Infrastructure
#ExpandTheEdge: Making Twitter Faster
By
and
Monday, 16 September 2019
Every day millions of users request content from Twitter services. Twitter’s edge infrastructure handles millions of requests per second to deliver this content securely, reliably, and as quickly as possible to users all over the world. This blog post introduces Twitter’s expanding edge network, our Google Points of Presence (PoPs), and the Control Tower: Twitter’s Traffic Mapping Service. Together, this infrastructure helps improve reliability, survive outages, and reduce latency by intelligently connecting Twitter clients to Twitter content.
In many locations, latency is too high for users to consistently access their Twitter content.
To meaningfully address this problem, we need to understand why and where latency is so high. Our approach is to classify where each millisecond is spent in each request. For example, we look at time spent establishing connections, transmitting bytes, and generating the response in our backend among other things. We then group requests according to their position in the latency histogram.
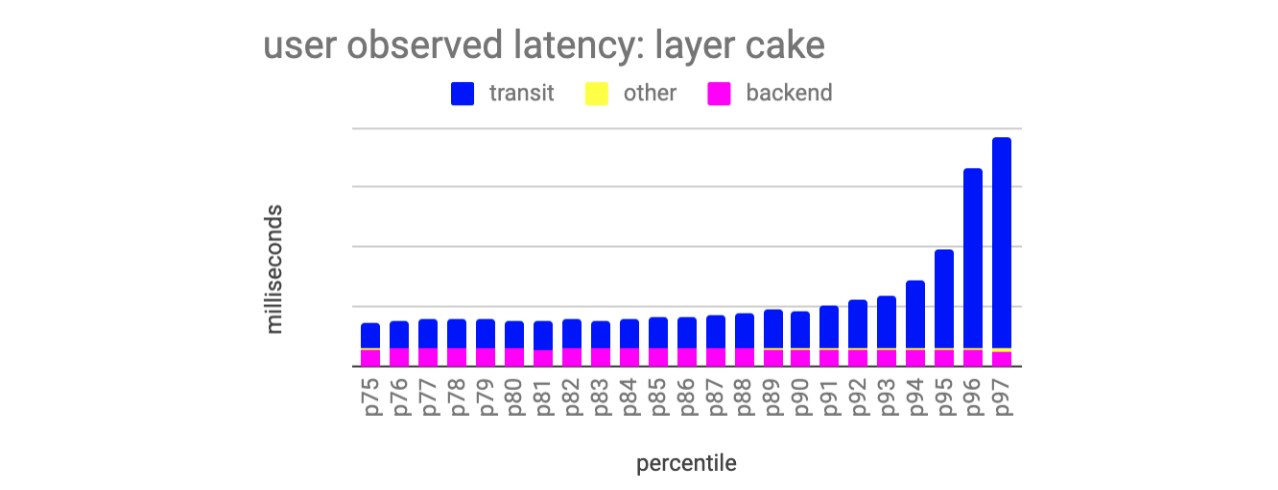
We have visualized this data as a “layer cake” as seen in Figure 1. For simplicity we consolidated all layers into three components: “backend” (time spent in our data centers processing the request), “transit” (time spent transmitting data to and from the client), and “other” (all other time spent in the request).
