MoPub, a Twitter company, provides monetization solutions for mobile app publishers and developers around the globe. Our flexible network mediation solution, leading mobile programmatic exchange, and years of expertise in mobile app advertising means publishers trust us to help them maximize their ad revenue and control their user experience.
MoPub operates at a massive scale — we have over 1.7 billion monthly unique devices, 1T+ trillion monthly ad requests, 52,000+ apps, and 180+ demand side partners on our platform. Our customers, partners, and internal teams depend on fast, easy access to our data to answer business questions, troubleshoot issues and optimize revenue. The customer base of our analytics system is broad — customers, sales, support, product management, analysts, and data scientists all log into the platform every day.
To serve these customers, MoPub recently launched a new solution called MoPub Analytics. MoPub Analytics customers pose questions, generate answers from the data, and use those answers to generate more questions. For example, a MoPub publisher account manager might notice that a publisher is generating 20% more revenue this week compared to last week. There are many possible causes for this revenue, and discovering the root cause requires diving into the data. Did a new advertiser start spending on this app? Is the additional revenue up across the board or is it limited to a few demand sources or apps? Is there a new ad format that is driving the revenue? Is it country specific? Is this a seasonal trend that we expect or is it different from what happened last year?
Figuring out the root cause requires users to interactively slice and dice the data across many different time slices, dimensions, and metrics. Queries on MoPub Analytics return in seconds. This enables us to grow our business and delight our customers.
We designed MoPub Analytics to satisfy these key goals:
- Store important data for 13 months to enable year-over-year comparisons.
- Enable fast (seconds) ad-hoc queries over many dimensions and metrics over long periods of time (30+ days).
- Provide an intuitive and easy-to-use UI for both technical and non-technical users.
MoPub Data by the Numbers
To give a better sense of our scale, here are some raw numbers. Every day, MoPub runs over 30 billion ad requests which generate over 150 terabytes of raw logs. These raw logs describe the ads we served, the demand side platforms or networks who bid or filled the ads, and any additional funnel metrics like impressions or clicks that were generated by that ad request.
We take these logs and then aggregate them by dimensions and metrics. Time is an important primary key for MoPub Analytics, but other dimensions are not ranked in a specific order. One example: aggregation rolls up our raw logs across 80 dimensions and 25 metrics. After aggregation we ingest over 9 billion rows into our analytics engine per day.
MoPub Analytics Query Patterns
There are a few high-level groups of queries that users run on MoPub Analytics. A large fraction of the queries filter on a certain dimension and then look at metrics broken down by dimensions. A second common query pattern is to look at time over time trends across all available metrics and dimensions to inform business health, drive OKRs (objectives and key results), and support projections. A small percentage of queries are large group-by queries where users download high cardinality data across months of data.
Users most commonly look at data that is less than 30 days old. When they query data older than 30 days, they’re often doing it to understand long-term trends by looking at data quarter-over-quarter, quarter-to-date or year-over-year.
Why Druid?
We chose Druid and Imply for the foundation of MoPub Analytics.
Apache Druid (incubating) provides a set of capabilities that borrow from OLAP, timeseries, and search systems. It can achieve low latency (seconds) for queries at the expense of some query flexibility.
Imply provides a designed-for-Druid UI (Imply Pivot) as well as Imply Clarity, a tool for performance management. The team at Imply are Druid experts and provide best practices on Druid and Imply cluster design. We have also partnered with Imply to deliver additional Pivot UI functionality including alerting users when data hits designated thresholds, email reporting, and UX improvements around slicing and dicing data.
