many open source databases. But we found that the real-time nature of Twitter demanded lower latency than the existing open source products were offering. We were spending far too much time firefighting production systems to meet the performance expectations of our various products, and standing up new storage capacity for a use case involved too much manual work and process. Our experience developing and operating production storage at Twitter’s scale made it clear that the situation was simply not sustainable. So we began to scope out and build Twitter’s next generation distributed database, which we call Manhattan. We needed it to take into account our existing needs, as well as put us in a position to leapfrog what exists today.
Our holistic view into storage systems at Twitter
Different databases today have many capabilities, but through our experience we identified a few requirements that would enable us to grow the way we wanted while covering the majority of use cases and addressing our real-world concerns, such as correctness, operability, visibility, performance and customer support. Our requirements were to build for:
Developers should be able to store whatever they need on a system that just works.
Reliability at scale
When we started building Manhattan, we already had many large storage clusters at Twitter, so we understood the challenges that come from running a system at scale, which informed what kinds of properties we wanted to encourage and avoid in a new system.
A reliable storage system is one that can be trusted to perform well under all states of operation, and that kind of predictable performance is difficult to achieve. In a predictable system, worst-case performance is crucial; average performance not so much. In a well implemented, correctly provisioned system, average performance is very rarely a cause of concern. But throughout the company we look at metrics like p999 and p9999 latencies, so we care how slow the 0.01% slowest requests to the system are. We have to design and provision for worst-case throughput. For example, it is irrelevant that steady-state performance is acceptable, if there is a periodic bulk job that degrades performance for an hour every day.
Because of this priority to be predictable, we had to plan for good performance during any potential issue or failure mode. The customer is not interested in our implementation details or excuses; either our service works for them and for Twitter or it does not. Even if we have to make an unfavorable trade-off to protect against a very unlikely issue, we must remember that rare events are no longer rare at scale.
With scale comes not only large numbers of machines, requests and large amounts of data, but also factors of human scale in the increasing number of people who both use and support the system. We manage this by focusing on a number of concerns:
And finally, we built Manhattan with the experience that when operating at scale, complexity is one of your biggest enemies. Ultimately, simple and working trumps fancy and broken. We prefer something that is simple but works reliably, consistently and provides good visibility, over something that is fancy and ultra-optimal in theory but in practice and implementation doesn’t work well or provides poor visibility, operability, or violates other core requirements.
Building a storage system
When building our next generation storage system, we decided to break down the system into layers so it would be modular enough to provide a solid base that we can build on top of, and allow us to incrementally roll out features without major changes.
We designed with the following goals in mind:
Layers
We have separated Manhattan into four layers: interfaces, storage services, storage engines and the core.
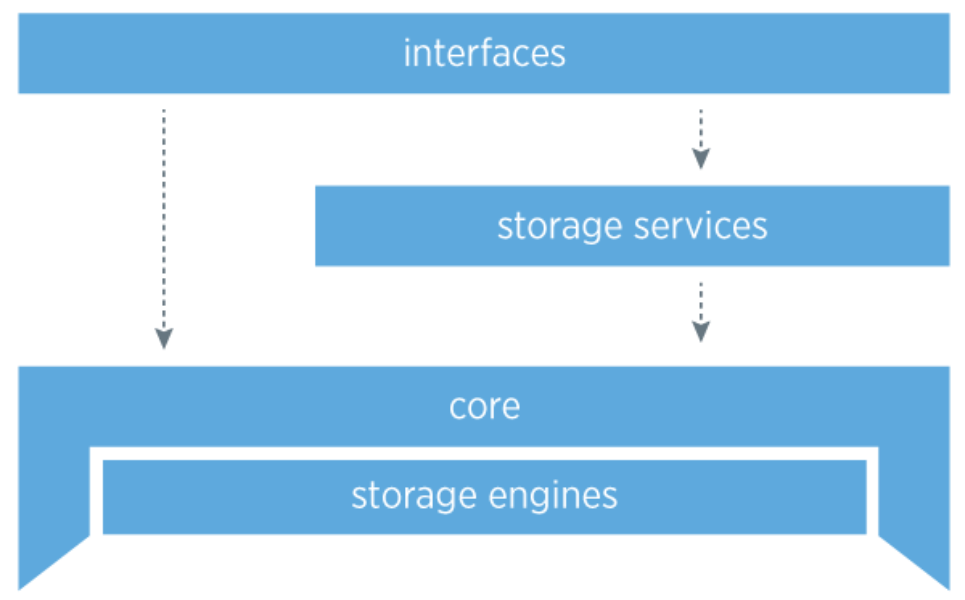
Core
The core is the most critical aspect of the storage system: it is highly stable and robust. It handles failure, eventual consistency, routing, topology management, intra- and inter-datacenter replication, and conflict resolution. Within the core of the system, crucial pieces of architecture are completely pluggable so we can iterate quickly on designs and improvements, as well as unit test effectively.
