Infrastructure
Sharding, simplification, and Twitter’s ads serving platform
By
Thursday, 18 March 2021
Decomposing Twitter’s AdServer into different product bidders separates concerns in the AdServer architecture, which accelerates product development and infrastructure improvements. But splitting the AdServer monolith raises new questions about communication between the new microservices. We need to decouple and efficiently manage this communication. Here we describe a new sharding library at Twitter, called ShardLib. ShardLib simplifies the management of sharded ads services, and enables dynamic resharding of these services without redeploying their clients.
To understand ShardLib, it is helpful to understand how AdServer architecture uses sharding, and what problems sharding introduces for an architecture decomposed into multiple microservices. In this section, we first define sharding and describe the role it plays in the decomposed AdServer architecture. We then explain the challenges this architecture poses for efficiently managing communication between the various services.
Most of the decomposed services in the AdServer architecture are data-sharded services, that is, stateful services that are divided into multiple data shards (or simply, shards). Each shard stores only a small portion of the entire state (data) represented by the service. For example, the ads-selection service, which has various kinds of in-memory ads indices for computing eligible ad candidates for a request, can be decomposed into 24 shards, with each shard indexing approximately 1/24th of its indices. Typically, data is partitioned between the shards based on some key, which we refer to as the sharding key. A data item is assigned to a particular shard by applying a sharding hash function to map the sharding key into a hashed keyspace, and then partitioning the hashed keyspace into shards based on some sharding scheme. For example, one way to partition the ads database into 24 shards is to do the following:
If data is distributed roughly equally between advertiser IDs, then we can partition the hashed keyspace into roughly equal shards by having uniform ranges. For example,
Shard 0 = [0, MAX_LONG/24),
Shard 1 = [MAX_LONG/24, 2*MAX_LONG/24),
Shard 2 = [2*MAX_LONG/24, 3*MAX_LONG/24),
...
Shard 23 = [23*MAX_LONG/24, MAX_LONG].
The numbers 0 through 23 are shard IDs. We assume that for a sharding scheme with a total shard count of N=24, the shard IDs are integers in the range [0, N-1]. In general, there are many possible ways we can consider partitioning the hashed keyspace. In this article, we focus on range-based sharding, which partition the hashed keyspace of [0, MAX_LONG] into contiguous hash ranges, that is, subranges of [0, MAX_LONG]. Ads services use these sharding schemes. We also limit our discussion and assume all services use a compatible sharding scheme. That is, all schemes have the same sharding key and sharding hash function. In general, communication between services that have incompatible sharding schemes can be less efficient, as there is no easily predictable overlap between data stored by shards of different services when the hash functions are not the same.
For our AdServer architecture, we make the number of shards for a service large enough for the service to keep its entire state in-memory (RAM) while avoiding the performance penalties and limitations associated with storing and accessing large indices from a single shard instance. Also, because all our ads services are replicated, a particular service has multiple replicas (identical instances) for each data shard. Having multiple replicas for a service is required for data redundancy and so that we can horizontally scale to be able to serve incoming traffic from upstream services. For example, a service with 10 replicas and 24 shards would have a total of 240 server instances, 10 for each shard ID.
