
Twitter experimentation: technical overview
Friday, 6 November 2015
In our previous post, we discussed the motivation for doing A/B testing at Twitter, and how A/B testing helps us innovate. We will now describe how the backend of Twitter’s A/B system is implemented.
Overview
The Twitter experimentation tool, Duck Duck Goose (DDG for short), was first created in 2010. It has evolved into a system that is capable of aggregating many terabytes of data such as Tweets, social graph changes, server logs, and records of user interactions with web and mobile clients, to measure and analyze a large amount of flexible metrics.
At a high level, the flow of data is fairly straightforward.
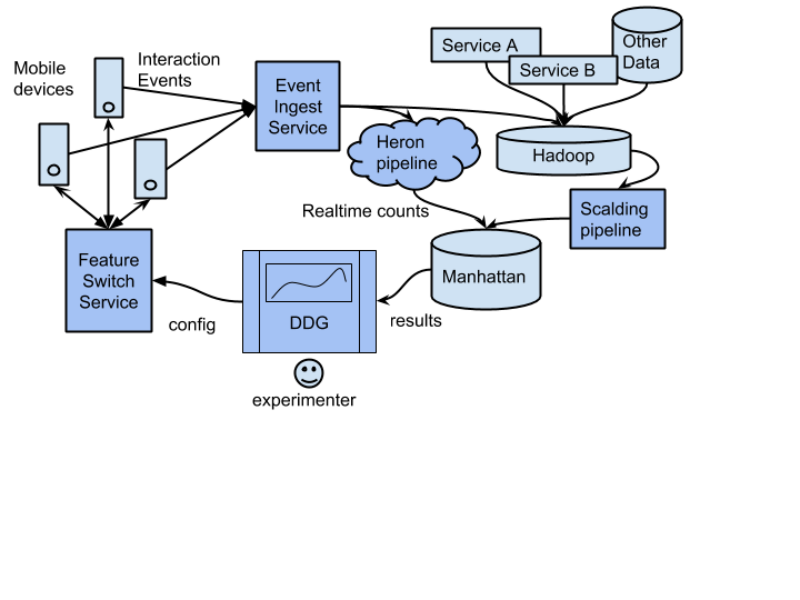
Data processing pipeline
An engineer creates an experiment via a web UI, and specifies a few details:
DDG then gives the engineer a bit of code to use to check which treatment should be shown to a user. To a feature developer, this is simply a kind of “Feature Switch,” a generic mechanism used to control feature availability. We log an “ab test impression” any time the application decides whether a user is an experiment. Delaying such decisions until a user is going to be affected by the experiment increases statistical power.
Data about Twitter app usage is sent to the event ingest service. Some lightweight statistics are computed in a streaming job using TSAR running on Heron. The bulk of the work is done offline, using a Scalding pipeline that combines client event interaction logs, internal user models, and other datasets.
The Scalding pipeline can be thought of as having three distinct stages.
First, we aggregate the raw sources to generate a dataset of metric values on a per-user, per-hour basis. The result looks something like this:
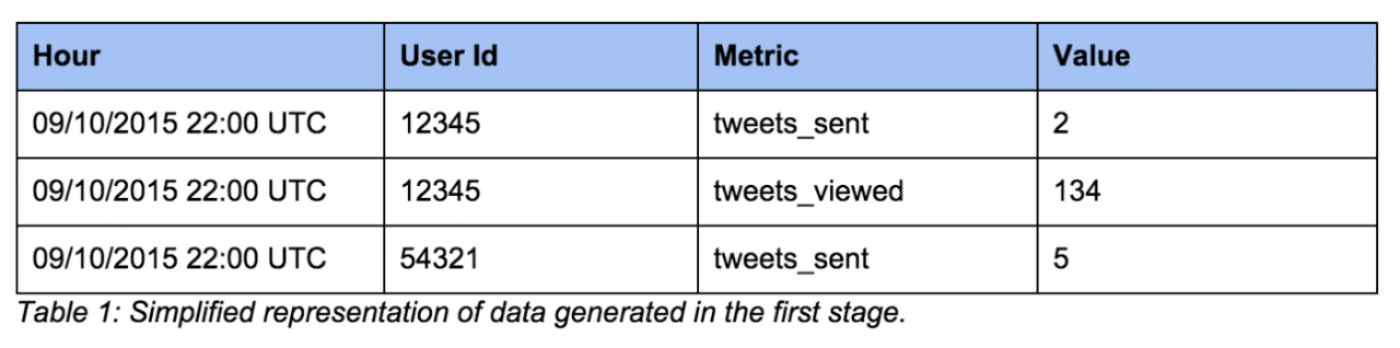
This creates input data for the next stage, as well as a resource for analyses other than experimentation — top-level metric calculations, ad-hoc cohorting, and so on.
