
Strong consistency in Manhattan
Thursday, 17 March 2016
Introduction
To learn more about Manhattan, Twitter’s distributed storage system, a great place to start is our first blog post. While we’ll cover the basics of Manhattan, it’s recommended that you read the post first to understand the bigger picture.
Manhattan is a general-purpose distributed key-value storage system that’s designed for small and medium-sized objects and fast response time. It’s one of the primary data stores at Twitter, serving Tweets, Direct Messages, and advertisements, among others. The primary goals behind building Manhattan were achieving predictability of runtime behavior, stability, and operational simplicity.
There are two main parts to Manhattan:
Coordinators route requests to storage nodes and wait for responses. They do this directly by sending messages to storage nodes, or indirectly by placing request messages in replicated logs and waiting for a callback from any consumer of those logs.
Each key that our customers write gets stored several times for redundancy, and there’s a well-known set of storage nodes where a given piece of data lives. Performance of a storage node is largely dependent on the storage engine used. We have support for several storage engines to fit a variety of use cases.
Each key belongs to a single shard. A shard is responsible for a part of the keyspace. Under normal circumstances, a key always resolves to the same shard, regardless of where that shard is physically placed. We use a topology management service to identify physical locations of each shard. A storage node is typically responsible for hundreds or thousands of shards.
Besides the main components, there is a large ecosystem of supporting services around Manhattan: topology management service, self-service web portal, log management service, metadata service, and many more.
Eventual Consistency
Let’s start with a summary of what eventual consistency is and what are its limitations. Eventually consistent systems in the style of Amazon Dynamo are designed to be fast and highly available during failures, including node failures and network partitions. We’re guaranteed that in the absence of any changes, all copies of data in a distributed database will converge to the same state at some future point. However, this puts the burden of handling temporary inconsistencies on the application logic.
Here are some examples of guarantees that we cannot provide with eventual consistency:
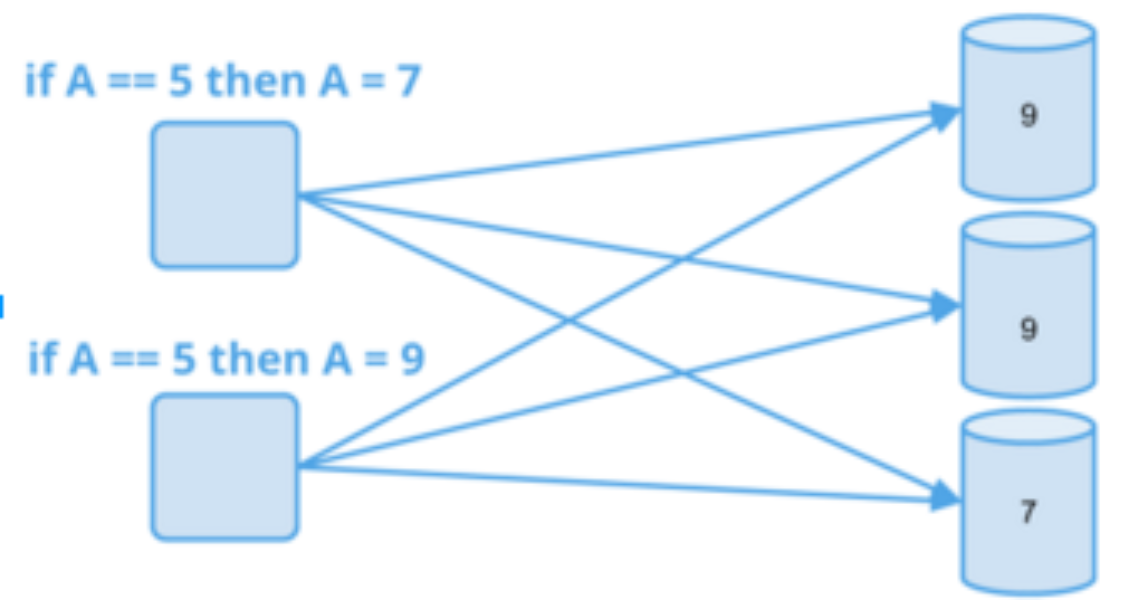
Therefore, while eventually consistent systems have their place in data storage, they don’t cover all of the needs of our customers.
