Infrastructure
Deleting data distributed throughout your microservices architecture
By
Monday, 4 May 2020
Microservices architectures tend to distribute responsibility for data throughout an organization. This poses challenges to ensuring that data is deleted. A common solution is to set an organization-wide standard of per-dataset or per-record retentions. There will always be data, however, that spans multiple datasets and records. This data is often distributed throughout your microservices architecture, requiring coordination between systems and teams to delete it.
One solution is to think of data deletion not as an event, but as a process. At Twitter, we call this process “erasure” and coordinate data deletion between systems using an erasure pipeline. In this post, we’ll discuss how to set up an erasure pipeline, including data discoverability, access, and processing. We’ll also touch on common problems and how to ensure ongoing maintenance of an erasure pipeline.
Discoverability
First, you’ll need to find the data that needs to be deleted. Data about a given event, user, or record could be in online or offline datasets, and may be owned by disparate parts of your organization. So your first job will be to use your knowledge of your organization, the expertise of your peers, and organization-wide communication channels to compile a list of all relevant data.
Data Access and Processing Methods
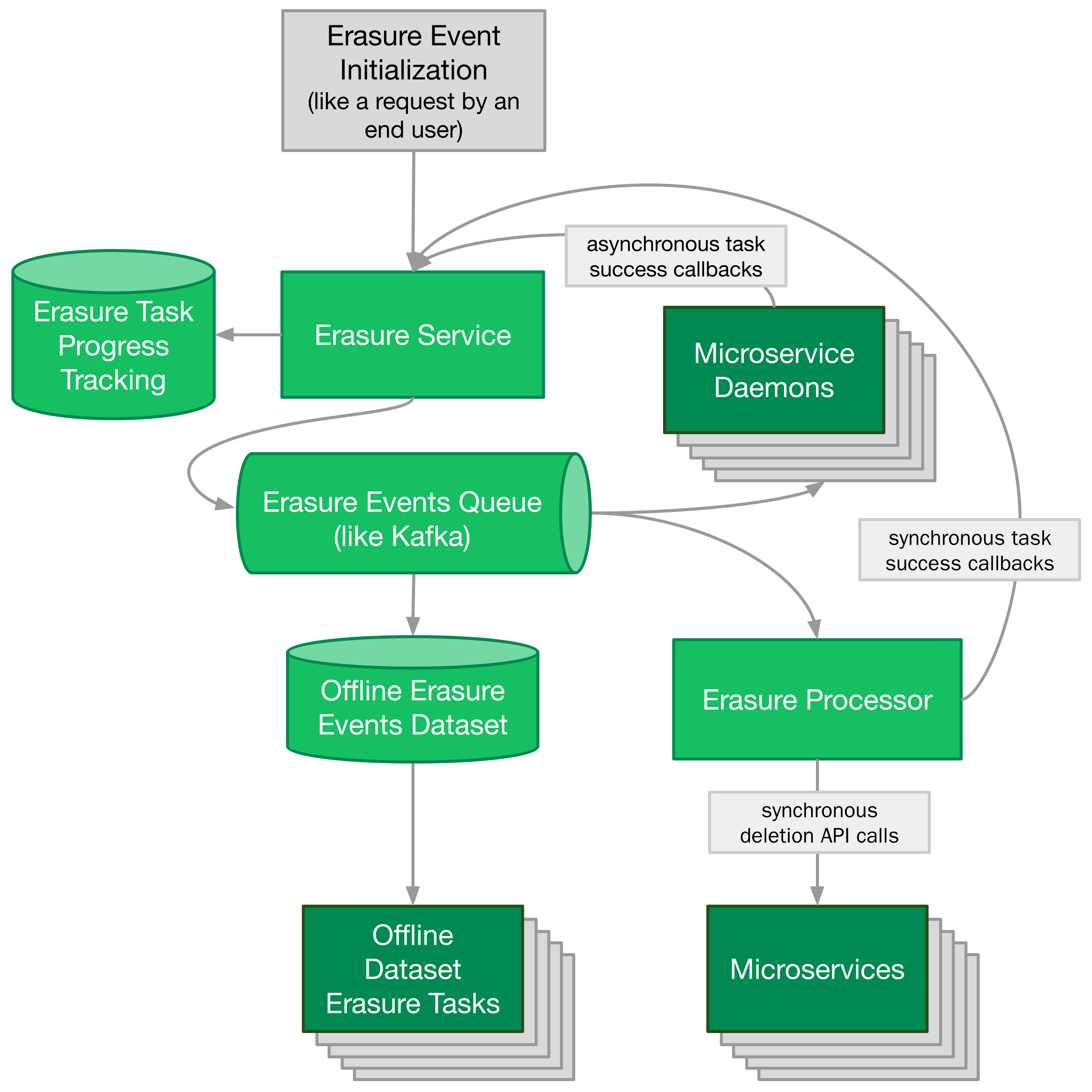
The data you find will usually be accessible to you in one of three ways. Online data will be mutable via (1) a real-time API or (2) an asynchronous mutator. Offline warehoused data will be mutable via (3) a parallel-distributed processing framework like MapReduce. In order to reach every piece of data, your pipeline will need to support each of these three processing methods.
