
Blobstore: Twitter’s in-house photo storage system
By
Tuesday, 11 December 2012
Millions of people turn to Twitter to share and discover photos. To make it possible to upload a photo and attach it to your Tweet directly from Twitter, we partnered with Photobucket in 2011. As soon as photos became a more native part of the Twitter experience, more and more people began using this feature to share photos.
In order to introduce new features and functionality, such as filters, and continue to improve the photos experience, Twitter’s Core Storage team began building an in-house photo storage system. In September, we began to use this new system, called Blobstore.
What is Blobstore?
Blobstore is Twitter’s low-cost and scalable storage system built to store photos and other binary large objects, also known as blobs. When we set out to build Blobstore, we had three design goals in mind:
How does it work?
When a user tweets a photo, we send the photo off to one of a set of Blobstore front-end servers. The front-end understands where a given photo needs to be written, and forwards it on to the servers responsible for actually storing the data. These storage servers, which we call storage nodes, write the photo to a disk and then inform a Metadata store that the image has been written and instruct it to record the information required to retrieve the photo. This Metadata store, which is a non-relational key-value store cluster with automatic multi-DC synchronization capabilities, spans across all of Twitter’s data centers providing a consistent view of the data that is in Blobstore.
The brain of Blobstore, the blob manager, runs alongside the front-ends, storage nodes, and index cluster. The blob manager acts as a central coordinator for the management of the cluster. It is the source of all of the front-ends’ knowledge of where files should be stored, and it is responsible for updating this mapping and coordinating data movement when storage nodes are added, or when they are removed due to failures.
Finally, we rely on Kestrel, Twitter’s existing asynchronous queue server, to handle tasks such as replicating images and ensuring data integrity across our data centers.
We guarantee that when an image is successfully uploaded to Twitter, it is immediately retrievable from the data center that initially received the image. Within a short period of time, the image is replicated to all of our other data centers, and is retrievable from those as well. Because we rely on a multi-data-center Metadata store for the central index of files within Blobstore, we are aware in a very short amount of time whether an image has been written to its original data center; we can route requests there until the Kestrel queues are able to replicate the data.
Blobstore Components

How is the data found?
When an image is requested from Blobstore, we need to determine its location in order to access the data. There are a few approaches to solving this problem, each with its own pros and cons. One such approach is to map or hash each image individually to a given server by some method. This method has a fairly major downside in that it makes managing the movement of images much more complicated. For example, if we were to add or remove a server from Blobstore, we would need to recompute a new location for each individual image affected by the change. This adds operational complexity, as it would necessitate a rather large amount of bookkeeping to perform the data movement.
We instead created a fixed-sized container for individual blobs of data, called a “virtual bucket”. We map images to these containers, and then we map the containers to the individual storage nodes. We keep the total number of virtual buckets unchanged for the entire lifespan of our cluster. In order to determine which virtual bucket a given image is stored in, we perform a simple hash on the image’s unique ID. As long as the number of virtual buckets remains the same, this hashing will remain stable. The advantage of this stability is that we can reason about the movement of data at a much more coarsely grained level than the individual image.
How do we place the data?
When mapping virtual buckets to physical storage nodes, we keep some rules in mind to make sure that we don’t lose data when we lose servers or hard drives. For example, if we were to put all copies of a given image on a single rack of servers, losing that rack would mean that particular image would be unavailable.
If we were to completely mirror the data on a given storage node on another storage node, it would be unlikely that we would ever have unavailable data, as the likelihood of losing both nodes at once is fairly low. However, whenever we were to lose a node, we would only have a single node to source from to re-replicate the data. We would have to recover slowly, so as to not impact the performance of the single remaining node.
If we were to take the opposite approach and allow any server in the cluster to share a range of data on all servers, then we would avoid a bottleneck when recovering lost replicas, as we would essentially be able to read from the entire cluster in order to re-replicate data. However, we would also have a very high likelihood of data loss if we were to lose more than the replication factor of the cluster (two) per data center, as the chance that any two nodes would share some piece of data would be high. So, the optimal approach would be somewhere in the middle: for a given piece of data, there would be a limited number of machines that could share the range of data of its replica - more than one but less than the entire cluster.
We took all of these things into account when we determined the mapping of data to our storage nodes. As a result, we built a library called “libcrunch” which understands the various data placement rules such as rack-awareness, understands how to replicate the data in way that minimizes risk of data loss while also maximizing the throughput of data recovery, and attempts to minimize the amount of data that needs to be moved upon any change in the cluster topology (such as when nodes are added or removed). It also gives us the power to fully map the network topology of our data center, so storage nodes have better data placement and we can take into account rack awareness and placement of replicas across PDU zones and routers.
Keep an eye out for a blog post with more information on libcrunch.
How is the data stored?
Once we know where a given piece of data is located, we need to be able to efficiently store and retrieve it. Because of their relatively high storage density, we are using standard hard drives inside our storage nodes (3.5” 7200 RPM disks). Since this means that disk seeks are very expensive, we attempted to minimize the number of disk seeks per read and write.