Consistency in Manhattan
To address these requirements and shortcomings, we added stronger consistency guarantees into Manhattan. Our goal was to provide ways to treat keys as single units, no matter how they are distributed geographically. Next, we’ll describe how that works under the hood.
The strongest consistency model that we now support is the sequential ordering of per-object updates. This means that clients can issue writes to individual keys that will take place atomically, and all subsequent reads (globally) will observe the previously written or newer versions of the key, in the same order. For example, suppose the writer writes “X=1” and then “X=2”. If a reader reads X twice, it will receive either “1, 1”, “2, 2” or “1, 2”, but never “2, 1”. In this post, we’ll refer to this concept as “strong consistency” for simplicity.
Not all data needs to be strongly consistent. To understand how consistency applies to some keys and not others, it’s important to understand Manhattan datasets. A dataset is analogous to a RDBMS table: it’s a group of keys that belong to a single use case, such as “staging data for Moments Service” or “production data for notification history”. Datasets provide logical separation of the data and allow services to coexist in a shared environment.
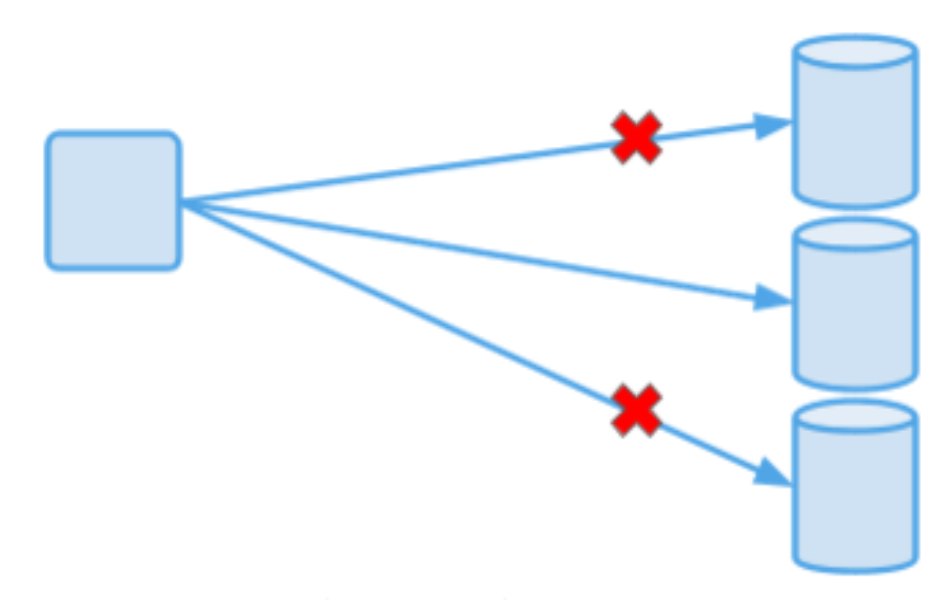
The consistency model is configurable per dataset, which means an application can use multiple consistency models if it uses more than one dataset. As low latency and strong consistency are trade-offs, many of our customers inside the company prefer the flexibility to mix-and-match consistency types. Another useful property is that the reads against strongly consistent datasets can be either eventually consistent or strongly consistent:

In terms of latency numbers, the 99th percentile is typically low tens of milliseconds for local strongly consistent operations (in one data center) and low hundreds of milliseconds for global operations (all data centers are included). The higher latency for global operations is due to latencies traversing large geographical distances. Median latencies are much lower.
Architecture
To explain how keys are updated, we will first explain the key structure. Our keys are hierarchical, and under one top-level key (we call it a “partitioning key”) there can be many sub-keys (we call them “local keys”):
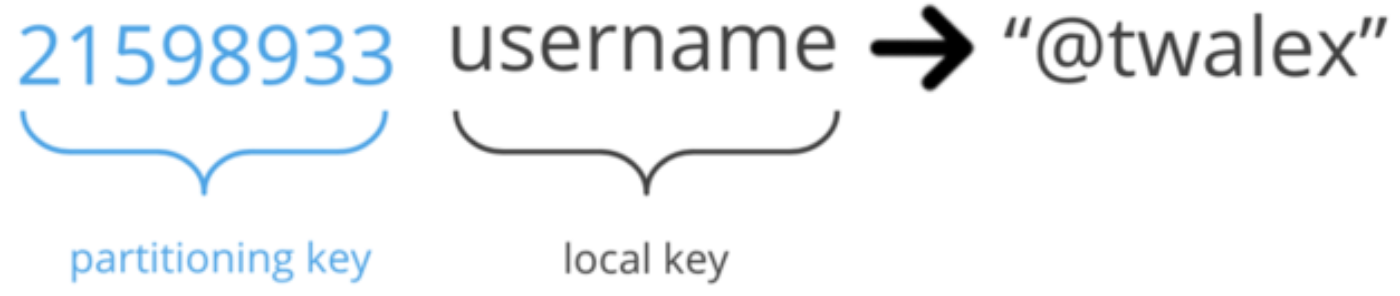
Therefore, a dataset may look like this:

When we talk about atomically updating a single key, we’re actually talking about a partitioning key. In the example above, we can atomically update all of the keys under 437698567.