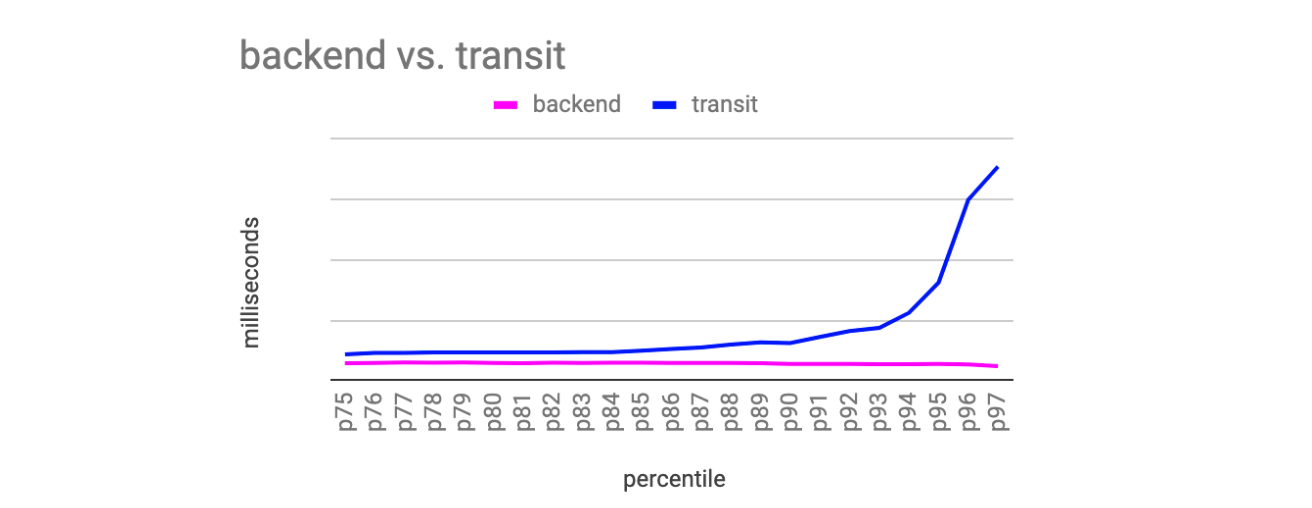
What we found surprised us — as demonstrated in Figure 2, our backend service latency stays flat as we move through the latency histogram. In other words, the backend service’s latency histogram is evenly distributed throughout each percentile in the user-observed latency histogram. Conversely, time spent transmitting and receiving data dominates the layer cake as we move up to higher percentiles. This pattern holds across a variety of devices, applications, and geographic locations.
The implications here are clear to us. To meaningfully improve latency for many requests, we need to improve time spent transmitting data to and from the client.
To reduce time spent transmitting data we found two primary focus areas: reduce the number of round trips and reduce the Round Trip Time (RTT). On the traffic/networking side we have worked on reducing RTT by focusing on the edge. We have added more edge locations to reduce the distance between our users and our network and also steer clients to a specific edge to optimize RTT.
Twitter’s edge network consists of many Points of Presence (PoPs) connected to our global backbone and data centers. Our edge is a hybrid of both Twitter operated PoPs and public cloud provider PoPs. For users far from our data centers, connecting to PoPs instead of our data centers can greatly reduce RTT and increase throughput.
We have built two kinds of Twitter PoPs. A “network only” PoP runs OSI Layer 3 infrastructure services (e.g., routers and switches) and is responsible for getting packets onto and off of our backbone as well as transiting inter-region Twitter traffic. Other Twitter PoPs also run Twitter Front End services (known as “TPoPs”). TPoPs include our network infrastructure and also securely terminate user HTTPS connections and proxy requests to our data center origins.
We have also expanded our edge footprint by utilizing the public cloud. Specifically, we use Google Cloud as either Layer 4 (TCP proxy) or Layer 7 (HTTPS proxy) PoP edges. We refer to these locations as GPoPs (see Figure 6).
GPoPs allow us to quickly bring our edge closer to users in regions where we have not built our own PoPs. They also provide increased redundancy and elasticity on demand to our edge network.
Because our service infrastructure is modular, we can extend our edge with other cloud providers based on performance measurements and other metrics.
Transport Layer Security (TLS) is essential for user privacy and security, and is always required to communicate with the Twitter API. That requirement doesn’t change when we use external providers as an edge network. For this reason, TLS termination done by a cloud provider for Control Tower always uses a hostname and TLS certificate uniquely associated with that provider.
Having many edge options is not enough — we also need a way to map a user’s request to the “best” (fastest and most reliable) edge for the specific request.
Initially, for API requests, we pointed the domain name api.twitter.com to a set of globally anycasted IP addresses advertised from all of our TPoP and data center locations. We then relied on the internet to route traffic to the best edge location. 😬😬😬
As many industry peers have also discovered, global anycast is a great solution for making a service generally available but is not ideal for performance. In practice, we observe that using anycast IP addresses frequently routes user traffic suboptimally, inconsistently, and sometimes takes a detour around the world.