Operators are able to alter the topology at any time for adding or removing capacity, and our visibility and strong coordination for topology management are critical. We store our topology information in Zookeeper because of it’s strong coordination capabilities and because it is a managed component in our infrastructure at Twitter, though Zookeeper is not in the critical path for reads or writes. We also put a lot of effort into making sure we have extreme visibility into the core at all times with an extensive set of Ostrich metrics across all hosts for correctness and performance.
Consistency model
Many of Twitter’s applications fit very well into the eventually consistent model. We favor high availability over consistency in almost all use cases, so it was natural to build Manhattan as an eventually consistent system at its core. However, there will always be applications that require strong consistency for their data so building such a system was a high priority for adopting more customers. Strong consistency is an opt-in model and developers must be aware of the trade-offs. In a strongly consistent system, one will typically have a form of mastership for a range of partitions. We have many use cases at Twitter where having a hiccup of a few seconds of unavailability is simply not acceptable (due to electing new masters in the event of failures). We provide good defaults for developers and help them understand the trade-offs between both models.
Achieving consistency
To achieve consistency in an eventually consistent system you need a required mechanism which we call replica reconciliation. This mechanism needs to be incremental, and an always running process that reconciles data across replicas. It helps in the face of bitrot, software bugs, missed writes (nodes going down for long periods of time) and network partitions between datacenters. In addition to having replica reconciliation, there are two other mechanisms we use as an optimization to achieve faster convergence: read-repair, which is a mechanism that allows frequently accessed data to converge faster due to the rate of the data being read, and hinted-handoff, which is a secondary delivery mechanism for failed writes due to a node flapping, or being offline for a period of time.
Storage engines
One of the lowest levels of a storage system is how data is stored on disk and the data structures kept in memory. To reduce the complexity and risk of managing multiple codebases for multiple storage engines, we made the decision to have our initial storage engines be designed in-house, with the flexibility of plugging in external storage engines in the future if needed.
This gives us the benefit of focusing on features we find the most necessary and the control to review which changes go in and which do not. We currently have three storage engines:
All of our storage engines support block-based compression.
Storage services
We have created additional services that sit on top of the core of Manhattan that allow us to enable more robust features that developers might come to expect from traditional databases. Some examples are:
Interfaces
The interface layer is how a customer interacts with our storage system. Currently we expose a key/value interface to our customers, and we are working on additional interfaces such as a graph based interface to interact with edges.
Tooling
With the easy operability of our clusters as a requirement, we had to put a lot of thought into how to best design our tools for day-to-day operations. We wanted complex operations to be handled by the system as much as possible, and allow commands with high-level semantics to abstract away the details of implementation from the operator. We started with tools that allow us to change the entire topology of the system simply by editing a file with host groups and weights, and do common operations like restarting all nodes with a single command. When even that early tooling started to become too cumbersome, we built an automated agent that accepts simple commands as goals for the state of the cluster, and is able to stack, combine, and execute directives safely and efficiently with no further attention from an operator.
Storage as a service
A common theme that we saw with existing databases was that they were designed to be setup and administered for a specific set of use-cases. With Twitter’s growth of new internal services, we realized that this wouldn’t be efficient for our business.
Our solution is storage as a service. We’ve provided a major productivity improvement for our engineers and operational teams by building a fully self-service storage system that puts engineers in control.
Engineers can provision what their application needs (storage size, queries per second, etc) and start using storage in seconds without having to wait for hardware to be installed or for schemas to be set up. Customers within the company run in a multi-tenant environment that our operational teams manage for them. Managing self service and multi-tenant clusters imposes certain challenges, so we treat this service layer as first-class feature: we provide customers with visibility into their data and workloads, we have built-in quota enforcement and rate-limiting so engineers get alerted when they go over their defined thresholds, and all our information is fed directly to our Capacity and Fleet Management teams for analysis and reporting.