We considered two options for the scope of our strong consistency support. We could have done either full distributed transactions (where operations can span any number of keys in our system) or addressed a simpler scenario (where strong consistency applies per key). After talking to our internal customers and reviewing the use cases, we decided that starting with the latter model satisfied a majority of use cases. Because each key belongs to a single shard, we don’t have to pay a performance penalty of coordinating a multi-key distributed transaction.
In our design, to provide strong order of updates for each key, all strongly consistent operations go through a per-shard log. A typical system has tens of thousands of shards and a large number of logs (we support multiplexing multiple shards on the same log). Each shard is independent from others, so when Twitter engineers design their applications, they must choose their keys in a way that strongly consistent operations are confined to individual partitioning keys and don’t span multiple keys.
We rely on DistributedLog, a replicated log service built by Twitter. Manhattan coordinators map keys to shards, create messages that represent requested operations and submit them to per-shard logs. Each such message is a record in the log. Each storage node shares responsibility for a given shard and subscribes to that shard’s log, as shown in the diagram below:
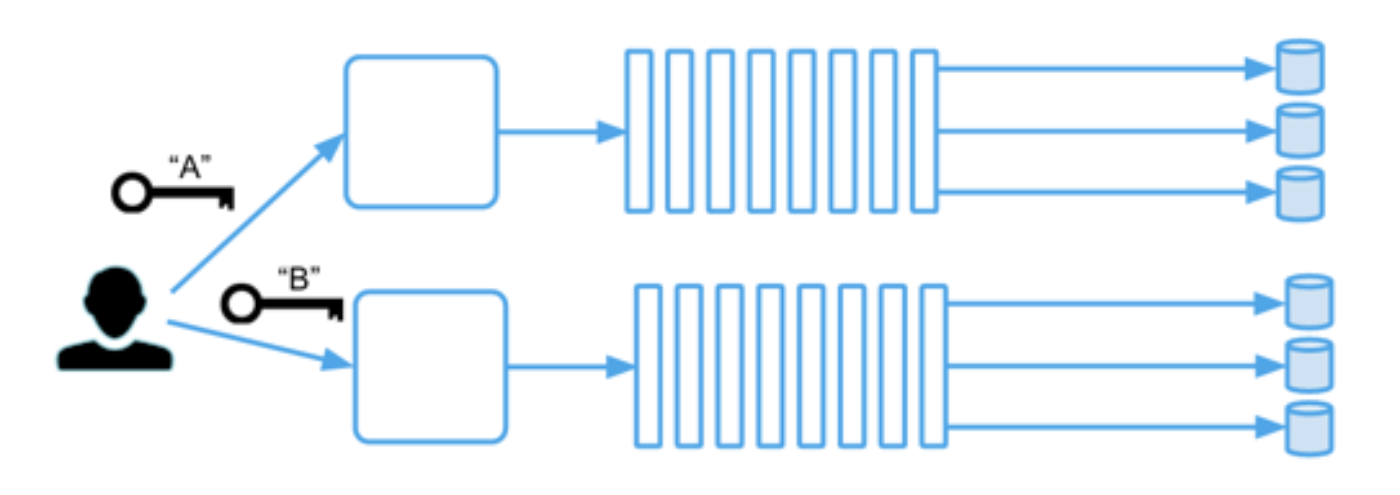
Each storage node subscribes to many logs. This allows us to achieve a high degree of parallelism and makes the unit of failure smaller. Each storage node consumes its logs in parallel. Within each log, however, all operations have to be applied sequentially to preserve the order. Effectively, all storage nodes maintain a state machine per shard, and after applying N operations, each shard’s state machine will be in the exact same state on all storage nodes.
