Infrastructure
Building and Serving Conversations on Twitter
By
Saturday, 25 March 2017
Some of the most memorable interactions on Twitter occur because of the public conversations that take place on our service. Lately, we’ve been hearing feedback about a complication with these conversations – sometimes, when you reply to a Tweet, you aren’t able to see your reply in the conversation. Due to a longstanding technical capacity limitation, when there is an overwhelming volume of replies to a Tweet, our platform is unable to show all of these replies on the Tweet’s page. We’d like to explain more about this technical situation as well as how we’re addressing your concerns.
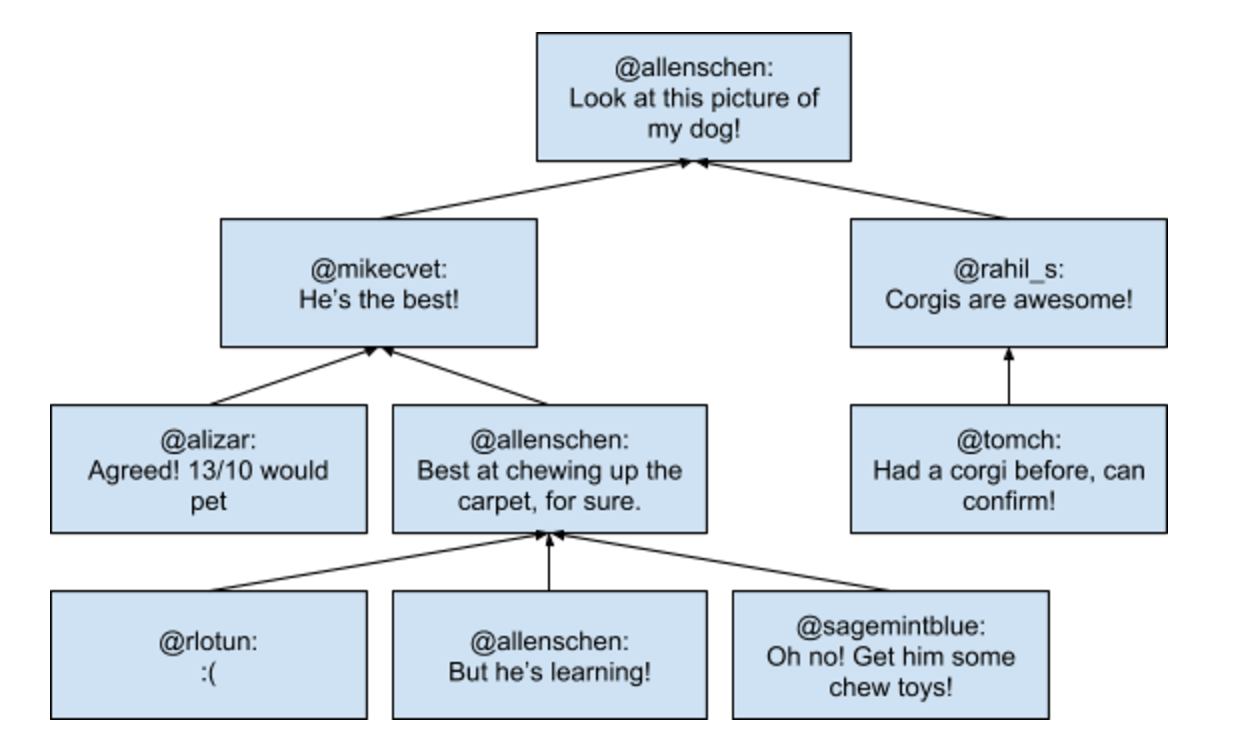
A core engineering challenge in building conversations lies in the flexibility of the product. Whenever someone using Twitter creates an original, non-reply Tweet, they’re actually creating the start of a potential new conversation. Others can then reply to that original or “root” Tweet and create their own reply branches. Compared to other platforms, conversations on Twitter are more flexible: accounts aren’t restricted to addressing their content directly at the root Tweet or first-level reply branches. Rather, replies on Twitter can be directed at almost any Tweet. As a result, Twitter’s conversations take on a tree structure where new nodes and edges can be inserted at any part of this tree below the root node.
Unfortunately, a Tweet by itself doesn’t have enough data regarding its own conversational context to construct a full conversation tree. A Tweet’s payload contains only two pieces of information about conversations:
If you were to construct the conversation tree with just a single Tweet’s data, you might be able to get a view of your Tweet’s parent nodes (up to the root of the tree) by following the in-reply-to Tweet ID chain. However, you wouldn’t be able to discover anything about Tweet branches below it. Moreover, this operation would be slow and wouldn’t be scalable for long reply chains. Without all this data, we aren’t able to efficiently show parents or replies to your Tweet. Therefore, we need something that provides the entire view of the conversation tree.
Twitter stores conversations separately in two places: our persistent graph storage and our timeline cache (Haplo). In both cases, we store little information about each Tweet in the conversation in order to keep its storage compact. We store its Tweet ID, its author ID and its in-reply-to Tweet ID.
Our legacy cache system, Haplo (more details here and here), is a cache service backed by a customized Redis. It serves the majority of the requests whenever a customer loads the Tweet page, where conversations are found. It’s a highly reliable service that has a lot of critical built-in features like hot-key detection: Tweet conversations are prone to spikes of traffic to a single key (in this case, a single conversation), especially when accounts with a lot of followers, who get a lot of engagement, Tweet. Hot-key detection alleviates pressure on our cache storage by aggressively caching responses in-memory within services. As a simple caching strategy, we store all Tweets that belong to a single conversation ID under a single key. To render a page, we pull the full set of Tweets and build a tree using the Tweet entries as nodes and their in-reply-to Tweet IDs as edges in the tree.
Unfortunately, Haplo has its limits. Since we try to pull every single Tweet ID in a conversation every time a conversation is loaded in real-time, this is potentially an unbounded amount of data. We’ve found that if our platform tries to load more than a certain number of entries from our cache at once, our cache request latency will spike, and we begin to time-out on a significant fraction of read requests. Because of this, there is a limit of thousands of Tweets per conversation tree in this cache.
Although the vast majority of conversations on Twitter don’t reach this cache limit, we regularly observe a small number of conversations which surpass this cap. When conversations exceed this limit, the cache begins omitting entries. These missing entries from the cache can cause the conversation’s tree-building process to lack information about the position of some nodes. Because of this, when there are an overwhelming volume of replies to a Tweet, our platform is unable to show all of these replies.
Recently, we’ve updated our service to better communicate what’s going on when our platform isn’t able to show every reply in a conversation, due to the capacity issue explained above. If your Tweet is a direct reply to the root Tweet of the conversation, when anyone taps on your Tweet, they will see it is connected to the root Tweet of the conversation. If your reply Tweet isn’t showing within a conversation with an overwhelming volume of replies, it may be because your Tweet is not directly replying to the conversation root, and you may see a message like the one below.
We know that you are passionate about conversations and we’re constantly looking to improve them – we are listening.
If you’re interested in working on interesting consumer products like conversations, join us – we’re hiring! Special thanks to Mike Cvet, Rahil Shah, Tommy Chong, Andy Schlaikjer, Aliza Rosen, Reza Lotun, Michael Montano, Edward Ho and the entire team for their contributions on conversations and for helping review this blog post.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.