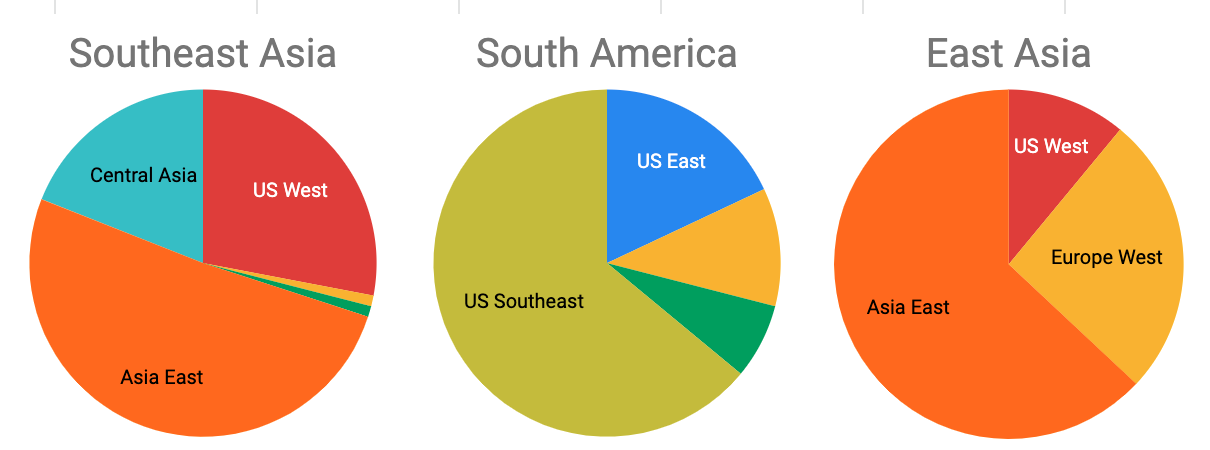
For example, in Figure 3, we’ve broken down a day’s worth of requests in three countries by which PoP region serviced the request. All requests were routed to the serving region by anycast IP. The results do not seem logical — for example, more than 25% of requests from a country in Southeast Asia on this day are routed to US edges — even though we have multiple PoPs geographically close to this country!
At scale, Twitter has little ability to control how Internet Service Providers (ISPs) route packets to our edge. Service providers make routing decisions based on metrics like number of hops, RTT to destination, the monetary cost they will incur, or plain-old heuristics. None of these are optimized for time to retrieve request-specific content.
Application-specific concerns such as content size/chunking, likelihood of content being in a cache, necessary throughput, distance from the edge location to the requested content, and choice of network protocol (for example, QUIC-over-UDP versus HTTP/2-over-TCP) drastically influence the time to deliver content. With these application-specific concerns, it is infeasible for the internet at large to optimize routing decisions for Twitter-specific requests.
The Control Tower is Twitter’s traffic mapping service. Much like a navigation system tells a user the best way to reach their destination, the Control Tower tells Twitter clients the best way to reach their content.
Since we cannot change how the internet routes packets from a client’s network to Twitter, we instead measure different options and steer our users to the one that delivers the best experience for them.