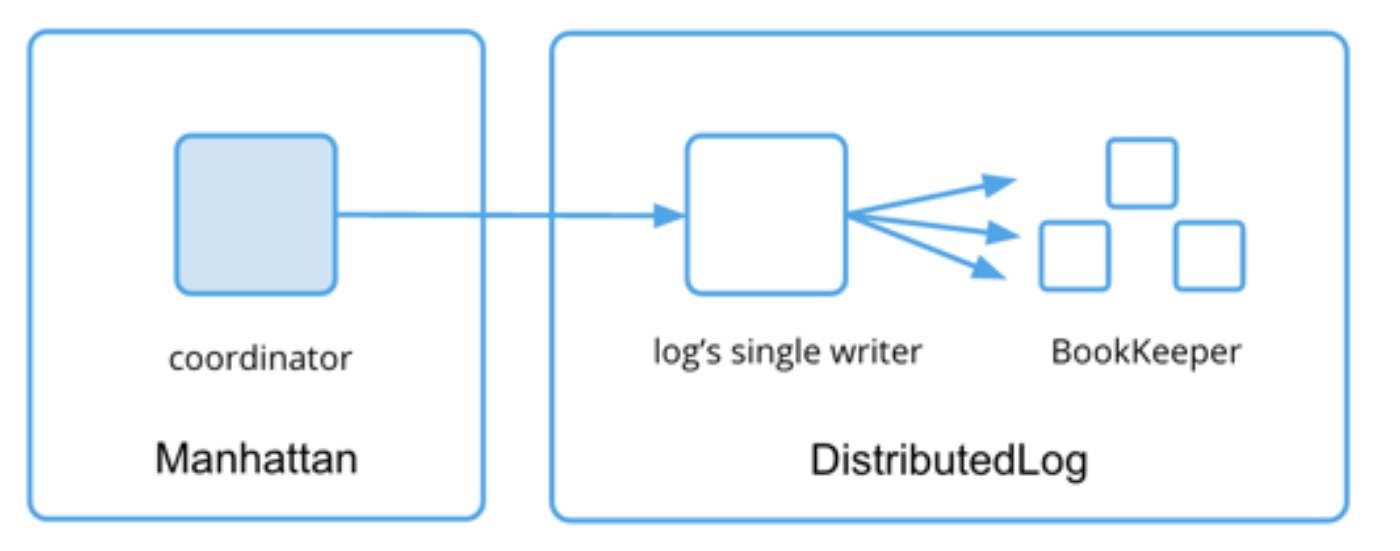
In DistributedLog, each log has an elected single writer that accepts and sequences writes. This allows us to establish consensus on the order of operations. Operations on any two distinct keys are likely going to go to different logs and therefore have different writers, which mitigates the global impact from a single writer failure. There’s a failover mechanism based on ZooKeeper for when a writer fails, — for example, during network partitions, hardware failures, or planned maintenances.
Workflow
Every client request has to go through a Manhattan coordinator. A coordinator will group keys in each request by shard, and write the messages corresponding to per-shard operations into corresponding logs (e.g., “read key A” for shard 2, “check-and-set key B from 5 to 9” for shard 8). The coordinator also places its own callback address into the message to inform storage nodes about where to respond. The responses are necessary to provide results for operations like check-and-set, increment and read. For strongly consistent writes, we only need to ensure that the operation is written to the log.
Next, storage nodes subscribing to particular logs will consume these messages, execute the operations one at a time, and respond back to the coordinator. When consuming logs, storage nodes always keep the position of the current operation on the log. They also have to atomically write that position to disk storage with the results of the corresponding operation. Otherwise, consistency could be violated during crashes, because some operations could be applied twice or not applied at all.
These per-log positions are also useful to check whether storage nodes that consume a given log are in sync with each other. When they respond to a coordinator, the coordinator can check whether the positions for a given operation match. If they don’t, this is an indication of data corruption having happened to this operation or its predecessor. Then we can find when the positions matched in the past and determine when a corruption happened.
Truncating the logs
Logs provide a nice guarantee that no matter how long a storage node has been down, it can catch up with the latest state by consuming all of the operations since the last-saved position. However, this approach poses a problem: do we have to keep all log entries forever, or can we safely remove some of them?
