Infrastructure
Reducing search indexing latency to one second
By
and
Friday, 5 June 2020
One of the key metrics for a search system is the indexing latency, the amount of time it takes for new information to become available in the search index. This metric is important because it determines how quickly new results show up. Not all search systems need to update their contents quickly. In a warehouse inventory system, for example, one daily update to its search index might be acceptable. At Twitter -- where people are constantly looking for the answer to “what’s happening” -- real-time search is a must.
Until mid-2019, the indexing latency for Twitter’s search system was around 15 seconds. It was fast enough to power relevance-based product features such as the ranked Home timeline, which delivers Tweets based on their relevance. Since determining a Tweet's relevance is based on factors such as how much engagement it gets, there is less need for instant indexing. Use cases requiring a much lower indexing latency, however, couldn’t be powered by our search infrastructure. For example, we couldn’t use this same search system to retrieve Tweets for a person’s profile page where people generally expect to see their Tweets appear the moment they are published.
Two main limitations prevented us from lowering our indexing latency:
Overcoming these limitations required major changes to our ingestion pipeline and our indexing system, but we believe the results were worth the effort. Tweets are now available for searching within one second of creation, which allows us to power product features with strict real-time requirements, such as real-time conversations or the profile pages. Let's take a closer look at how we've achieved this.
The core of almost all search systems is a data structure called an inverted index. An inverted index is designed to quickly answer questions like "Which documents have the word cat in them?". It does this by keeping a map from terms to posting lists. A term is typically a word, but is sometimes a conjunction, phrase, or number. A posting list is a list of document identifiers (or document IDs) containing the term. The posting list often includes extra information, like the position in the document where the term appears, or payloads to improve the relevance of our ranking algorithms.1
The search systems at Twitter process hundreds of thousands of queries per second and most involve searching through posting lists of thousands of items, making the speed at which we can iterate through a posting list a critical factor in serving queries efficiently. For example, consider how many Tweets contain the word “the.”
We use Lucene as our core indexing technology. In standard Lucene, an index is subdivided into chunks called segments, and document IDs are Java integers. The first document indexed in a particular segment is assigned an ID of 0, and new document IDs are assigned sequentially. When searching through a segment, the search starts at the lowest document IDs in the segment and proceeds to the highest IDs in the segment.
To support our requirement of searching for the newest Tweets first, we diverge from standard Lucene and assign document IDs from high to low: the first document in a segment is assigned a maximum ID (determined by how large we want our Lucene segment to be), and each new document gets a smaller document ID. This lets us traverse documents so that we retrieve the newest Tweets first, and terminate queries after we examine a client-specified number of hits. This decision is critical in reducing the amount of time it takes to evaluate a search query and therefore in letting us scale to extremely high request rates.
When we were using sorted streams of incoming Tweets, it was easy to assign document IDs: the first Tweet in a segment would get the ID of size of the segment minus one, the second Tweet would get the size of the segment minus two, and so on, until we got to document ID 0. However, this document ID assignment scheme doesn’t work when the incoming stream isn’t sorted by the time a Tweet was created. In order to remove the delay added by sorting, we needed to come up with a new scheme.
In the new document ID assignment scheme, each Tweet is assigned a document ID based on the time that it was created. We needed to fit our document IDs into a 31-bit space, because Lucene uses positive Java integers as document IDs. Each document ID is unique within a segment, and our segments are usually writable for about 12 hours. We decided to allocate 27 bits to store timestamps with millisecond granularity, which is enough for a segment to last for a bit more than 37 hours. We use the last four bits as a counter for the number of Tweets with the same timestamp. This means that if we get more than 24 (16) Tweets with the same millisecond timestamp, then some of them will be assigned a document ID that is in a slightly incorrect order. In practice, this is extremely rare, and we decided that this downside was acceptable because we often ran into a similar situation in the old system when a Tweet was delayed for more than 15 seconds, which also resulted in the assignment of an unordered document ID.
