Infrastructure
Partly Cloudy: Architecture
By
Thursday, 9 May 2019
Recently, Twitter Engineering embarked on an effort to migrate elements of the Twitter stack to the cloud. This is another article in a series describing that journey. Here we describe, at a high level, how we adapted our on-premises Hadoop architecture to a hybrid cloud approach.
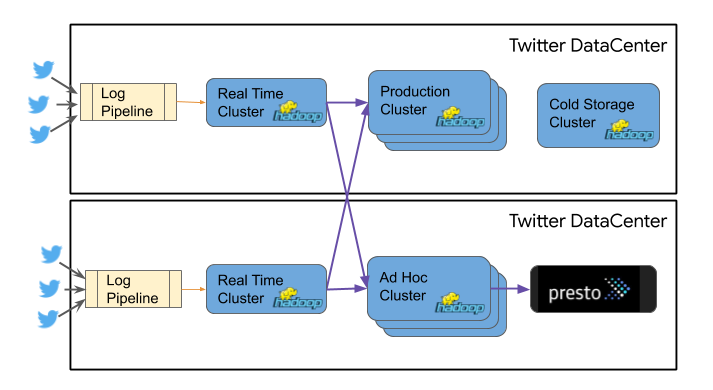
Our Hadoop infrastructure is made up of tens of thousands of servers and over a dozen clusters. Each cluster in our environment has a specific purpose. For example, each data center contains a near real-time ingestion and serving cluster. Some of our data centers contain ad-hoc data-warehousing clusters and others production processing clusters. We separate these use cases into different data centers for disaster recovery purposes. We also have cold storage/backup clusters. Although the hardware in the cold cluster is extra dense in storage, the CPU is very underutilized compared to other clusters.
As Twitter users interact in various ways with our services, they generate events collected through the log pipeline. These messages are collated into log categories on the Real Time Hadoop clusters and distributed to the various downstream clusters.
Each cluster has multiple HDFS namespaces and can scale up to a practical operational size of about 10,000 worker nodes each. Beyond that point, we split the workload to a separate cluster. The advantage of large shared multi-tenant clusters is that we can “bin pack” many different production jobs and attain high overall utilization, in the upper 80% range. (See the end section on bin packing for more information.)
The diagram below depicts these Hadoop clusters in two of our data centers. While our overall data processing infrastructure contains several additional components and systems, in this article we focus on those pieces that are most affected by our cloud migration.
As our internal codename Partly Cloudy implies, we are migrating only part of our Hadoop infrastructure to Google Cloud Platform. Specifically, we are migrating the Ad Hoc and Cold Storage clusters, while the Real Time and Production Hadoop clusters will remain in our on-premises data centers.
With this goal in mind, the first three questions we needed to answer were:
We are aiming to replicate over 300 PB of data to GCS. Copying a static dataset is one thing, but in our environment older data drops off and newer data is produced on a continual basis. Many existing data partitions need to be scrubbed of sensitive data. Now the challenge is to keep a constantly moving target in sync between our data centers and GCS, so the option of shipping a physical device is off the table for us.
The data volumes require some serious connectivity, and rule out an approach of using proxies. When we started our project, GCS endpoints were accessible by private IP addresses through Dedicated Interconnect only, which was limited to 10Gbps at the time. That was not sufficient for our needs. We have provisioned 800 Gbps redundant direct peering network connectivity between the Twitter and Google data centers. In this setup, we access GCS through public IP addresses. The hosts sending data now need to be exposed to the Internet. Even though HTTPS encrypts all data transfers, we prefer not to provide external network connectivity to tens of thousands of Hadoop hosts. Limiting network connectivity is easier to manage on a smaller number of machines.
For this reason, we introduced a dedicated copy cluster in each data center. Copy clusters give us a way to schedule, throttle, and prioritize data copies as well. Copy clusters have the sole purpose of transferring data from on premises to GCS. We use the regular Yarn scheduler to schedule copy jobs, for example, to prioritize replicating the newly arrived data over a back-fill of older datasets. Copy clusters are not used to run general purpose jobs. They provide compute and network capabilities only, leaving the local HDFS storage capabilities of these pass-through clusters unused.
On premises, our analytics workloads are a mix of Scalding jobs, Hive queries, Presto queries, and other tools, such as Heron topologies and Druid. These queries or workflows translate into a directed acyclic graph (DAG) of jobs that are executed on the cluster. On cloud, we gain the option to leverage Cloud Dataflow, Cloud Dataproc, and BigQuery managed services.