Let’s say we make coordinators responsible for truncation. Coordinators cannot truncate unless the information about log progress is sent back to them periodically. That could result in many messages being sent. Also, if coordinators had to keep track of progress and truncations of all logs, how can we avoid many coordinators truncating the same log at the same time? If instead we make individual storage nodes do the truncations, how do we distribute the information about positions of other nodes that subscribe to the same logs?
To safely truncate, all readers need to agree on last-saved position. This is a distributed consensus problem that we can also solve with a log. We opted for a simple solution that didn’t require any additional communication channels: every node periodically publishes information about its own position in a log into that log. Eventually, every storage node learns the positions of others in the logs. If the position of a given node on some log is unknown, we don’t truncate that log. This can happen during temporary failures. Otherwise, we select the earliest position and truncate up to it. The following diagram shows node 3 publishing its own position to the log.
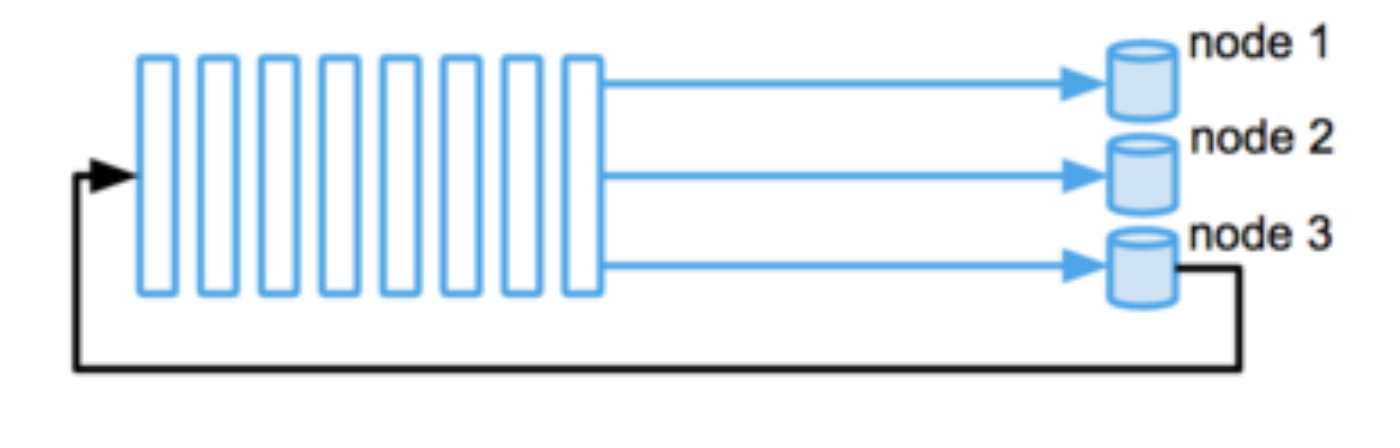
When a storage node replaces another storage node completely (for example, due to hardware failures), we update the topology membership accordingly and no longer wait for the old node to report its truncation position. This allows other storage nodes to proceed with truncation.
Time in strongly consistent systems
Manhattan supports key expiration: a key can have a limited lifespan and will be erased after a configured time-to-live, or TTL. Our customers use TTLs to implement application-level expiration logic or store temporary data.
Implementing expiring keys in an eventually consistent model means guaranteeing that at some point in time after the expiration time, the key will indeed expire. It may not happen atomically: different storage nodes may respond with different results until they reconcile on a decision. For example, a small difference in local clocks may result in such inconsistencies.
However, in case of strongly consistent systems, we have to provide strong ordering guarantees for key expirations. A key expiration needs to be consistent across all nodes, so determinism is important. One source of non-determinism is time. If storage nodes disagree about the current time, they’ll disagree about whether a key has expired or not, and therefore make different decisions about whether a subsequent CAS operation succeeded or failed.
