
A Storm is coming: more details and plans for release
By
Thursday, 4 August 2011
We’ve received a lot of questions about what’s going to happen to Storm now that BackType has been acquired by Twitter. I’m pleased to announce that I will be releasing Storm at Strange Loop on September 19th! Check out the session info for more details.
In my preview post about Storm, I discussed how Storm can be applied to a huge variety of realtime computation problems. In this post, I’ll give more details on Storm and what it’s like to use.
Here’s a recap of the three broad use cases for Storm:
The beauty of Storm is that it’s able to solve such a wide variety of use cases with just a simple set of primitives.
A Storm cluster is superficially similar to a Hadoop cluster. Whereas on Hadoop you run “MapReduce jobs”, on Storm you run “topologies”. “Jobs” and “topologies” themselves are very different — one key difference is that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you kill it).
There are two kinds of nodes on a Storm cluster: the master node and the worker nodes. The master node runs a daemon called “Nimbus” that is similar to Hadoop’s “JobTracker”. Nimbus is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures.
Each worker node runs a daemon called the “Supervisor”. The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it. Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines.
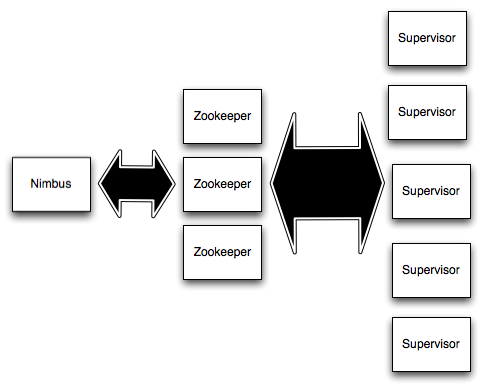
All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster. Additionally, the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This means you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. This design leads to Storm clusters being incredibly stable. We’ve had topologies running for months without requiring any maintenance.
Running a topology is straightforward. First, you package all your code and dependencies into a single jar. Then, you run a command like the following:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
This runs the class backtype.storm.MyTopology with the arguments arg1 and arg2. The main function of the class defines the topology and submits it to Nimbus. The storm jar part takes care of connecting to Nimbus and uploading the jar.
Since topology definitions are just Thrift structs, and Nimbus is a Thrift service, you can create and submit topologies using any programming language. The above example is the easiest way to do it from a JVM-based language.
Let’s dig into the abstractions Storm exposes for doing scalable realtime computation. After I go over the main abstractions, I’ll tie everything together with a concrete example of a Storm topology.
The core abstraction in Storm is the “stream”. A stream is an unbounded sequence of tuples. Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. For example, you may transform a stream of tweets into a stream of trending topics.
The basic primitives Storm provides for doing stream transformations are “spouts” and “bolts”. Spouts and bolts have interfaces that you implement to run your application-specific logic.
A spout is a source of streams. For example, a spout may read tuples off of a Kestrel queue and emit them as a stream. Or a spout may connect to the Twitter API and emit a stream of tweets.
A bolt does single-step stream transformations. It creates new streams based on its input streams. Complex stream transformations, like computing a stream of trending topics from a stream of tweets, require multiple steps and thus multiple bolts.
Multi-step stream transformations are packaged into a “topology” which is the top-level abstraction that you submit to Storm clusters for execution. A topology is a graph of stream transformations where each node is a spout or bolt. Edges in the graph indicate which bolts are subscribing to which streams. When a spout or bolt emits a tuple to a stream, it sends the tuple to every bolt that subscribed to that stream.

Everything in Storm runs in parallel in a distributed way. Spouts and bolts execute as many threads across the cluster, and they pass messages to each other in a distributed way. Messages never pass through any sort of central router, and there are no intermediate queues. A tuple is passed directly from the thread who created it to the threads that need to consume it.
Storm guarantees that every message flowing through a topology will be processed, even if a machine goes down and the messages it was processing get dropped. How Storm accomplishes this without any intermediate queuing is the key to how it works and what makes it so fast.
Let’s look at a concrete example of spouts, bolts, and topologies to solidify the concepts.
The example topology I’m going to show is “streaming word count”. The topology contains a spout that emits sentences, and the final bolt emits the number of times each word has appeared across all sentences. Every time the count for a word is updated, a new count is emitted for it. The topology looks like this:

Here’s how you define this topology in Java:
The spout for this topology reads sentences off of the “sentence_queue” on a Kestrel server located at kestrel.backtype.com on port 22133.