By making it easier for engineers to launch new features, we saw a rise in experimentation and a proliferation of new use-cases. To better handle these, we developed internal APIs to expose this data for cost analysis which allows us to determine what use cases are costing the business the most, as well as which ones aren’t being used as often.
Focus on the customer
Even though our customers are our fellow Twitter employees, we are still providing a service, and they are still our customers. We must provide support, be on call, isolate the actions of one application from another, and consider the customer experience in everything we do. Most developers are familiar with the need for adequate documentation of their services, but every change or addition to our storage system requires careful consideration. A feature that should be seamlessly integrated into self-service has different requirements from one that needs intervention by operators. When a customer has a problem, we must make sure to design the service so that we can quickly and correctly identify the root cause, including issues and emergent behaviors that can arise from the many different clients and applications through which engineers access the database. We’ve had a lot success building Manhattan from the ground up as a service and not just a piece of technology.
Multi-Tenancy and QoS (Quality of Service)
Supporting multi-tenancy — allowing many different applications to share the same resources — was a key requirement from the beginning. In previous systems we managed at Twitter, we were building out clusters for every feature. This was increasing operator burden, wasting resources, and slowing customers from rolling out new features quickly.
As mentioned above, allowing multiple customers to use the same cluster increases the challenge of running our systems. We now must think about isolation, management of resources, capacity modeling with multiple customers, rate limiting, QoS, quotas, and more.
In addition to giving customers the visibility they need to be good citizens, we designed our own rate limiting service to enforce customers usage of resources and quotas. We monitor and, if needed, throttle resource usage across many metrics to ensure no one application can affect others on the system. Rate limiting happens not at a coarse grain but at a subsecond level and with tolerance for the kinds of spikes that happen with real world usage. We had to consider not just automatic enforcement, but what controls should be available manually to operators to help us recover from issues, and how we can mitigate negative effects to all customers, including the ones going over their capacity.
We built the APIs needed to extract the data for every customer and send it to our Capacity teams, who work to ensure we have resources always ready and available for customers who have small to medium requirements (by Twitter standards), so that those engineers can get started without additional help from us. Integrating all of this directly into self-service allows customers to launch new features on our large multi-tenant clusters faster, and allows us to absorb traffic spikes much more easily since most customers don’t use all of their resources at all times.
Looking ahead
We still have a lot of work ahead of us. The challenges are increasing and the number of features being launched internally on Manhattan is growing at rapid pace. Pushing ourselves harder to be better and smarter is what drives us on the Core Storage team. We take pride in our values: what can we do to make Twitter better, and how do we make our customers more successful? We plan to release a white paper outlining even more technical detail on Manhattan and what we’ve learned after running over two years in production, so stay tuned!
Acknowledgments
We want to give a special thank you to Armond Bigian, for helping believe in the team along the way and championing us to make the best storage system possible for Twitter. The following people made Manhattan possible: Peter Schuller, Chris Goffinet, Boaz Avital, Spencer Fang, Ying Xu, Kunal Naik, Yalei Wang, Danny Chen, Melvin Wang, Bin Zhang, Peter Beaman, Sree Kuchibhotla, Osama Khan, Victor Yang Ye, Esteban Kuber, Tugrul Bingol, Yi Lin, Deng Liu, Tyler Serdar Bulut, Andy Gross, Anthony Asta, Evert Hoogendoorn, Lin Lee, Alex Peake, Yao Yue, Hyun Kang, Xin Xiang, Sumeet Lahorani, Rachit Arora, Sagar Vemuri, Petch Wannissorn, Mahak Patidar, Ajit Verma, Sean Wang, Dipinder Rekhi, Satish Kotha, Johan Harjono, Alex Young, Kevin Donghua Liu, Pascal Borghino, Istvan Marko, Andres Plaza, Ravi Sharma, Vladimir Vassiliouk, Ning Li, Liang Guo, Inaam Rana.
If you’d like to work on Manhattan and enjoy tackling hard problems in distributed storage, apply to the Core Storage Team at jobs.twitter.com!
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.