Here’s an example of ordering of regular operations A and B and an expiration of key X on different storage nodes of the same data. The timeline below shows three possible ways these events can be ordered. Note that we don’t care about the absolute time of each operation, as long as the order is maintained. In the following diagram, the bottom timeline is inconsistent with the first two (key X expires after B):
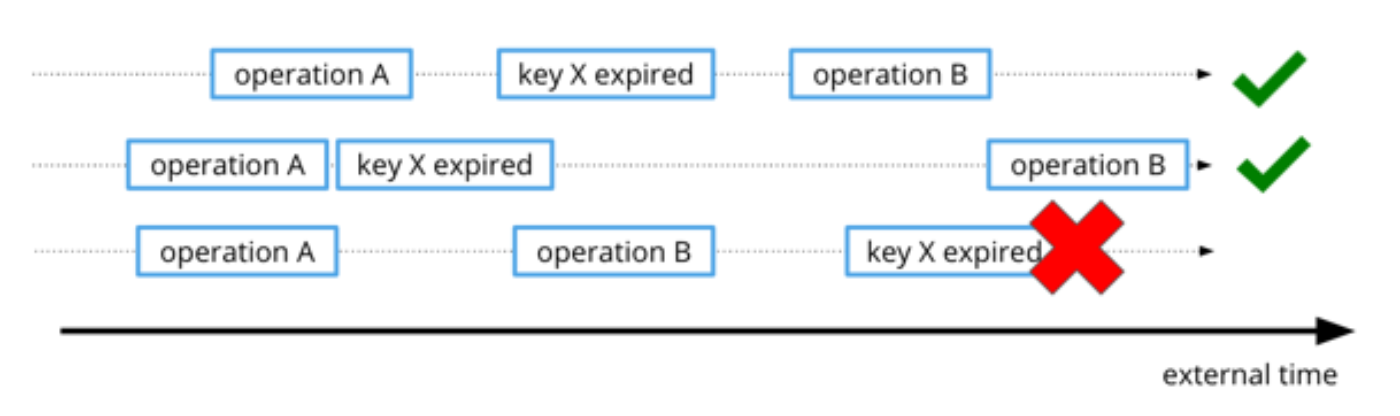
To guarantee correctness, we need all operations for any given key to have monotonically increasing timestamps. We could have kept track of time per key, per shard, or globally for the entire cluster. Since our model already uses logs to sequence all per-shard operations, we decided to keep track of time per shard and use logs as the source of truth for time. When a record is submitted to DistributedLog, the log’s single writer assigns it a timestamp.
The single writer ensures that the timestamp is monotonically increasing, and therefore will be correct from the external point of view. To provide this guarantee, it ensures that every new value of the timestamp is equal or higher than the previous one. Upon ownership changes of log writers, the timestamp used by the new owner is always greater or equal to the timestamp of the last successful record written by the old owner.
Now that the storage nodes have consensus on current time, they also agree on when each key expires. Note that they don’t need to immediately delete expired keys. For example, if a given key it set to expire at time T, and a strongly consistent read operation comes from the log with the exact timestamp T+1, we can filter out the expired key from results.
Comprehensive rate limiting
As a multi-tenant database, Manhattan needs to provide high quality of service to each customer. A client can affect latencies of all operations on a shard by overwhelming the log with repeated operations for a hot key. Due to having a single log per shard, a hot key can affect latencies of all operations in the log by overwhelming the log with repeated operations.
In an eventually consistent model, this can be mitigated by having the storage node arbitrarily skip records when under high load. In strongly consistent model, this is not possible: storage nodes cannot arbitrarily skip records under high load unless they achieve consensus on which records get skipped.
We introduced rate limiting to protect the shards against this scenario. Since our clusters are multi-tenant, we rate-limit by client. We will talk more about this and other types of rate limiting that we’re using in our next post.
Summary
We discussed our solution to adding strong guarantees to an eventually consistent system. Over the last year, we started off with a few initial internal customers, and later opened it up to all of Twitter Engineering. Our customers include the URL shortener, authentication service and profile service. Currently, it takes a few minutes to provision a strongly consistent dataset at Twitter.
Readers may also be interested in exploring Datomic, which followed a very different approach. Datomic added transactions as a layer on top of an eventually consistent data store, but without modifying the underlying store. We also recommend VoltDB’s whitepaper on distributed transactions at scale.
Team
We would like to thank Peter Schuller, Melvin Wang, Robin Dhamankar, Bin Zhang, Sijie Guo, Boaz Avital, David Helder, Hareesha Tamatam, Istvan Marko, Jerric Gao, Johan Harjono, Karthik Katooru, Kunal Naik, Leigh Stewart, Pascal Borghino, Ravi Sharma, Spencer Fang, Sree Kuchibhotla, Sumeet Lahorani, Tugrul Bingol, Tyler Bulut, Unmesh Jagtap, Vishnu Challam, Yalei Wang for their contributions to the project.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.