Infrastructure
Omnisearch index formats
By
Friday, 4 November 2016
One critical feature of Omnisearch, Twitter’s new information retrieval system, is flexibility. In addition to Tweets, we want to be able to index any interesting content at Twitter that could be used to build a new product. Before Omnisearch, our search infrastructure was highly customized for Tweets. In this post, we discuss how we have evolved our search technology to accommodate diverse document types (i.e. content in addition to Tweets), the surprising performance impact of these changes, and how we are using this improved technology to power Twitter’s latest product efforts
Earlybird is the indexing technology at the core of Omnisearch. To understand what it does and how we have improved it, we must first review the two most important data structures in search engines: the inverted index and the postings list. Imagine we have a collection of Tweets, each with an ID and some text that we want to search (only 3 Tweets are shown):
A forward index on these Tweets would allow you to efficiently look up Tweet text by ID. This is the kind of index commonly added to database tables. In contrast, an inverted index would allow you to efficiently look up a list of Tweet IDs by a term in their text. We call the lists of IDs postings lists, and each ID added to a list is a posting.
Given an inverted index, we can execute search queries by taking the union and/or intersection of postings lists, scoring the resulting candidate documents, and returning the best ones. For phrase queries, term position matters too. For example, the query “say I” would match Tweet 1 but not Tweet 2. Even though both Tweet 1 and Tweet 2 contain both words, “say” and “I” only appear next to each other in Tweet 1. To execute phrase queries, we store term position information with each posting (shown here in parentheses, 0-indexed):
There are a few important things to consider when building inverted indexes:
Earlybird has two custom postings list formats: an “active” postings list and an “optimized” postings list. The inverted index composed of active postings lists handles concurrent reads and writes using a single-writer, multi-reader lock-free data structure and algorithm. This allows us to achieve low-latency writes and high-throughput reads simultaneously — a key feature for a true real-time search engine. After the active list gets to some size (typically 8M documents), we optimize it into a read-only format to reduce size and query cost, allowing us to store and search more documents on a single machine.
For the remainder of this blog post, we focus on the read-only, optimized postings list format. To learn more about the active postings list format, see Earlybird: Real-Time Search at Twitter.
In the original optimized postings list format, postings were stored in blocks of 64 integers, with each posting using the minimum number of bits possible to express the Tweet ID and the position. Consider the Tweet ID / position pairs from the postings list for “i” in the above example:
Outside of our search index, Tweet IDs are stored in 64-bit integers to accommodate both the large numbers of Tweets (hundreds of billions) and to allow us to create unique Tweet IDs with minimal coordination. However, inside the index, using 64 bits of storage per posting would be prohibitively expensive. To compress Tweet IDs, we first mapped the full 64-bit ID into a 0-indexed local ID:
With this alone, we would have needed significantly fewer than 64 bits to represent the local IDs. However, with delta compression, were able to save even more space. To delta compress the list, we replaced each local ID with the difference between itself and the previous local ID:
Notice the delta between the last two postings is 25, which is smaller than 50 and requires fewer bits to store. The binary representation of 50 uses 6 bits (110010) while the binary representation of 25 uses only 5 bits (11001). In a postings list for a common term (which could have millions of postings), the deltas tend to stay small while the local Tweet IDs monotonically increase, making this a powerful space-saving technique.
Instead of using a variable byte encoding for the deltas (e.g. Lucene’s VInt encoding), we calculated the minimum number of bits needed to store any delta and position in the list:
In our example, the minimum number of bits needed to represent a delta in this list is 5, while the minimum number of bits required to represent a position is 3. Hence, we would need 8 bits for each delta-position pair:
Finally, we bit-packed the postings together for very efficient storage:
A naive, uncompressed representation would likely use a 64-bit long for the Tweet ID and a 32-bit integer for the position, requiring 384 bits of memory to store the first four postings in our example. In contrast, the above representation would fit the first four postings into 32 bits, a 92% savings.
For storage of postings, the original implementation divided memory into blocks of 64 32-bit integers (2-Kbit blocks). For long postings lists, we used many such blocks. This gave us good cache locality when scanning through postings lists, which is required for union and intersection algorithms.