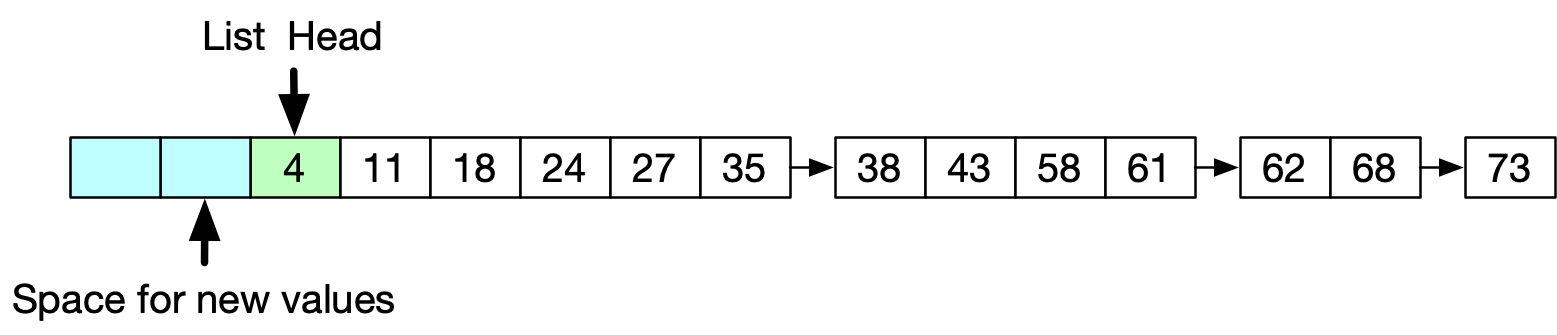
For the past eight years, the search systems at Twitter used a prepend-only unrolled linked list as the data structure backing the posting lists. This has allowed us to avoid the overhead of storing a pointer for every value and vastly improved the speed of traversing a posting list because it was cache friendly. (An unrolled linked list is a linked list with multiple values per link — there is a good description on Wikipedia.)
In our old implementation, the linked list started out with a single value, and we allocated exponentially larger nodes each time the list needed to grow.
Searcher threads would start at the most recently added item of the linked list and follow pointers until reaching the end of the list. Writers would only add new items to the start of the list, either by adding a new posting in the existing array or creating a new block and adding the new posting to the new block. After adding the item and setting up the links correctly, the writer would atomically update its pointer to the new head of the linked list. Searchers would either see the new pointer or the old pointer, but never an invalid pointer.
The list was prepend-only so that we didn’t need to rewrite pointers internally and also because adding items to the middle of a block of postings would have required copying, slowing down the writer and requiring complex bookkeeping (like tracking which blocks were up to date, which were stale but still used by searchers, and which could be safely used for new postings). It also worked well with our old document ID assignment scheme, because it guaranteed that posting lists were always sorted by document ID.
These linked lists supported a single writer and many searchers without using any locks, which was crucial for our systems: We had a searcher for every CPU core, with tens of cores per server, and locking out all of the searchers every time we needed to add a new document would have been prohibitively expensive. Prepending to a linked list was also very fast (O(1) in the size of the posting list) as it just required following a single pointer, allocating a new element, and updating the pointer.
You can find more details on the unrolled linked list approach we used in Earlybird: Real-Time Search at Twitter.
The linked list data structure served our system well for many years: it was easy to understand and extremely efficient. Unfortunately, that scheme only works if the incoming Tweets are strictly ordered because you can’t insert new documents into the middle of the list.
To support this new requirement, we used a new data structure: skip lists. Skip lists support O(log n) lookups and insertions into a sorted set or map, and are relatively easy to adapt to support concurrency.