We pre-allocate ‘fat’ files on each storage node disk using fallocate(), of around 256MB each. We store each blob of data sequentially within a fat file, along with a small header. The offset and length of the data is then stored in the Metadata store, which uses SSDs internally, as the access pattern for index reads and writes is very well-suited for solid state media. Furthermore, splitting the index from the data saves us from needing to scale out memory on our storage nodes because we don’t need to keep any local indexes in RAM for fast lookups. The only time we end up hitting disk on a storage node is once we already have the fat file location and byte offset for a given piece of data. This means that we can generally guarantee a single disk seek for that read.
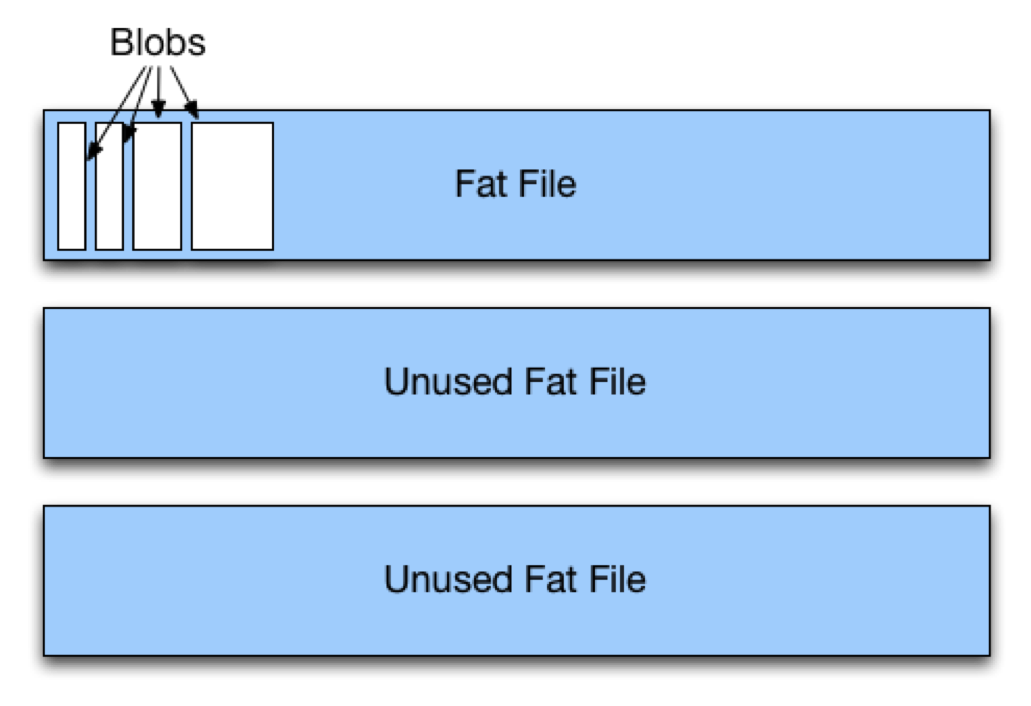
Topology Management
As the number of disks and nodes increases, the rate of failure increases. Capacity needs to be added, disks and nodes need to be replaced after failures, servers need to be moved. To make Blobstore operationally easy we put a lot of time and effort into libcrunch and the tooling associated with making cluster changes.

When a storage node fails, data that was hosted on that node needs to be copied from a surviving replica to restore the correct replication factor. The failed node is marked as unavailable in the cluster topology, and so libcrunch computes a change in the mapping from the virtual buckets to the storage nodes. From this mapping change, the storage nodes are instructed to copy and migrate virtual buckets to new locations.
Zookeeper
Topology and placement rules are stored internally in one of our Zookeeper clusters. The Blob Manager deals with this interaction and it uses this information stored in Zookeeper when an operator makes a change to the system. A topology change can consist of adjusting the replication factor, adding, failing, or removing nodes, as well as adjusting other input parameters for libcrunch.
Replication across Data centers
Kestrel is used for cross data center replication. Because kestrel is a durable queue, we use it to asynchronously replicate our image data across data centers.
Data center-aware Routing
TFE (Twitter Frontend) is one of Twitter’s core components for routing. We wrote a custom plugin for TFE, that extends the default routing rules. Our Metadata store spans multiple data centers, and because the metadata stored per blob is small (a few bytes), we typically replicate this information much faster than the blob data. If a user tries to access a blob that has not been replicated to the nearest data center they are routed to, we look up this metadata information and proxy requests to the nearest data center that has the blob data stored. This gives us the property that if replication gets delayed, we can still route requests to the data center that stored the original blob, serving the user the image at the cost of a little higher latency until it’s replicated to the closer data center.
Future work
We have shipped the first version of blobstore internally. Although blobstore started with photos, we are adding other features and use cases that require blob storage to blobstore. And we are also continuously iterating on it to make it more robust, scalable, and easier to maintain.
Acknowledgments
Blobstore was a group effort. The following folks have contributed to the project: Meher Anand (@meher_anand), Ed Ceaser (@asdf), Harish Doddi (@thinkingkiddo), Chris Goffinet (@lenn0x), Jack Gudenkauf (@_jg), and Sangjin Lee (@sjlee).
Posted by Armond Bigian @armondbigian
Engineering Director, Core Storage & Database Engineering
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.