From the above example, the first block of the postings list for the term “i” would look like:
The calculated number of bits required for a delta-position pair only applies to one 2-Kbit postings block, meaning each block must be encoded and decoded independently. To decode a block, we needed to remember:
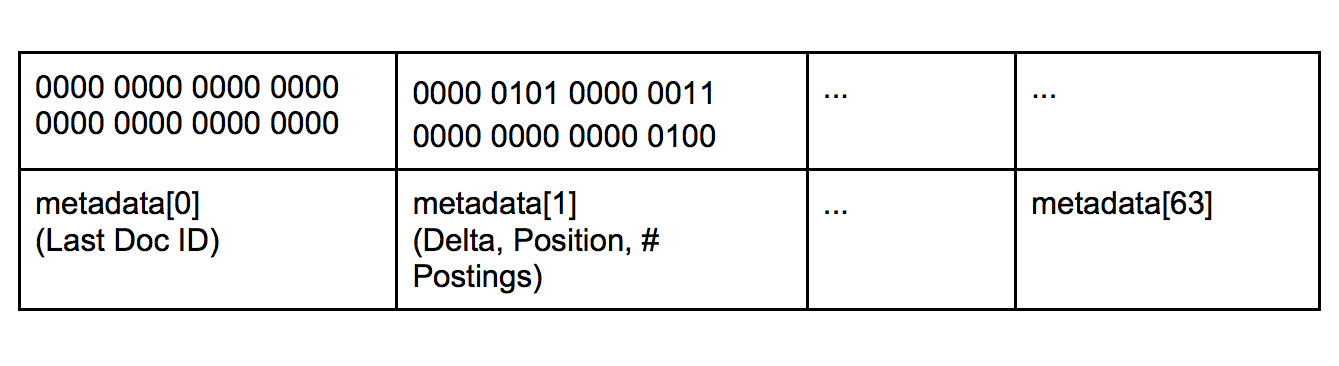
In our example above, we used 5 (101b) bits for delta (so we could store 11001b), 3 (11b) bits for position (so we could store 101b), and indexed 4 (100b) postings. Packing this information into 32 bits gives:
00000101 00000011 0000000000000100
We also had an optimization for efficiently skipping through long lists: for each block of postings, we used 32 bits to store the uncompressed last document ID of the previous block. This allowed us to decode only the blocks that might have hits. For the first block, we used 0 as the last document ID. Thus, each postings block required two 32-bit integers to hold its metadata. Metadata was also stored in blocks of 64 32-bit integers. The metadata block for the above example would look like this:
Finally, in order to decode the entire postings list, we needed to store the number of metadata blocks in a header. In our original format, a complete postings list looked like this:
In addition to compact storage, efficient decoding is critical to an effective postings list implementation. Decoding the block-based format required extracting bit-packed postings from arrays of 32-bit integers. Typically, this is done via a sequence of shift and mask operations, which together extract the desired packed value from the array. Take for example the postings list for the term “i,” which was packed using 3 bits for delta and 5 bits for position (8 bits per posting):
To extract the 1st posting (0, 5), we would:
In this example, we only had to look up one integer from memory and perform four bitwise logical operations on it, which are typically quite efficient. However, if the desired posting spanned two packed integers, we would have to look up both integers and combine the two components of the posting, using additional memory and logical operations. Also, notice that we assumed knowledge of which integer(s) the desired posting was located in, how many bits to shift by, and which masks to use. In reality, these things depend on how the block was encoded and which posting we want to decode.
To improve the efficiency of the decoding algorithm, we started with the following observations:
From this, we can see that the number of masks and shifts needed to extract any value from the bit-packed array is finite. In our implementation, we pre-computed all possible shifts and masks and looked them up at decoding time, reducing the computation required for decoding and improving overall efficiency.
When compared to our active postings list format (which allows for concurrent reads and writes), we measured the above optimizations to save 55% of the memory and decrease query latency by about 50%. The below graph shows a single machine using the optimized format (light blue line) running concurrently with several other machines using the active format. When we shipped this in 2012, we were able to increase our index depth by 2.4x without additional hardware, dramatically increasing the coverage of Twitter’s search product.
In our original implementation, we chose to store the header, metadata blocks and postings blocks contiguously in memory. However, due to the variable number of postings that fit in a block, we could not predict ahead of time how many blocks a postings a list would require. Our solution was to pre-allocate a worst-case number of metadata blocks. To figure out how many metadata blocks we might need in the worst case, we assumed no more than 8 bits for a position and no more than 24 bits for a delta. In addition to wasting space in every postings list for unused metadata blocks, this decision introduced two limitations:
At the time, these tradeoffs were reasonable because:
For Omnisearch, these limitations are no longer tenable because we want to be able to index any interesting document at Twitter.
Another issue with this format arises when we decode a postings list at query time. In order to implement Lucene’s postings list iterator interface, our postings lists must be able to return the number of times a term appears in a document (to support the freq() method). Our original postings list format did not store this count directly. Instead, we scanned ahead in the list and counted the number of postings from the same document. Because Tweets are short, there are few duplicate terms in each document, and this approach was relatively efficient.
Our new optimized postings list format solves the above problems by storing postings, positions, and metadata in separate lists.
Postings Blocks
For postings, we continue to use delta compression, bit-packing and blocks of 64 integers. However, instead of storing delta-position pairs, we now store delta-count pairs. That is, if the same term appears 5 times in the document with ID 100, we store only one posting: (100, 5). From the above example, after computing deltas, we had:
Recall that the first two postings were from the same document (101). In our new format, we collapse them into one posting, replacing positions with counts:
This saves on storage and allows us to efficiently implement the freq() method in Lucene’s postings list iterator interface when we index longer documents. As a further optimization, since counts are at least 1 and often exactly 1, we store (count - 1) instead of count:
Notice that in this example, the minimum number of bits required to store a count drops from 2 to 1 per posting when we store (count - 1). Even better, if all counts are 1, we will actually use 0 bits per posting. The bit-packing and block-based storage steps are unchanged from the original format.