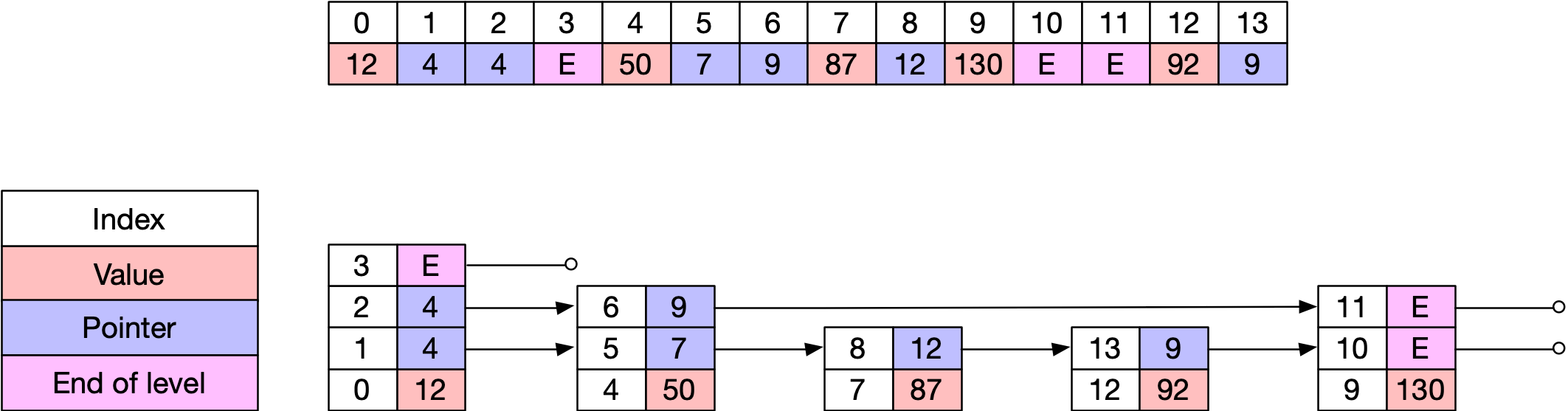
A skip list has multiple levels, and each level stores elements in a linked list. The lowest level contains all of the elements, the next highest level contains some fraction of those elements, and so on, until we reach the highest level which contains just a few elements. If an element is stored at level N, then it is also stored at all levels 1, 2, …, N - 1. Each of the elements in a higher level contains a link to the equivalent element in a lower level. To find a given element, you start out at the highest level, and read along that linked list until you find an element that is greater than the one you are looking for. At that point, you descend one level and start examining elements in the more densely populated linked list.
When we add an element, we always add it to the bottom level. If we add the element at level N, we randomly decide to add the element at level N + 1 with 20% probability and continue recursively until we don't make the random decision to add an element at the next higher level. This gives us 1/5th as many elements at each higher level. We have found a 1:5 ratio to be a good tradeoff between memory usage and speed.
We can implement the skip list in a single flat array where each “pointer” is just an index into the skip list array, like so:
Note that each level of the skip list is terminated with a special “end of level” value, which signals to the search process that there are no higher values at this level of the skip list.
Our skip list implementation has a few notable optimizations to reduce the amount of memory used in each posting list, improve search and indexing speed, and support concurrent reading and writing.
First, our skip list always adds elements to the end of an allocation pool. We use this to implement document atomicity, described below. When a new element is added, first we allocate the element at the end of the pool, then we update the pointer at the lowest level of the skip list to include that item. Typically, this is the “head” pointer of the skip list, but if it's a larger document ID than the head of the skip list, we will traverse further down the skip list and insert the posting into the correct place. We also sometimes rewrite pointers in the higher levels of the skip list structure. There is a one-in-five chance that we add the value to the second level of the skip list, a one-in-25 chance that we add it to the third level, and so on. This is how we ensure that each level has one-fifth of the density of the level below it, and how we achieve logarithmic access time.
Second, when we search for an element in a skip list, we track our descent down the levels of the skip list, and save that as a search finger. Then, if we later need to find the next posting with a document ID greater than or equal to a given value (assuming the value we are seeking is higher than the original value we found), we can start our search at the pointers given by the finger. This changes our lookup time from O(log n), where n is the number of elements in the posting list, to O(log d), where d is the number of elements in the posting list between the first value and the second value. This is critical because one of the most common and expensive queries in a search engine are conjunctions, which rely heavily on this operation.
Third, many of the data structures in our search system store all of their data in an array of primitives to remove the overhead imposed by the JVM of storing a pointer to an object and to avoid the cost of having many live objects survive in the old generation, which could make garbage collection cycles take much more time. This makes coding data structures much more challenging, because every value in the array is untyped — it could be a pointer, a position, a payload, or completely garbled in the case of race conditions. Using programming language-level features like classes or structs in another language would make understanding and modifying these data structures far easier, so we are eagerly awaiting the results of OpenJDK's Project Valhalla.
