
Building a complete Tweet index
Tuesday, 18 November 2014
Today, we are pleased to announce that Twitter now indexes every public Tweet since 2006.
Since that first simple Tweet over eight years ago, hundreds of billions of Tweets have captured everyday human experiences and major historical events. Our search engine excelled at surfacing breaking news and events in real time, and our search index infrastructure reflected this strong emphasis on recency. But our long-standing goal has been to let people search through every Tweet ever published.
This new infrastructure enables many use cases, providing comprehensive results for entire TV and sports seasons, conferences (#TEDGlobal), industry discussions (#MobilePayments), places, businesses and long-lived hashtag conversations across topics, such as #JapanEarthquake, #Election2012, #ScotlandDecides, #HongKong, #Ferguson and many more. This change will be rolling out to users over the next few days.
In this post, we describe how we built a search service that efficiently indexes roughly half a trillion documents and serves queries with an average latency of under 100ms.
The most important factors in our design were:
Overview
The system consists four main parts: a batched data aggregation and preprocess pipeline; an inverted index builder; Earlybird shards; and Earlybird roots. Read on for a high-level overview of each component.
Batched data aggregation and preprocessing
The ingestion pipeline for our real-time index processes individual Tweets one at a time. In contrast, the full index uses a batch processing pipeline, where each batch is a day of Tweets. We wanted our offline batch processing jobs to share as much code as possible with our real-time ingestion pipeline, while still remaining efficient.
To do this, we packaged the relevant real-time ingestion code into Pig User-Defined Functions so that we could reuse it in Pig jobs (soon, moving to Scalding), and created a pipeline of Hadoop jobs to aggregate data and preprocess Tweets on Hadoop. The pipeline is shown in this diagram:
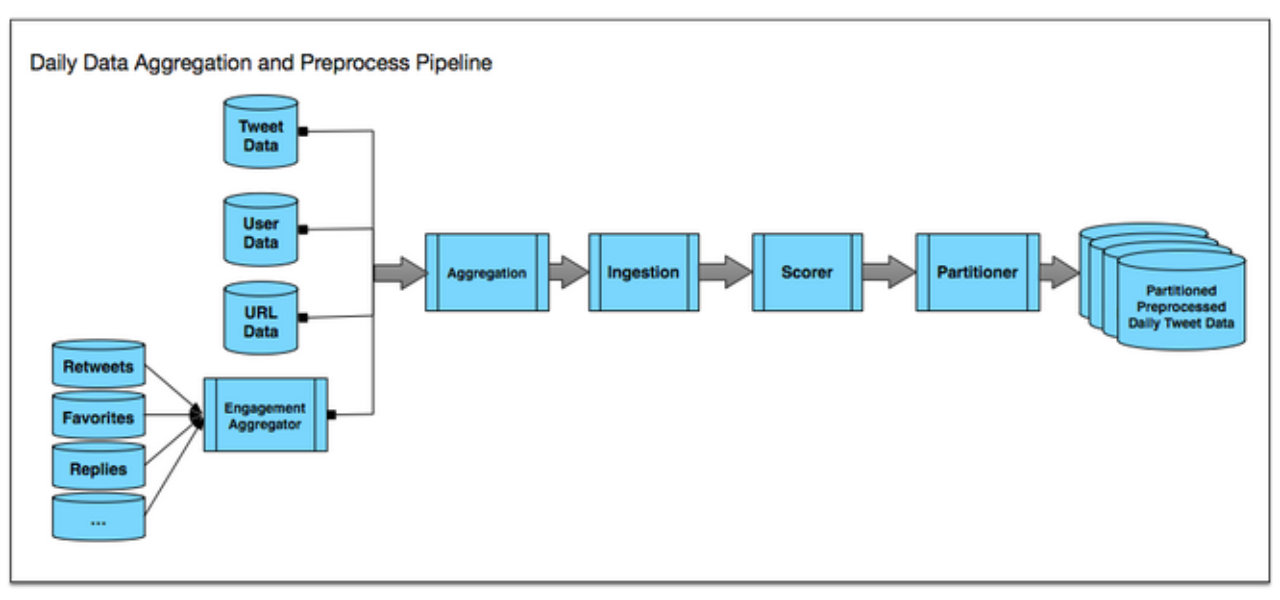 The daily data aggregation and preprocess pipeline consists of these components:
The daily data aggregation and preprocess pipeline consists of these components:
This pipeline was designed to run against a single day of Tweets. We set up the pipeline to run every day to process data incrementally. This setup had two main benefits. It allowed us to incrementally update the index with new data without having to fully rebuild too frequently. And because processing for each day is set up to be fully independent, the pipeline could be massively parallelizable on Hadoop. This allowed us to efficiently rebuild the full index periodically (e.g. to add new indexed fields or change tokenization)
Inverted index building
The daily data aggregation and preprocess job outputs one record per Tweet. That output is already tokenized, but not yet inverted. So our next step was to set up single-threaded, stateless inverted index builders that run on Mesos.