Positions Blocks
Without positional information the postings lists, we must store the positions somewhere else. For this, we have created a separate bit-packed, block-based list of positions. From our example, we take the original positions and calculate the minimum number of bits required to store them:
We then encode the positions using the minimum number of bits required and bit-pack them:
To decode a block of positions, we need to know the number of bits we used for position and the number of positions in the block. We store this in the first 32-bit integer of the block, using 5 bits for “bits per position” and 11 bits for “number of positions” (the remainder of the first 32-bit integer is unused). In our example, we need 3 bits per position and have 4 positions, so the header would be:
00011 00000000100 0000000000000000
And the first block of the positions list would look like:
Despite the potentially larger number of bits used per posting or position in these bit-packed data structures, the number of bits for any value is still finite and we continue to exploit lookup tables for efficient decoding.
Metadata
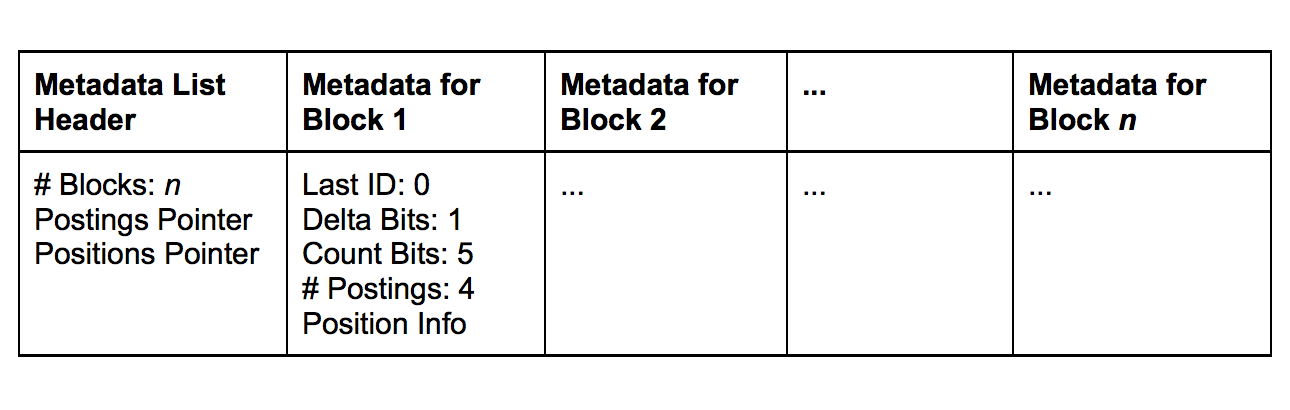
Finally, we store metadata separately from the postings and positions, with one metadata entry for every postings block. This eliminates the need to pre-allocate a worst-case number of metadata blocks for a postings list. Similar to the old format, for each postings block we store the following metadata:
Additionally, we need a way to find the positional information for the postings block when needed. For this, we store the index of the position block and the offset into it.
To decode the metadata list, it has a header that includes:
These changes eliminate the overhead of wasted metadata blocks and the limitations on position and list length. Assuming there are n blocks of postings lists, the metadata list would look like:
Together, the three data structures described above form a single postings list for a single term in our new optimized format.
With the improved flexibility of the new postings list format, we expected to sacrifice either latency or storage. However, instead of seeing a performance penalty, we found that the new format was about 2% more space efficient and 3% faster! In the graph below, the yellow line shows the average latency across Earlybird machines running the old postings list format and the blue line shows a canary host in the same cluster running with the new format.
As a result of this work, we are now able to store larger documents in our realtime indexes without recall issues or negative performance impact. A related product improvement recently shipped, wherein we no longer count media attachments (like photos, GIFs, videos, and polls) against the 140-character limit. In the future, we will be able to use the same technology to index other types of documents, allowing us to fulfill our ultimate vision: to provide search as a service, allowing us to build entirely new kinds of products.
The primary contributors to this work were Yan Zhao (@zhaoyan1117), Paul Burstein (@pasha407), Yi Zhuang (@yz), and Michael Busch (@michibusch). Other contributors included Dumitru Daniliuc (@twdumi), Bogdan Gaza (@hurrycane), Jane Wang (@jane12345689), Wei Li (@alexweili), Patrick Lok (@plok), Lei Wang (@wonlay), Stephen Bezek (@SteveBezek), Sergey Serebryakov (@megaserg), Joseph Barker, Maer Melo (@maaaaaer), Mark Sparhawk (@sparhawk), and Sam Luckenbill (@sam).
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.