We then join these per-user metrics with information about experiment ab test impressions, and calculate aggregate values per metric, per user, during the experiment’s runtime. Since a user might enter different experiments at different times, such an aggregate can have different values in different experiments.
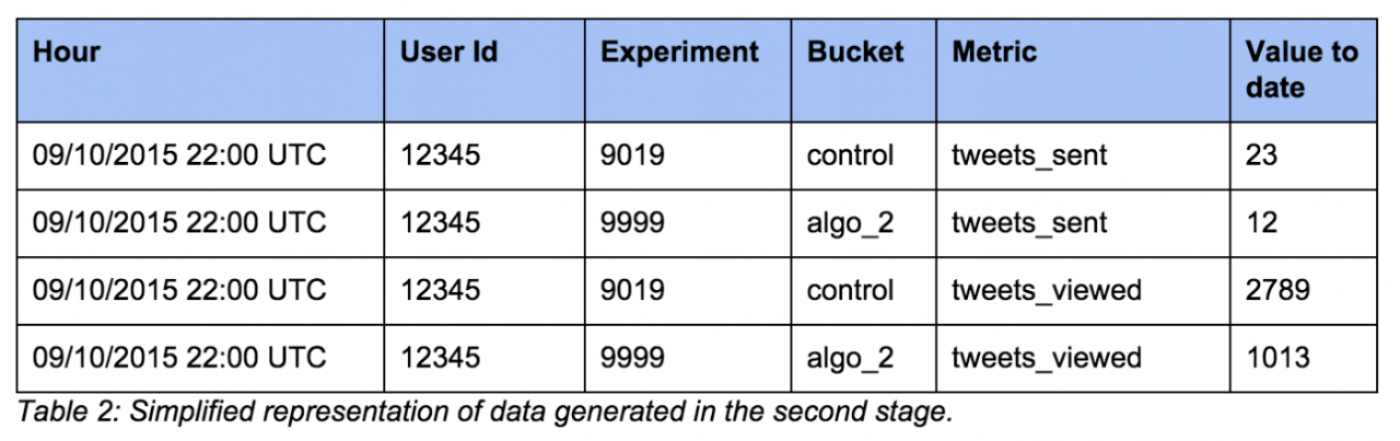
We also record the time the user first entered the experiment, whether they were a new, casual, or frequent user at that time, and other metadata. This allows for experiment result segmentation and measurement of changes in attribute values during the course of the experiment.
Results of this second stage are great for deep dives into experiments and research into alternative analysis approaches — they let us iterate on different aggregation techniques, stratification approaches, various algorithms for dealing with outliers, and so on.
Finally, a third stage of aggregation runs which rolls up all experiment data:

This is the final experiment result data that gets loaded into Manhattan and served to our product teams via internal dashboards.
Defining metrics
DDG is a platform meant to allow measurement of very different features, some of them not invented yet. This means we need to balance predictability and stability of metric definitions with a large amount of flexibility.