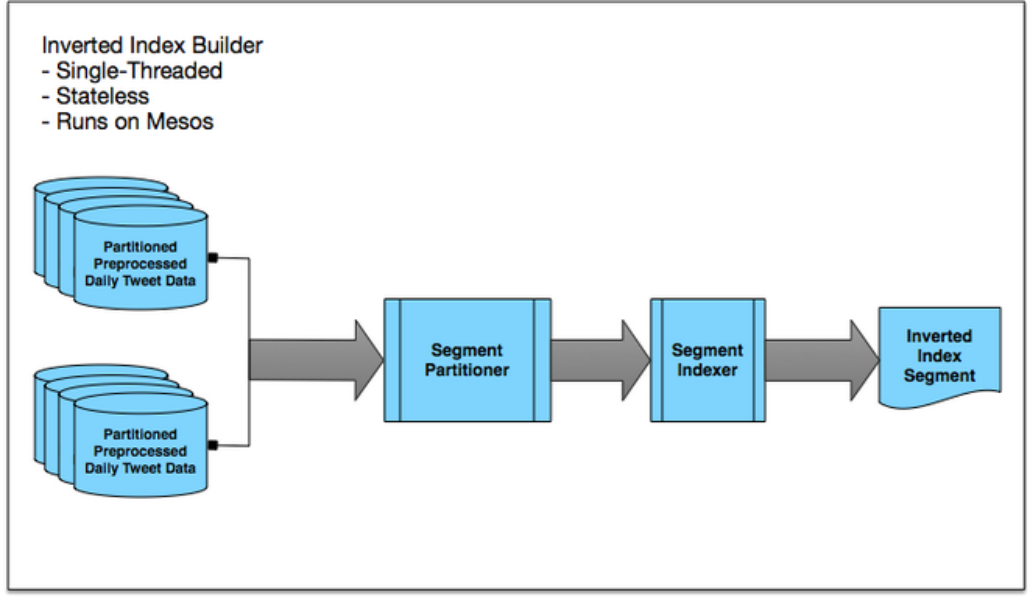
The inverted index builder consists of the following components:
The beauty of these inverted index builders is that they are very simple. They are single-threaded and stateless, and these small builders can be massively parallelized on Mesos (we have launched well over a thousand parallel builders in some cases). These inverted index builders can coordinate with each other by placing locks on ZooKeeper, which ensures that two builders don’t build the same segment. Using this approach, we rebuilt inverted indices for nearly half a trillion Tweets in only about two days (fun fact: our bottleneck is actually the Hadoop namenode).
Earlybirds shards
The inverted index builders produced hundreds of inverted index segments. These segments were then distributed to machines called Earlybirds. Since each Earlybird machine could only serve a small portion of the full Tweet corpus, we had to introduce sharding.