The spout is inserted into the topology with a unique id using the setSpout method. Every node in the topology must be given an id, and the id is used by other bolts to subscribe to that node’s output streams. The KestrelSpout is given the id “1” in this topology.
setBolt is used to insert bolts in the topology. The first bolt defined in this topology is the SplitSentence bolt. This bolt transforms a stream of sentences into a stream of words. Let’s take a look at the implementation of SplitSentence:
The key method is the execute method. As you can see, it splits the sentence into words and emits each word as a new tuple. Another important method is declareOutputFields, which declares the schema for the bolt’s output tuples. Here it declares that it emits 1-tuples with a field called “word”.
Bolts can be implemented in any language. Here is the same bolt implemented in Python:
The last parameter to setBolt is the amount of parallelism you want for the bolt. The SplitSentence bolt is given a parallelism of 10 which will result in 10 threads executing the bolt in parallel across the Storm cluster. To scale a topology, all you have to do is increase the parallelism for the bolts at the bottleneck of the topology.
The setBolt method returns an object that you use to declare the inputs for the bolt. Continuing with the example, the SplitSentence bolt subscribes to the output stream of component “1” using a shuffle grouping. “1” refers to the KestrelSpout that was already defined. I’ll explain the shuffle grouping part in a moment. What matters so far is that the SplitSentence bolt will consume every tuple emitted by the KestrelSpout.
A bolt can subscribe to multiple input streams by chaining input declarations, like so:
You would use this functionality to implement a streaming join, for instance.
The final bolt in the streaming word count topology, WordCount, reads in the words emitted by SplitSentence and emits updated counts for each word. Here’s the implementation of WordCount: WordCount maintains a map in memory from word to count. Whenever it sees a word, it updates the count for the word in its internal map and then emits the updated count as a new tuple. Finally, in declareOutputFields the bolt declares that it emits a stream of 2-tuples named “word” and “count”.
The internal map kept in memory will be lost if the task dies. If it’s important that the bolt’s state persist even if a task dies, you can use an external database like Riak, Cassandra, or Memcached to store the state for the word counts. An in-memory HashMap is used here for simplicity purposes.
Finally, the WordCount bolt declares its input as coming from component 2, the SplitSentence bolt. It consumes that stream using a “fields grouping” on the “word” field.
“Fields grouping”, like the “shuffle grouping” that I glossed over before, is a type of “stream grouping”. “Stream groupings” are the final piece that ties topologies together.
A stream grouping tells a topology how to send tuples between two components. Remember, spouts and bolts execute in parallel as many tasks across the cluster. If you look at how a topology is executing at the task level, it looks something like this:
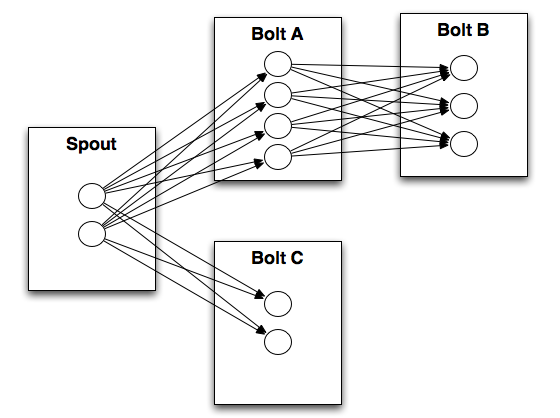
When a task for Bolt A emits a tuple to Bolt B, which task should it send the tuple to?
A “stream grouping” answers this question by telling Storm how to send tuples between sets of tasks. There’s a few different kinds of stream groupings.
The simplest kind of grouping is called a “shuffle grouping” which sends the tuple to a random task. A shuffle grouping is used in the streaming word count topology to send tuples from KestrelSpout to the SplitSentence bolt. It has the effect of evenly distributing the work of processing the tuples across all of SplitSentence bolt’s tasks.
A more interesting kind of grouping is the “fields grouping”. A fields grouping is used between the SplitSentence bolt and the WordCount bolt. It is critical for the functioning of the WordCount bolt that the same word always go to the same task. Otherwise, more than one task will see the same word, and they’ll each emit incorrect values for the count since each has incomplete information. A fields grouping lets you group a stream by a subset of its fields. This causes equal values for that subset of fields to go to the same task. Since WordCount subscribes to SplitSentence’s output stream using a fields grouping on the “word” field, the same word always goes to the same task and the bolt produces the correct output.
Fields groupings are the basis of implementing streaming joins and streaming aggregations as well as a plethora of other use cases. Underneath the hood, fields groupings are implemented using consistent hashing.