Fourth, we only allocate one pointer for every level of the skip list. In a typical skip list, a node will have a value, a pointer to the next largest element in the list and a pointer to the lower level of the skip list. This means that a new value allocated into the second level will require the space for two values and four pointers. We avoid this by always allocating skip list towers contiguously. Each level K pointer will only point to other level K pointers, so to extract the value associated with a level K pointer P, you read the value at P - K. Once you reach a node with a value greater than the one you are searching for, you go back to the previous node, and descend a level by simply subtracting one from the pointer. This lets us allocate a value into the second level by just consuming the space for the value and two pointers. It also reduces the amount of time we need to spend chasing pointers, because a pointer into a tower is likely to be on the same cache line as the lower pointers in that tower.
One of the downsides of having a linked list between elements in a particular node instead of an array is that the skip list is much less cache friendly than an unrolled linked list or B-tree — every single element access requires chasing a pointer, which often results in a cache miss. This increased the amount of time it took to traverse a single posting list, especially the very dense ones. However, the tree structure and logarithmic access time actually improved the speed for queries that accessed sparse documents (conjunctions and phrase queries) and allowed us to reach nearly the exact same average query evaluation speed as the unrolled linked list.
In any data storage and retrieval system, it’s important to ensure that operations happen atomically. In a search system, this means that either all of the terms in a document are indexed or none of them are. Otherwise, if a person who used Twitter searched for a negation, for example, "filter:images dogs AND -hot", and we were in the middle of adding the image annotation "I sure love hot dogs!" to the ”dogs” posting list but hadn’t added it to the “hot” posting list, the person might see a photo of a grilled sausage sandwich instead of a lovable canine.
When using sequential document IDs and avoiding updates, it's easy to track which documents are visible to the searchers. A searcher thread reads from an atomic variable that marks the smallest visible document ID, and skips over any document identifiers that are smaller than that document ID. This let us decouple the logical level of consistency — the document — from the underlying data structures that support concurrency at a more granular level.
In our new system, newer documents are no longer guaranteed to have smaller document IDs. To support atomic updates to the skip list posting lists, we take advantage of the fact that the skip lists allocate new values at the end of a given allocation pool. When a searcher is created, it atomically gets a copy of a data structure that tracks the current maximum pointer into each allocation pool, which we call the published pointer. Then, whenever the searcher traverses a posting list, if the address of a posting is greater than the published pointer, the searcher will skip over that posting, without returning the document as a potential match. This lets us update the underlying data structure while the searcher is running, but preserves our ability to atomically create and update documents, and achieves our goal of separating data structure level atomicity from the logical, application layer atomicity.
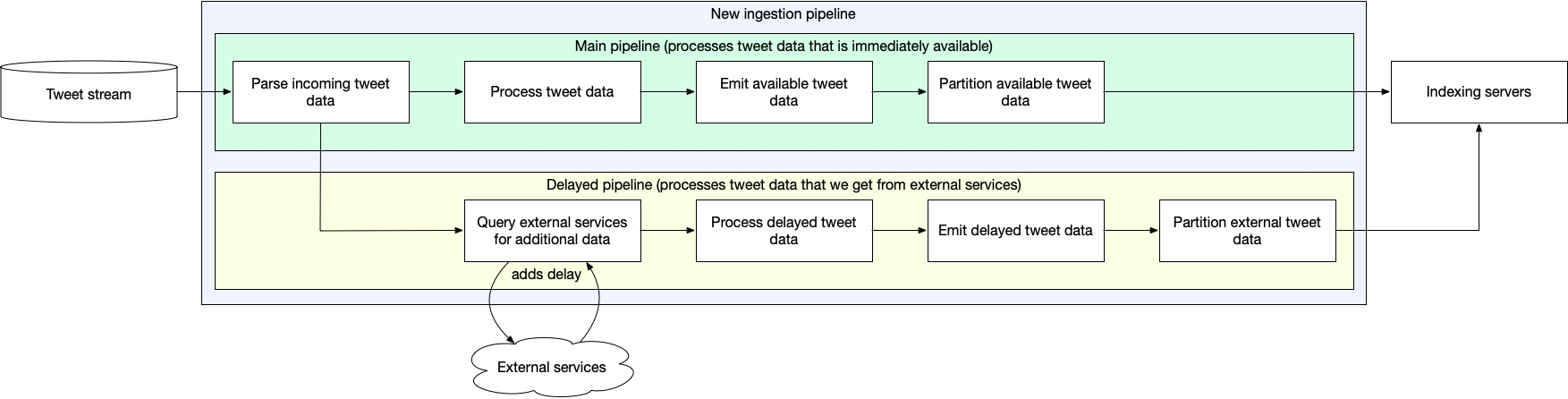
Because of the changes to our indexing system, we no longer needed our ingestion pipeline to have a buffer to sort all incoming Tweets. This was a big win for reducing our indexing latency, but we still had the delay caused by waiting for some fields to become available.