Data mutable via a real-time API is the simplest. Your erasure pipeline can call that API to perform data deletion tasks. Once the API calls have succeeded for each piece of data, the data has been deleted and your erasure pipeline is finished.
The downside of this approach is that it assumes every data deletion task can be completed within the span of an API call, usually seconds or milliseconds, when it may take longer. In this case, your erasure pipeline has to get a bit more complicated. Examples of data that can’t be deleted in the span of an API call include data that is exported to offline snapshots, or data that exists in multiple backend systems and caches. This data denormalization is inherent to your microservices architecture and increases performance. It also means that responsibility for the data’s lifecycle is delegated to the team who owns the data’s APIs and business logic.
You’ll need to inform data owners that data deletion needs to happen. Your erasure pipeline can publish erasure events to a distributed queue, like Kafka, which partner teams subscribe to in order to initiate data deletion. They process the erasure event and call back to your team to confirm that the data was deleted.
Finally, there may be completely offline datasets containing data that needs to be deleted, such as snapshots or model training data. In these cases, you can provide an offline dataset which partner teams use to remove erasable data from their datasets. This offline dataset can be as simple as persisted logs from your erasure event publisher.
An Erasure Pipeline
The erasure pipeline we’ve described thus far has a few key requirements. It must:
An example erasure pipeline might look like this:
An architecture like this is a great start, but there are a few concerns we haven’t yet discussed.
Common Problems
The first issue is service outages and network partitions. An erasure pipeline needs to be resilient to outages. Its goal is to succeed at erasure, so it can retry its tasks when service has been restored. A simple way to accomplish this is to ensure that all erasure tasks are replay-able. When there’s an outage, we simply replay any erasure events that were dropped. The erasure tracking system knows which erasure events have yet to fully be processed and can re-publish those.
Sometimes, no matter how many times you replay an erasure event, the pipeline simply won’t complete. It's “broken” for those events. Data can be un-erasable, for example because it was invalid in the first place. When one of your data-owning teams is unable to complete an erasure task, the integrity of the erasure pipeline has moved outside of your control. Responsibility for fixing the issue needs to be delegated to the right team.
Maintenance
This delegation can be achieved by putting each data-owning team on call for their erasure tasks. Maintenance of a pipeline like this, which combines disparate tasks into a pipeline with one SLA, can only scale if each team takes responsibility for their part in erasure.
At Twitter, we expect each team that owns an erasure task to place alerts on the success of that task. We supplement these with an alert on the overall success of erasure event processing with an SLA of days or weeks. This lets us promptly catch erasure pipeline issues while directing issues with individual erasure tasks to the responsible team.
Testing
Testing a distributed pipeline like this one follows the same principles we’ve been discussing: each data-owning team is responsible for testing their erasure tasks. All you need to do as the erasure pipeline owner is generate test events that they can respond to.
The challenge is coordinating test data creation in the systems owned by your partner teams. In order to integration test their own erasure tasks, these partners need test data to exist before you trigger an erasure event. One solution is a testing framework that pairs test data generation with a cron job that publishes erasure events some time after test data has been created.
Future Direction
The complexity of an erasure pipeline can be greatly reduced by implementing an abstraction like a data access layer or data catalog for the data living in your online microservices and offline warehouses. Twitter is moving in this direction to simplify the architecture necessary for complex processing tasks like data deletion. Data access layers or data catalogs index the data needed to satisfy an erasure request and enable processing of that data. This unifies data deletion outcomes with data ownership responsibilities.
That’s it!
Thanks for reading. We hope that this post has given you an idea of the challenges a microservices architecture can create for data compliance. Ideally, it has also shared with you some solutions that will spark new ideas as you embark on your own designs.
This content was made possible by the work of Tom Brearley, Erik Froese, Goran Peretin, and Felix Yeung, among others. And thanks to the folks who reviewed this post including Marcia Hofmann and Raine Hoover.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.