Infrastructure
Logging at Twitter: Updated
By
Friday, 13 August 2021
While centralized logging previously existed at Twitter, it was limited by low ingestion capacity and limited query capabilities, which resulted in poor adoption and failed to deliver the value we hoped for. To address this, we adopted Splunk Enterprise and migrated centralized logging to it. Now we ingest 4 times more logging data and have a better query engine and better user adoption. Our migration to Splunk Enterprise has given us a much stronger logging platform overall, but the process was not without its challenges and learnings, which we’ll share in greater detail in this blog.
Before we adopted Splunk Enterprise at Twitter, our central logging platform was a home-grown system called Loglens. This initial system addressed frustrations around the ephemerality of logs living inside of containers on our compute platform and the difficulty in browsing through different log files from different instances of different services while investigating an ongoing incident. This logging system was designed with the following goals:
Loglens was focused on ingesting logs from services that make up Twitter. In terms of addressing the problems set before it, with the cost and time constraints limiting it, Loglens was a fairly successful solution.
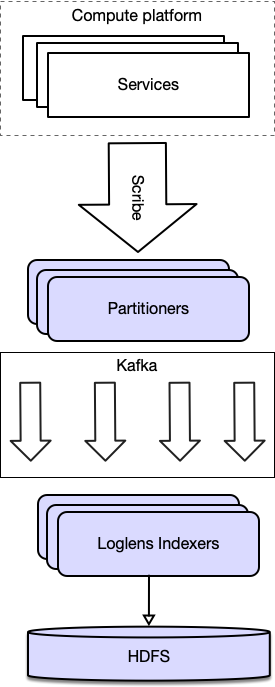
Unsurprisingly, a logging system with such limited resource investment ultimately fell short of users’ expectations, and the system saw suboptimal adoption by developers at Twitter. More information about Loglens can be found on our previous post. Below is a simplified diagram of the Loglens ingestion system. Logs were written to local Scribe daemons, forwarded onto Kafka, and then ingested into the Loglens indexing system.
While running Loglens as our logging backend, we ingested around 600K events per second per datacenter. However, only around 10% of the logs submitted, with the remaining 90% discarded by the rate limiter.
Given the title of this blog post, it’s not exactly a spoiler to say we replaced Loglens with Splunk Enterprise. Our adoption of Splunk Enterprise grew out of an effort to find a central logging system that could handle a wider set of use cases, including system logs from the hundreds of thousands of servers in the Twitter fleet and device logs from networking equipment. We ultimately chose Splunk because it can scale to meet the capacity requirements and offers flexible tooling that can satisfy the majority of our users’ log analysis needs.
Our transition to Splunk Enterprise was simple and straightforward. With system logs and network device logs being new categories for us to ingest, we were able to start fresh. We installed the Splunk Universal Forwarder on each server in the fleet, including on some new dedicated servers running rsyslog to relay logs from network equipment to the universal forwarder.
The most complicated part of the transition was migrating the existing application logs from our Loglens to Splunk Enterprise. Luckily, with the loosely coupled design of the Loglens pipeline, the majority of our team’s effort was in the simple task of creating a new service to subscribe to the Kafka topic that was already in use for Loglens, and then forward those logs on to Splunk Enterprise.
Perhaps a little unimaginatively, we named the new service the Application Log Forwarder (ALF). Our main goals when designing ALF were as follows:
ALF is a pretty simple service. It reads events from Kafka and submits them to Splunk Enterprise using the HTTP Event Collector, with some rudimentary rate limiting based on service name and log level. Despite its simplicity, ALF accounts for over 85% of all logs ingested. System logs forwarded by the Universal Forwarders or network device logs ingested through rsyslog+Universal Forwarder account for less than 15%.
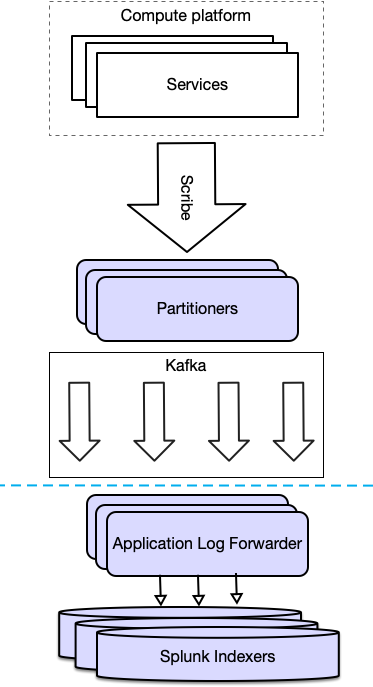
Our new logging pipeline for application logs looks very similar, as seen in the following figure. The only changes are below the blue dashed line.
Our current topology involves stamping a mostly independent cluster of indexers, search heads, deployer, and cluster manager in each of our primary data centers to ingest and index the logs from servers and services in that datacenter. The only interactions between the per-datacenter clusters is between the indexers and the license manager running on one of the deployers and the search head clusters configured to search all indexer clusters. We do not make use of multi-site index replication or multi-site search head clusters.