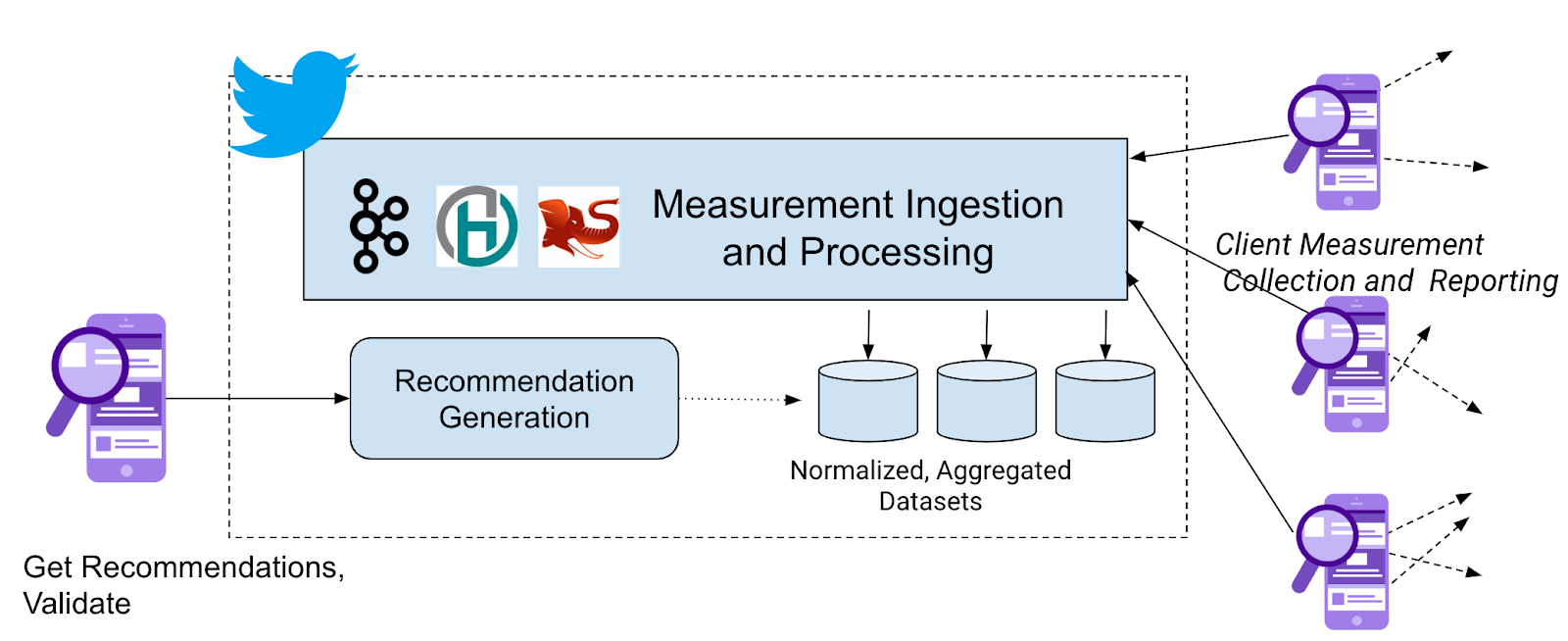
To do so, we use a technique called real user monitoring (RUM). We have set up nearly 100 Virtual IPs (VIPs) representing various combinations of connection termination and routing options throughout the internet. Then, based on measurements from our clients, we apply various ranking techniques to recommend different VIPs to individual clients.
We observe that many factors come into play when routing data from an ISP to Twitter and back. For example, VIP announcement strategy (global anycast, regional anycast, unicast), the preference of one transit provider over another, using different internet exchanges, or choosing to carry traffic on Twitter’s backbone versus offloading this to a public cloud provider’s backbone.
To find the optimal route for a user, we have set up nearly 100 unique VIPs representing different permutations of announcement, transit, peering, and protocol options.
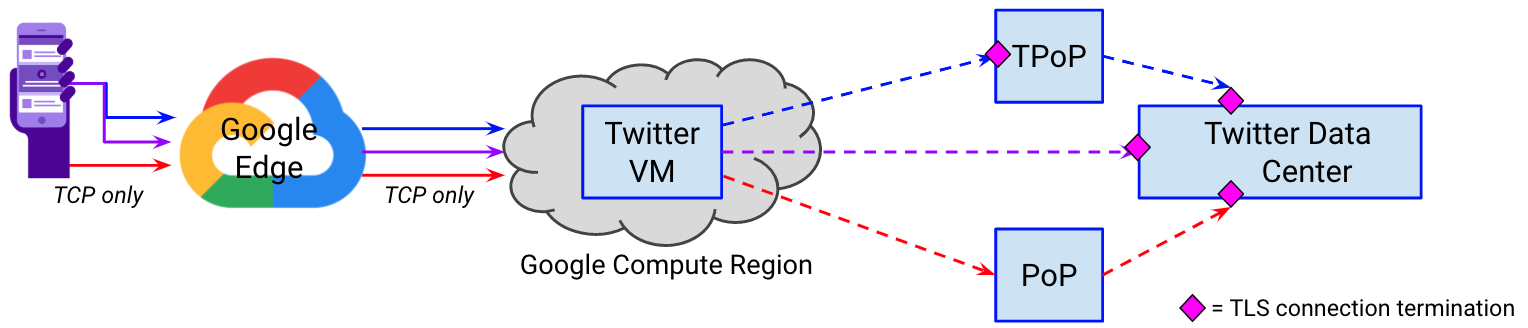
As an example, In Figure 4, we show three of our Layer 4 GPoP VIP configurations. These three are all globally anycasted, terminate TCP in Google’s edge, and are routed to a Twitter Virtual Machine (VM) running in GCP. However, based on the VIP, we proxy the request to either a Twitter network-only PoP, a TPoP, or directly to our data center.