There are a few other kinds of groupings, but talking about those is beyond the scope of this post.
With that, you should now have everything you need to understand the streaming word count topology. The topology doesn’t require that much code, and it’s completely scalable and fault-tolerant. Whether you’re processing 10 messages per second or 100K messages per second, this topology can scale up or down as necessary by just tweaking the amount of parallelism for each component.
The abstractions that Storm provides are ultimately pretty simple. A topology is composed of spouts and bolts that you connect together with stream groupings to get data flowing. You specify how much parallelism you want for each component, package everything into a jar, submit the topology and code to Nimbus, and Storm keeps your topology running forever. Here’s a glimpse at what Storm does underneath the hood to implement these abstractions in an extremely robust way.
Guaranteed message processing: Storm guarantees that each tuple coming off a spout will be fully processed by the topology. To do this, Storm tracks the tree of messages that a tuple triggers. If a tuple fails to be fully processed, Storm will replay the tuple from the Spout. Storm incorporates some clever tricks to track the tree of messages in an efficient way.
An example of a system that does this poorly is Hadoop. When Hadoop launches a task, the burden for the task to exit is on the task itself. Unfortunately, tasks sometimes fail to exit and become orphan processes, sucking up memory and resources from other tasks.
In Storm, the burden of killing a worker process is on the supervisor that launched it. Orphaned tasks simply cannot happen with Storm, no matter how much you stress the machine or how many errors there are. Accomplishing this is tricky because Storm needs to track not just the worker processes it launches, but also subprocesses launched by the workers (a subprocess is launched when a bolt is written in another language).
The nimbus daemon and supervisor daemons are stateless and fail-fast. If they die, the running topologies aren’t affected. The daemons just start back up like nothing happened. This is again in contrast to how Hadoop works.
Fault detection and automatic reassignment: Tasks in a running topology heartbeat to Nimbus to indicate that they are running smoothly. Nimbus monitors heartbeats and will reassign tasks that have timed out. Additionally, all the tasks throughout the cluster that were sending messages to the failed tasks quickly reconnect to the new location of the tasks.
Efficient message passing: No intermediate queuing is used for message passing between tasks. Instead, messages are passed directly between tasks using ZeroMQ. This is simpler and way more efficient than using intermediate queuing. ZeroMQ is a clever “super-socket” library that employs a number of tricks for maximizing the throughput of messages. For example, it will detect if the network is busy and automatically batch messages to the destination.
Another important part of message passing between processes is serializing and deserializing messages in an efficient way. Again, Storm automates this for you. By default, you can use any primitive type, strings, or binary records within tuples. If you want to be able to use another type, you just need to implement a simple interface to tell Storm how to serialize it. Then, whenever Storm encounters that type, it will automatically use that serializer.
Local mode and distributed mode: Storm has a “local mode” where it simulates a Storm cluster completely in-process. This lets you iterate on your topologies quickly and write unit tests for your topologies. You can run the same code in local mode as you run on the cluster.
Storm is easy to use, configure, and operate. It is accessible for everyone from the individual developer processing a few hundred messages per second to the large company processing hundreds of thousands of messages per second.
Storm exists in the same space as “Complex Event Processing” systems like Esper, Streambase, and S4. Among these, the most closely comparable system is S4. The biggest difference between Storm and S4 is that Storm guarantees messages will be processed even in the face of failures whereas S4 will sometimes lose messages.
Some CEP systems have a built-in data storage layer. With Storm, you would use an external database like Cassandra or Riak alongside your topologies. It’s impossible for one data storage system to satisfy all applications since different applications have different data models and access patterns. Storm is a computation system and not a storage system. However, Storm does have some powerful facilities for achieving data locality even when using an external database.
I’ve only scratched the surface on Storm. The “stream” concept at the core of Storm can be taken so much further than what I’ve shown here — I didn’t talk about things like multi-streams, implicit streams, or direct groupings. I showed two of Storm’s main abstractions, spouts and bolts, but I didn’t talk about Storm’s third, and possibly most powerful abstraction, the “state spout”. I didn’t show how you do distributed RPC over Storm, and I didn’t discuss Storm’s awesome automated deploy that lets you create a Storm cluster on EC2 with just the click of a button.
For all that, you’re going to have to wait until September 19th. Until then, I will be working on adding documentation to Storm so that you can get up and running with it quickly once it’s released. We’re excited to release Storm, and I hope to see you there at Strange Loop when it happens.
- Nathan Marz (@nathanmarz)
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.