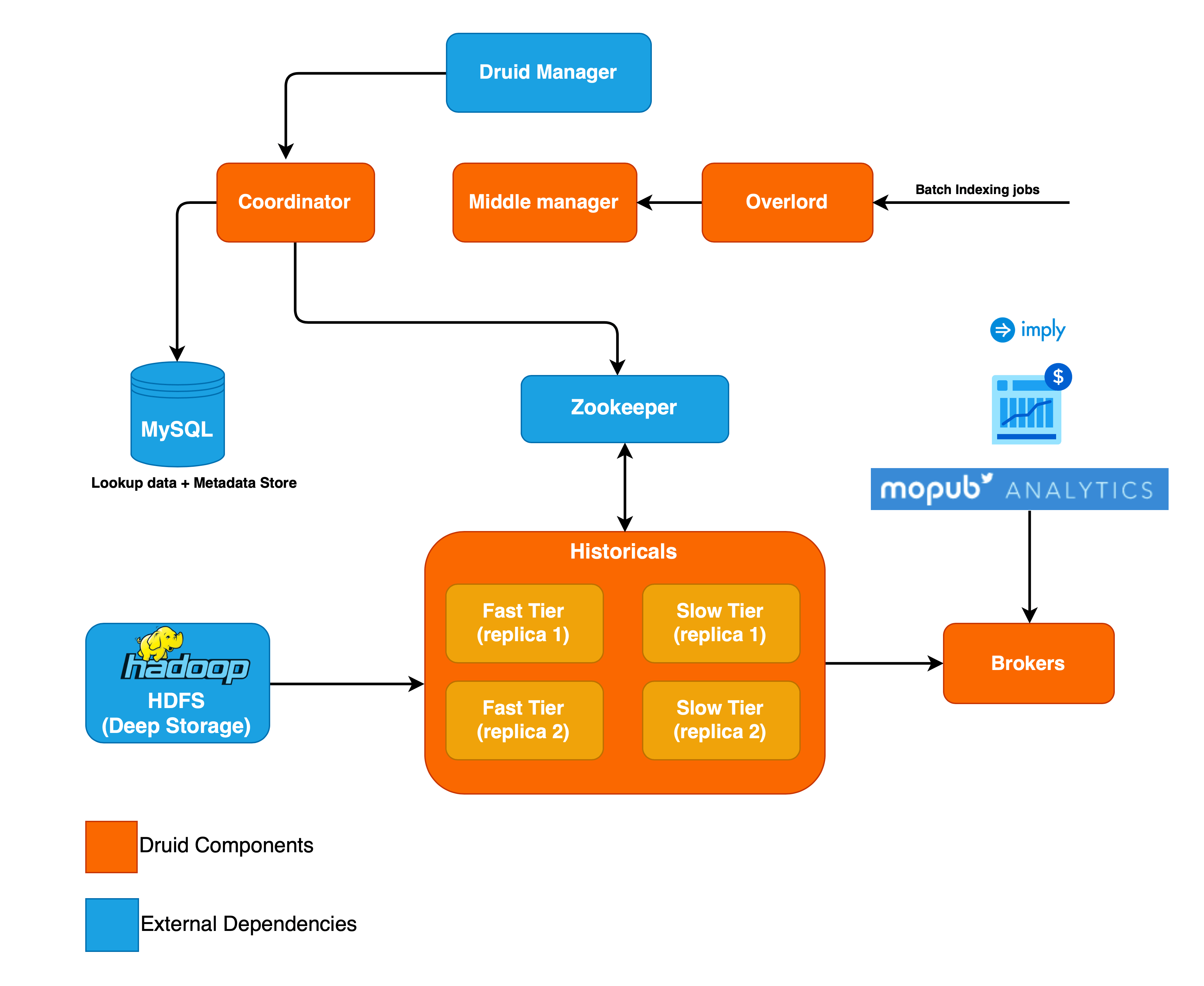
Building out Druid at Twitter
Druid has a microservice-like (multi-process) architecture with separate processes for querying, ingesting, and coordinating data. MoPub’s Druid cluster runs as a distributed system and we use Twitter’s Aurora Mesos cluster to schedule and run jobs. Hadoop is used to process our raw logs, aggregate them, and index into Druid.
When launching a new Druid cluster, one design decision you must make is the quantity and type of hardware to use for the cluster. Druid provides low-latency queries via optimized data structures that are stored in-memory when possible. A higher disk-to-memory ratio can reduce the cost of the cluster at the expense of query performance if the queries run on the cluster trigger disk I/O via paging.
To balance cost and performance we segment our cluster by time and choose different memory and disk ratios for different time periods. Druid supports dataset segmentation by time through the concept of a tier. A tier is a set of machines that are configured to load data from a certain dataset in a certain time period.
MoPub Analytics has Auction, Bid, and Adserver datasets that are stored on the cluster across 4 tiers. Our fast tier holds data from the 14 most recent days and our slow tier holds the remaining data up to a total of 13 months. The fast and slow tiers are replicated 2 times to ensure high data availability and allow us to perform cluster operational maintenance without any end user impact. In the MoPub Analytics cluster we find that fast tiers are CPU bound and slow tiers are I/O bound.
The Druid cluster is run out of one of Twitter’s data centers and contains machines with 384 GB of RAM and a 4 TB NVMe SSD. We achieve acceptable latency while controlling our costs by keeping all data for the most recent two weeks in RAM and using a 5:1 SSD to RAM ratio for older data. Our current production cluster consists of 600 historicals, 10 brokers, 1 coordinator, and 4 middle managers. Historical nodes run in a dedicated mesos cluster to minimize cluster data movement. Other cluster nodes run in the general shared mesos cluster.
Query Time Lookups
MoPub Analytics contains a number of dimensions that change over time and where we always want to surface the most recent value in MoPub Analytics. We use query time lookups for this (specifically the druid-lookups-cached-global extension). We load lookups via MySQL and optimized the extension to support incremental loading of large lookups. Our largest lookup contains over 7 million IDs. An example query time lookup maps internal publisher IDs to a company name. A given company can have multiple publisher IDs (accounts) and the company name may change over time.
Monitoring
We monitor high-level MoPub Analytics service level objectives with Twitter’s Observability monitoring stack. This allows us to track things like data availability, aggregate query success rates, and query latencies based on percentiles. We use Clarity, a Imply-provided performance telemetry suite, to understand and improve cluster performance. Clarity runs as a separate Druid cluster and UI. Our production Druid cluster pushes metrics to the Clarity cluster via Kafka and they are ingested into the Clarity cluster in real time. Clarity is extremely useful for understanding and improving cluster performance.
Twitter, a Data-Driven Organization
Building a platform that instills a data-first culture to drive decision making internally and externally has been our mission with MoPub Analytics. We are excited to continue scaling this solution across Twitter.
Acknowledgements
MoPub Analytics was made possible by a large group of people inside of Twitter as well as the many contributors to Druid and Imply. Special thanks to Keji Ren, Swapnesh Gandhi, Ishan Roy Choudhury, Andrei Savu, Upendra Reddy Lingareddygari, Elizabeth Gilmore, Cyrus Amiry, David Turbay, Kira Roytburg, Ben Heiber, Franklin Ramirez, Brittany Aguilar, Jayme Farrell-Ranker, Michal Jacobsberg-Reiss, Nayef Hijazi, Denise Teng, and Anand Ramesh.
We are hiring! Come and join us to build innovative analytics solutions and more at scale.