When choosing the best VIP for a specific user’s network, we need measurements from the perspective of that network or similar networks. To do so, we have clients periodically send synthetic requests to retrieve a tiny (10 byte) payload from our data centers through a subset of the available VIPs. Our clients then send the raw measurements back to a Kafka-based data processing pipeline.
Then, using frameworks such as Apache Heron and Scalding, we apply various aggregation and normalization techniques to calculate core statistics such as mean, stddev, and p95. We group measurements by service providers, IP subnets, or similar networks/subnets. We also normalize by removing outliers, removing connection establishment time, and filtering out measurements with clock skew.
As depicted in Figure 5, using these measurements, we build multiple datasets — for example, real time, hourly, daily -— and apply different ranking algorithms to choose the best VIP (or VIPs) at a given time. Some algorithms are rule-based while others use machine learning algorithms to predict the best choice for our clients.
Typically, we run multiple A/B experiments comparing different ranking algorithms or techniques. The most successful get promoted to our default configuration.
On the client side, we receive recommendations from the Control Tower. When we first started experimenting with the Control Tower, the server would provide settings that clients would apply without any additional validation. This was a mistake. Sometimes, data for a group of clients (for example in the same IP subnet) may not actually be applicable to all clients in that group. Additionally, users can quickly switch networks — for example when moving between cellular and Wi-Fi networks or on a train during a daily commute.
To remedy this, the server now sends recommendations which the client validates before accepting them. Client-side validations involve sending synthetic requests to validate that a host/VIP is healthy and can also include selecting the best performing host out of a set of predicted better hosts.
Lastly, and perhaps most importantly, our client is responsible for detecting and handling failures in our recommended routes, falling back to known-good anycast routes. Any individual VIP can go offline (unicast location goes down, public cloud provider outage, internet exchange configuration error, etc). If our client detects problems with non-anycast VIPs, it will default back to our global anycast IP.
In practice, this functionality has proven critical and has allowed our clients to transparently work around outages. We have documented several instances where an incident that would have caused degraded performance or an outage was automatically mitigated by Control Tower.
We have found that the Control Tower system reduces latency and makes Twitter available to more people across the world.
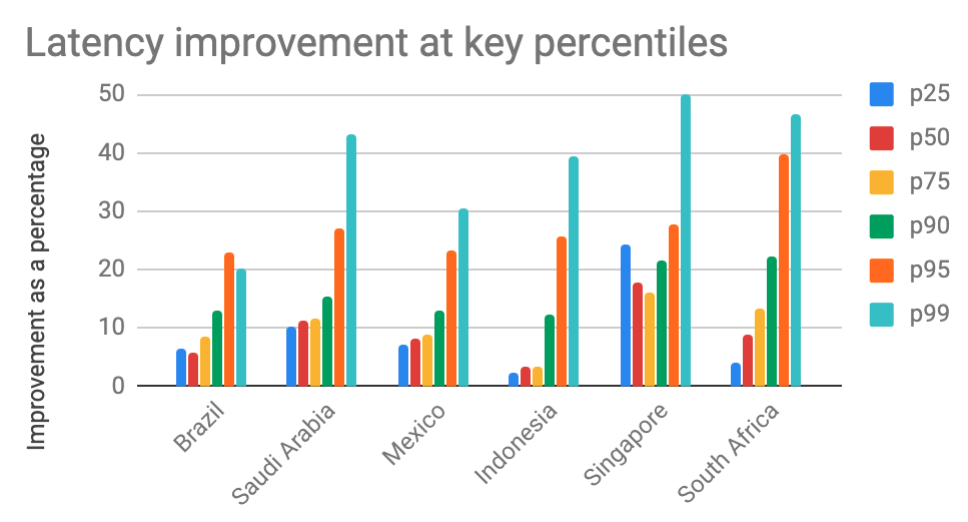
Figure 6 shows mobile client latency of “refresh Home timeline” requests. This shows a comparison between requests sent to our anycast VIP and those sent to control tower recommended VIPs as a percentage. Countries in this graph receive recommendations between 10-25% of the time.