In the past, we distributed segments into different hosts using a hash function. This works well with our real-time index, which remains a constant size over time. However, our full index clusters needed to grow continuously.
With simple hash partitioning, expanding clusters in place involves a non-trivial amount of operational work – data needs to be shuffled around as the number of hash partitions increases. Instead, we created a two-dimensional sharding scheme to distribute index segments onto serving Earlybirds. With this two-dimensional sharding, we can expand our cluster without modifying existing hosts in the cluster:
The sharding is shown in this diagram:
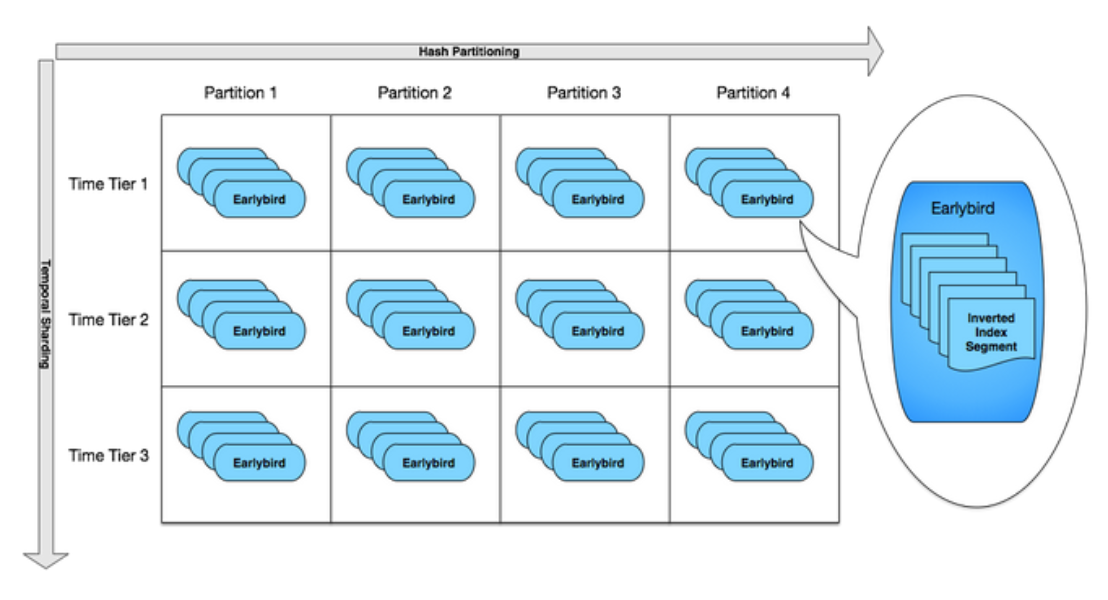
This setup makes cluster expansion simple:
This setup allowed us to avoid adding hash partitions, which is non-trivial if we want to perform data shuffling without taking the cluster offline.
A larger number of Earlybird machines per cluster translates to more operational overhead. We reduced cluster size by:
In order to pack more segments onto each Earlybird, we needed to find a different storage medium. RAM was too expensive. Even worse, our ability to plug large amounts of RAM into each machine would have been physically limited by the number of DIMM slots per machine. SSDs were significantly less expensive ($/terabyte) than RAM. SSDs also provided much higher read/write performance compared to regular spindle disks.
However, SSDs were still orders of magnitude slower than RAM. Switching from RAM to SSD, our Earlybird QPS capacity took a major hit. To increase serving capacity, we made multiple optimizations such as tuning kernel parameters to optimize SSD performance, packing multiple DocValues fields together to reduce SSD random access, loading frequently accessed fields directly in-process and more. These optimizations are not covered in detail in this blog post.