We offer three types of metrics, in descending order of centralized control and specification:
To help experimenters find the right sets of metrics, and keep metric definitions correct and current, metrics are collected and organized into “metric groups.” Each metric group is owned and curated by teams that create them. Version history, ownership, and other attributes are tracked for all metric groups. This encourages sharing and communication among experimenters.
As the number of interesting combinations of tracked events, and number of experimenters, grows over time, redundant metrics sometimes get created. This can cause confusion (“What’s the difference between the built-in “Foobar Quality” metric, and the “Quality of Foobar” metric that Bob defined?”). An interesting project on our “TODO” list is creating a way to automatically identify metrics that appear to measure mostly the same thing, and suggest metric reconciliation.
Scaling the pipeline
Getting the aggregation pipeline to run efficiently is one of the biggest challenges in this system. The interactions data source alone is responsible for hundreds of billions of events on a daily basis; relatively small inefficiencies can significantly impact total runtime and processing cost.
We found that lightweight, constant profiling of Hadoop Map-Reduce jobs is important for quick analysis of performance problems. To that effect, we worked with the Hadoop team to make on-demand task jvm profiling available in our Hadoop build (by implementing YARN-445 and a number of follow-up items), as well as instrumenting one-click thread dumps and turning on automated XProf profiling for all tasks.
Through profiling we found a number of opportunities to improve efficiency. For example, we found a few places to memoize results of custom metric event matching. We made a pass to replace strings with generated numeric ids when possible. We also used a number of tricks specific to Hadoop Map-Reduce: sort and spill buffer tuning for map and reduce stages, data sorting to achieve maximal map-side collapse during aggregations, early projection, and so on.
During a Hack Week in early 2015, we noticed that a large amount of time was spent inside Hadoop map tasks’ SpillThread, which is responsible for sorting partial map outputs and writing them to disk. A large fraction of the SpillThread was spent deserializing output keys and sorting them. Hadoop provides a RawComparator interface to let Hadoop power users avoid this, but it wasn’t implemented for Thrift objects we were using.
We built a prototype that implemented a generic RawComparator for Thrift-serialized structures, and benchmarked the gains. Our prototype cut a few corners, and the benchmark tested a worst-case scenario, but the resulting 80% gain was significant enough that we recruited a couple of engineers from the Scalding team to really implement this idea for Thrift, Scala Tuples, and case classes. This turned into the OrderedSerialization feature released in Scalding 0.15. Turning this on for the DDG jobs resulted in 30% savings of overall compute time! More details about this work can be found in the “Performance Optimization At Scale” talk that the Scalding team delivered at Hadoop Summit 2015.
Finally, we have two levels of defense to ensure that we do not introduce performance regressions: prevention and detection. To prevent regressions, in addition to regular unit tests, we have automation that allows us to run a full end to end pipeline in a staging environment, and compare both the results (to ensure correctness) and all Hadoop counters (to check for performance regressions). To detect performance problems if they do happen in production, we created a Scala trait which allows Scalding jobs to export all Hadoop counters to Twitter’s internal observability infrastructure. This means that we can easily generate dashboards for our Scalding jobs using common templates, create alerts for problems like not running or running for too long, check on certain classes of permissible errors happening at too-high a rate, and more.
Conclusion
The infrastructure required to power the Twitter experimentation platform is quite extensive, largely due to the sheer volume of data that needs to be processed to analyze the experiments. The system must balance flexibility of available metrics with predictability and ease of analysis; the pipeline is designed to produce data at multiple granularities to enable different kinds of analysis. A great amount of effort goes into making processing efficient, including automated full-scale testing and continuous improvements to profiling and monitoring capabilities in Hadoop.
Acknowledgements
A number of Twitter engineers worked on these tools over the years; we want to particularly acknowledge contributions by Chuang Liu, Jimmy Chen, Peter Seibel, Zachary Taylor, Nodira Khoussainova, Richard Whitcomb, Luca Clementi, Gera Shegalov, Ian O’Connell, Oscar Boykin, Mansur Ashraf, and others from PIE, Scalding, and Hadoop teams.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.