Currently we collect around 42 terabytes of data per datacenter each day. This excludes Splunk Enterprise’s internal logging and some logs from the noisiest services, which are rate limited. More than two-thirds of this traffic comes through the Splunk Enterprise HTTP Event Collector, going from log statement to on-disk storage in less than 10 seconds during normal operations. We ingest around 5M events per second per datacenter. This is more than 4 times greater than the events per second ingested when we used Loglens as our backend, and we still have plenty of disk space, disk IO, and CPU headroom for ingesting more logs.
In addition to the greater ingestion capacity, we’ve gained:
While the transition to Splunk Enterprise has significantly improved our logging service here at Twitter, it was not without challenges.
One basic challenge we’ve run into is managing the configuration of our Splunk Enterprise servers. While the standard solution of using a configuration management tool like Puppet or Chef covers the majority of the configuration we need to automate and manage, this approach still fell short of what we wanted for managing indexes and access control.
When we managed indexes and their access policies with Puppet, the whole process was ultimately limited by the following:
Not only did this approach require an engineer’s involvement and limit how quickly we can create an index, but it also did not integrate well into other provisioning tools at Twitter.
The solution we landed on was to create a new service that generates the indexes.conf and authentication.conf files and deploys them to the correct servers. This service presents an API with role-based access control to the rest of the network, letting us integrate index creation with existing provisioning tools.
This solution was hindered by some limitations in the Splunk Enterprise API. While there is an API endpoint that can create indexes, it works only for standalone indexers. There are also other limitations around remote management of configuration files. As a result, we copy files out of band to distribute configuration files. Additionally, the documentation for reloading configuration files is limited, and we are relying on an undocumented endpoint to reload authentication and authorization files without restarting the search heads.
Our approach gives us timely index creation with absolutely no involvement from an engineer on the Logging team under normal operation. We expect to see upwards of 600 indexes created dynamically by this process in the coming year.
Splunkbase contains an impressive array of add-ons. Many of these define modular inputs to collect data from the API of third-party applications, for example: Github, Slack, or Jenkins. These add-ons are usually simple to set up (though often a clustered environment complicates this), and within minutes you can be collecting data that otherwise is unavailable or difficult to collect.
Unfortunately, most of these modular inputs are written using either:
In either case, configuring the modular input on multiple nodes results in duplicate querying of the upstream API and duplication of data submitted to Splunk Enterprise. This means most modular inputs must run on a single node in your Splunk Enterprise infrastructure, creating a single point of failure. Should that node fail, it requires either manual intervention or additional complexity in your configuration management to allow for automatic selection of a new node. Ultimately most Splunkbase add-ons are not designed to run in a way that is resilient to unexpected server failures.
Instead, we are implementing plugins for a service that is scheduled by and runs on our compute infrastructure. Our plugins periodically load data from these third-party applications and submit it to our indexer clusters using ALF. The largest disadvantage of this approach is that we must re-implement each plugin ourselves. This is required because the existing modular inputs would require modifications to run under this new service and, given the variations of how different modular inputs are written and store their cursors, these modifications would end up being unique per modular input. It seems it will be easier to write new plugins that behave consistently.
Most of our data comes through ALF. If a service misbehaves and floods the system with enough logging events that the stability of our Splunk Enterprise clusters is threatened, we can discard events by log level or originating service. This lets us prioritize more important services and the overall health of our indexer clusters over the delivery of every message from every service of every severity. This in turn gives us time to investigate a sudden increase in log volume without causing a larger incident for all customers.
While it is less common in our environment, the Universal Forwarders running across the fleet sometimes also begin forwarding enough log volume to threaten the stability of the cluster. However, the Universal Forwarder lacks the flexibility to throttle or discard events. Admittedly, this is likely because of design decisions in the Universal Forwarder centered around assumptions that apply to most logs. However, such assumptions do not fit for many of our application-logs.
Server maintenance, like regular reboots, presents a significant challenge in our environment. While OS updates are applied live, firmware updates or kernel patches require a reboot. This presents a problem primarily for the indexers, as the search heads are less stateful and the cluster manager can be brought down briefly without impacting the indexer clusters or the search head clusters. This is complicated by the size of our clusters, with there being a few hundred indexers in each of our three indexer clusters.
Rebooting too many servers at once or rebooting them too rapidly in succession causes interruptions for searches and poor ingestion rates of new data. We have also seen unusual stability problems until we perform a clean rolling restart. Our uptime and reliability goals do not allow us room for such degraded service that lasts for a few hours for regular maintenance or for a full downtime.
We use a mostly manual process as follows:
This process can take up to a week, as it is very engineer driven and so progress occurs only during the work day. While it does not require constant attention from the engineer, it does present a decent sized interruption and burden on our team members.
Future work includes using existing work scheduling and automation services at Twitter to drive these tasks in an intelligent way.
Migrating our centralized logging service to Splunk Enterprise has enabled our engineers to retain more of their logs, ingest more types of log data, and perform more sophisticated querying and analysis of their logs. Installation and migration were fairly straightforward, resulting in a 400% increase in log volume while keeping the typical ingestion time, going from log statement to on disk, under 10 seconds. It has also introduced new challenges. We were able to work around the challenges we encountered running Splunk Enterprise with large clusters (200+ nodes) and high data volume (5 millions events per second per cluster), at times needing to write custom software to do so. Ultimately, this migration has resulted in increased adoption of centralized logging, including among core application teams and operations and security teams.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.