We have found that our recommendations are typically stable over time (days or weeks). However, nearly every day something happens in the internet which will temporarily change the best route for a set of users to Twitter.
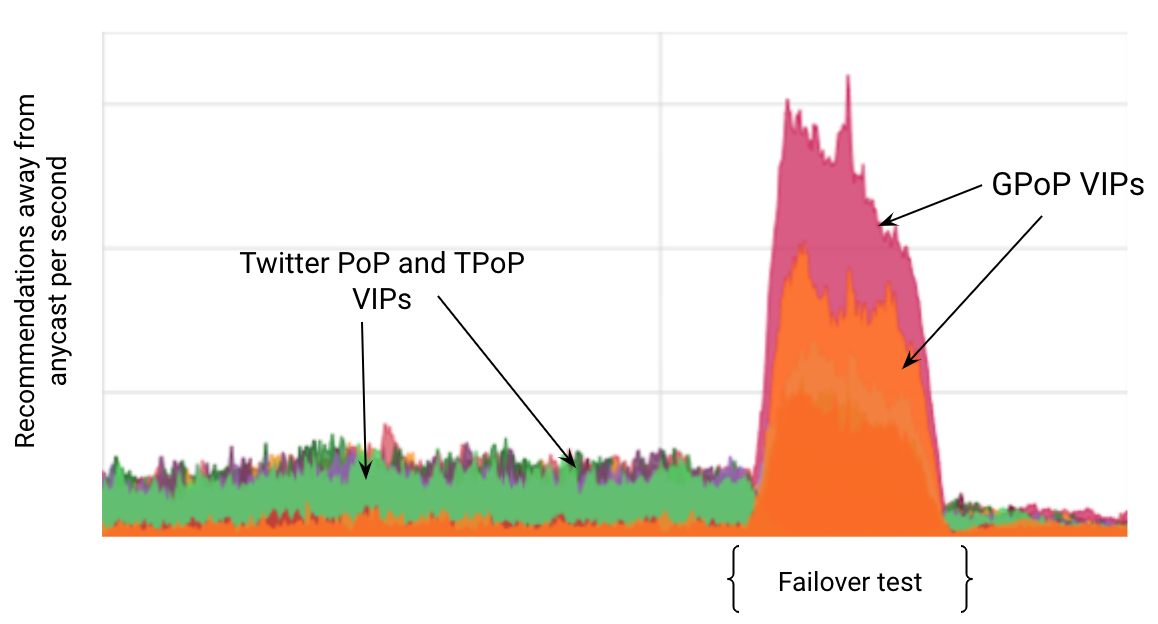
Figure 7 shows the Control Tower dynamically changing recommendations for users in Japan in real time. The large spike in this graph reflects a regular test whereby TPoPs that typically send traffic to Twitter’s US West region, instead send to our US East region. The figure shows a low rate of recommendations (to TPoPs and Layer 3 PoPs) before the test and a much higher rate of recommendations (to GPoP Layer 4 VIPs) during the test.
These results pleasantly surprised us! We expected recommendations to remain stable given the test did not change our edge network or end-user connections.
Though latency is certainly improving, we still have a long way to go to make Twitter fast and reliable for all users worldwide.
Moving forward, we’re working on making our edge and traffic mapping even smarter. We’re investigating improving recommendations in networks with fewer users, working with more public cloud providers, onboarding new types of content such as large objects and cached content, providing default recommendations via DNS, directing web clients to edges via alt-svc, supporting multiple protocols (QUIC, IPv6, etc), and more.
We’re hiring! In addition to traffic mapping and performance, the Traffic team at Twitter also works on the software and services that run in our edge locations and route throughout our Remote Procedure Call (RPC) tree. Come check out careers.twitter.com.
We’d like to thank all the engineers from Clients, Networking, Traffic, Information Security, and Data Science for their assistance, and thank you to engineering leadership and legal for your support. Thanks to our partners at Google for their support building and securing our GPoPs.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.