Earlybird roots
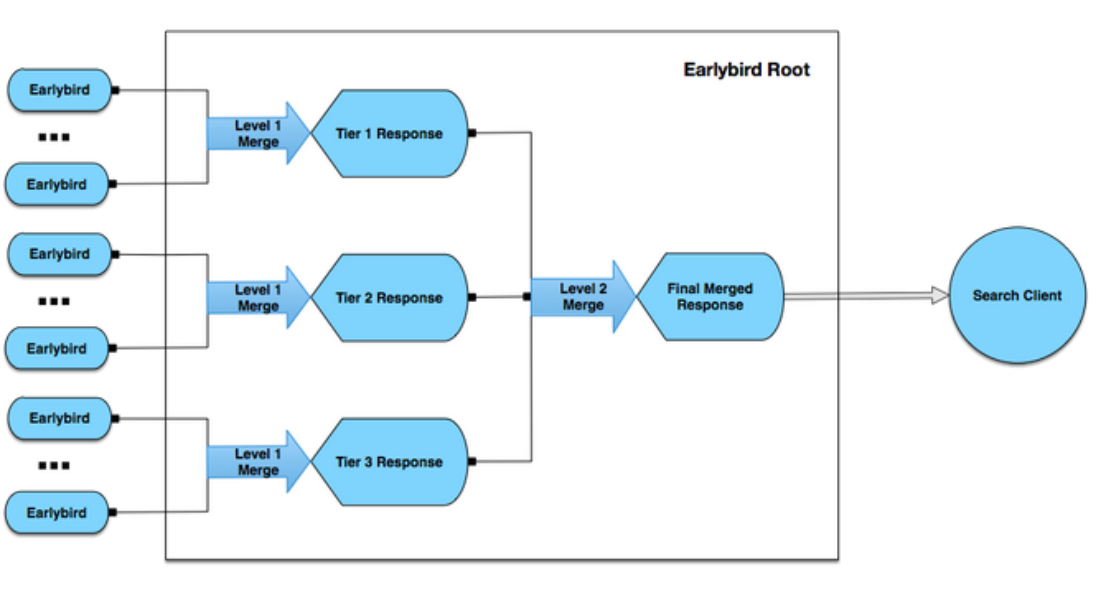
This two-dimensional sharding addressed cluster scaling and expansion. However, we did not want API clients to have to scatter gather from the hash partitions and time tiers in order to serve a single query. To keep the client API simple, we introduced roots to abstract away the internal details of tiering and partitioning in the full index.
The roots perform a two level scatter-gather as shown in the below diagram, merging search results and term statistics histograms. This results in a simple API, and it appears to our clients that they are hitting a single endpoint. In addition, this two level merging setup allows us to perform additional optimizations, such as avoiding forwarding requests to time tiers not relevant to the search query.
Looking ahead
For now, complete results from the full index will appear in the “All” tab of search results on the Twitter web client and Twitter for iOS & Twitter for Android apps. Over time, you’ll see more Tweets from this index appearing in the “Top” tab of search results and in new product experiences powered by this index. Try it out: you can search for the first Tweets about New Years between Dec. 30, 2006 and Jan. 2, 2007.
The full index is a major infrastructure investment and part of ongoing improvements to the search and discovery experience on Twitter. There is still more exciting work ahead, such as optimizations for smart caching. If this project sounds interesting to you, we could use your help – join the flock!
Acknowledgments
The full index project described in this post was led by Yi Zhuang and Paul Burstein. However, it builds on multiple years of related work. Many thanks to the team members that made this project possible.
Contributors: Forrest Bennett, Steve Bezek, Paul Burstein, Michael Busch, Chris Dudte, Keita Fujii, Vibhav Garg, Mila Hardt, Justin Hurley, Aaron Hook, Nik Johnson, Brian Larson, Aaron Lewis, Zhenghua Li, Patrick Lok, Sam Luckenbill, Gilad Mishne, Yatharth Saraf, Jayarama Shenoy, Thomas Snider, Haixin Tie, Owen Vallis, Jane Wang, John Wang, Lei Wang, Tian Wang, Bryce Yan, Jim Youll, Min Zeng, Kevin Zhao, Yi Zhuang
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.