Instead of requiring all workflows to change to these cloud offerings, and in order to facilitate an easier migration, we decided to offer at least parity with our on-prem infrastructure. Where it makes sense, we then let our users use cloud native solutions. In order for the managed services to work, the data needs to be in shared Google Cloud Storage. This brings us to our third question...
For our on-prem clusters we get significant benefit from scheduling compute tasks on Yarn near the data blocks stored in HDFS. This locality reduces the data that needs to be read over the network, or worse, pulled across top-of-rack switches. Our testing found that the network connectivity in GCP is sufficient to separate most of the storage from compute. For Scalding and Spark jobs, the original input and final output of each DAG will be in GCS, while the intermediate data will be in HDFS. When jobs use the FileSystem abstraction in Hadoop, the interactions with data remain mostly unchanged whether the data is stored in HDFS or in GCS through its GCS connector.
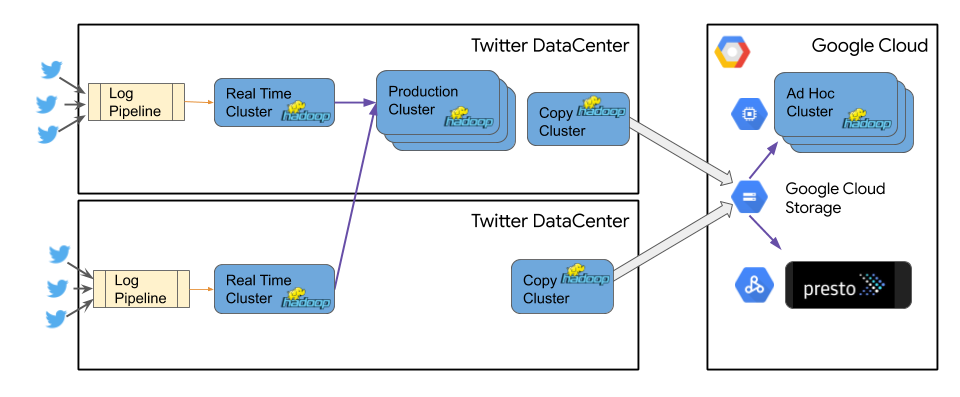
The diagram below shows the target architecture for realizing a hybrid on premises and cloud model for data processing at Twitter.
Messages generated by Twitter users interacting with our services still flow through the real time clusters and data is still replicated to production clusters that remain on premises. Each data center now has a copy cluster dedicated to orchestrating data replication to GCS. The ad hoc use cases move to cloud, including Presto. Initial inputs into each compute DAG and the eventual outputs are stored in GCS. Now interactive queries on Presto can access the data from there. Note that in our target architecture GCS is used to store both ad hoc as well as cold data. A separate cold Hadoop cluster is no longer needed in this setup. That is one fewer large cluster to manage, while we eliminate the underutilized compute aspect, saving tens of thousands of otherwise mostly idle cores.
With this hybrid architecture in mind, let’s focus on the details of the GCP design in our next article.
When scheduling jobs on a Hadoop cluster — just like scheduling tasks on any shared distributed infrastructure — we face a classic fragmentation issue. The question is whether to have a single large cluster used by many people or small clusters used by few people. To understand the issue and its implications on resource utilization and ultimately costs, consider the seating arrangements in a restaurant.
Our fictional, simplified restaurant has a dozen six-person tables. Dinner parties range between one to six people. In our case, each party fits at a single table, with the remaining seats left empty. Depending on the distribution of party sizes, some tables are completely full, while other tables with only one or two diners are mostly empty.
Now imagine that the restaurant owner reconfigures the venue to have long tables with benches. Parties will still be seated adjacent to each other and across the table, with only perhaps a single seat left empty to allow two person parties to sit directly across from one another.
It is easy to see that with the larger shared tables, the space in the restaurant will be used more efficiently due to fewer empty seats. If there are no other bottlenecks or constraints, such as waiting staff or kitchen capacity, more people can be served in the shared situation than in the more fragmented approach.
Just like in a restaurant, in distributed systems with shared resources we have to consider noisy neighbors (that make it hard to enjoy your dinner), fairness in cases of priority scheduling (seating), and ultimately starvation of tasks (customers) waiting too long for other more important tasks (guests) to finish. Then there is wasted work in case of preemption (a guest is asked to vacate the table and go back in line moments after the soup is served). And there is bin-packing: which algorithm to use to schedule tasks (guests at tables) with an unpredictable workload.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.