We noticed that most Tweet data that we wanted to index was available as soon as the Tweet was created, and our clients often didn’t need the data in the delayed fields to be present in the index right away. So we decided that our ingestion pipeline shouldn’t wait for the data in these delayed fields to become available. Instead, it can send most of the Tweet data to our indexing system as soon as the Tweet is posted, and then send another update when the rest of the data becomes available.
This approach allowed us to remove the final artificial delay in our ingestion pipeline, at the cost of very new Tweets not having complete data. Since most search use cases rely only on fields that are immediately available, we believe this was an acceptable price to pay.
Rolling out a change of this magnitude isn’t easy. First, our ingestion pipeline became more complex, because we switched from one that was fully synchronous to one with synchronous and asynchronous parts. Second, changing the core data structure in our indexing server came with the risk of introducing obscure bugs that were virtually impossible to detect in unit tests. And third, it was hard to predict if returning newer Tweets would break any assumption in a customer's code.
We decided that the best way to test our new ingestion pipeline (in addition to writing many new tests) was to deploy it alongside the old ingestion pipeline. This meant that during the rollout period we had two full copies of indexing data. This strategy allowed us to gradually migrate to the new ingestion pipeline, and at the same time, we could easily switch back to the old stream of data if there was a problem.
We also set up a staging cluster of indexing servers that mirrored our production environment as closely as possible and started sending a fraction of our production requests to these servers in addition to production servers (a technique known as dark reads). This allowed us to stress test the changes to our core indexing data structures with real production traffic and load, with both the old and new streams of Tweet data. Once we were confident that the new data structures were working as expected, we reused this staging cluster to test the correctness of the data produced by the new ingestion pipeline. We set up this cluster to index the data produced by the new ingestion pipeline and compared the responses to production. Doing so revealed a few subtle bugs, which only affected dark traffic. Once we fixed them, we were ready to deploy the change to production.
Since we didn’t know what assumptions our clients made in their code, we took a conservative approach. We added code to our indexing servers to not serve any Tweet posted in the last 15 seconds (our initial indexing latency) and gradually rolled out all changes on the indexing side. Once we were confident that the indexing changes worked as expected, we removed the old ingestion pipeline. We checked with customers to see if recent Tweets would cause any issues, and, fortunately, none of them relied on the 15-second delay. However, some customers relied on the delayed fields being indexed at the same time as the original document. Instead of adding special handling for queries from these clients in the search system, those customers added a filter to their queries to not include recent Tweets. After this, we were finally ready to remove the 15-second serving restriction we had previously added to our indexing servers.
Making changes to a data storage and retrieval system introduces unique challenges, especially when those systems serve hundreds of thousands of queries per second. To get low search indexing latency at Twitter, we needed to make significant changes to our ingestion pipeline and the core data structure used in our indexes, extensively test these changes, and carefully deploy them. We believe the effort was worth it: indexing a Tweet now takes one second, which allows us to satisfy the requirements of even the most real-time features in our product.
This work wouldn’t have been possible without continuous advice and support from all members of the Search Infrastructure team at Twitter: Alicia Vargas-Morawetz, Andrew McCree, Bogdan Gaza, Bogdan Kanivets, Daniel Young, Justin Leniger, Patrick Stover, Petko Minkov, and Will Hickey; as well as Juan Caicedo Carvajal, Juan Luis Belmonte Mendez, Paul Burstein, Reza Lotun, Yang Wu, and Yi Zhuang.
1 For example, consider the following Tweet: "SF is my favorite city, but I also like LA." Since "SF" appears at the beginning of the Tweet and "LA" appears at the end, it might make sense to assign a higher score to this Tweet when users search for "SF" than when they search for "LA." In this case, the score would be a payload.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.