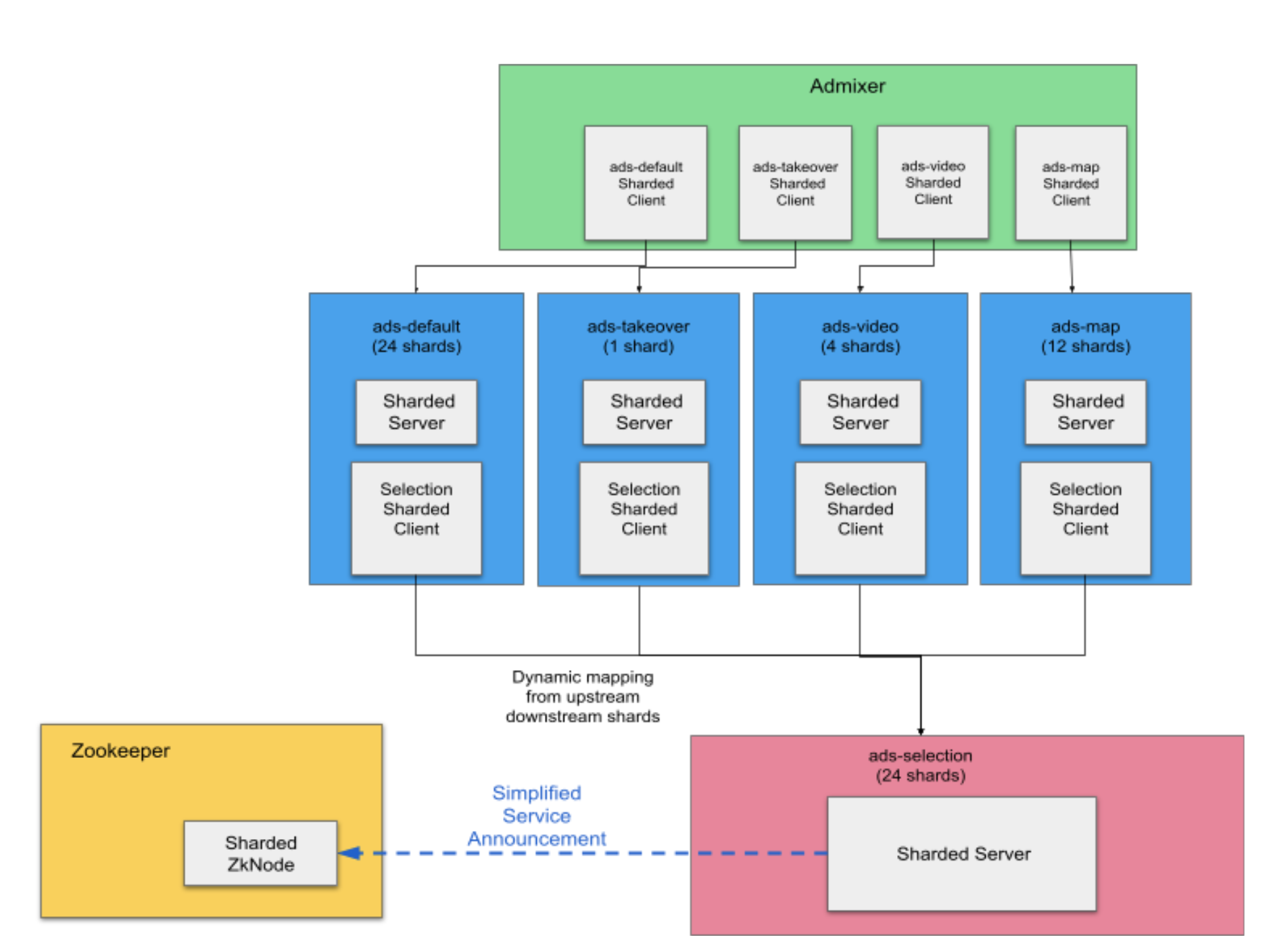
The AdServer decomposition effort broke the AdServer monolith into several microservices, which have two layers of service-to-service communication, as shown in Figure 1.
In the first layer, the Admixer service communicates with the product bidders. We have four ads bidder services: ads-default, ads-takeover, ads-video and ads-map, with each bidder sharded with a different number of shards. Admixer communicates with each bidder with a scatter-gather communication pattern. That is, the Admixer service sends requests to each shard of a bidder and then aggregates the responses from all the shards.
In the second layer, each ads bidder service communicates with an ads-selection service, using a more targeted (data-sharded) communication pattern. All the bidders and ads-selection services are sharded with a compatible sharding scheme – specifically, with the same sharding key and sharding hash function. Each bidder shard is responsible for some hash range, and it only communicates with the shards of ads-selection with hash ranges that overlap the bidder’s hash range. In our example, ads-default and ads-selection both have 24 shards, and there can be a 1:1 mapping between ads-default and ads-selection (that is, shard 3 of ads-default communicates only with shard 3 of ads-selection). For bidders with fewer shards, the mapping might require communication with multiple downstream shards. For example, if ranges in the sharding schemes are aligned appropriately, the range for shard 0 of ads-video might overlap with the ranges to ads-selection shards from the set {0, 1, 2, 3, 4, 5}.
The connections between the ads services shown in Figure 1 are managed using Finagle, an extensible RPC system designed for high performance and concurrency. At a high level, in Finagle, a collection of server instances for a service can be identified with a single Finagle Path. For example, when a Finagle server instance of the ads-takeover starts up, it conceptually announces itself as being part of a path, for example, /s/ads-takeover. This Finagle path logically maps to an underlying serverset – a set of network addresses (i.e., hostname and port) containing all instances of a service. Finagle uses Apache ZooKeeper to store serversets. Each ZooKeeper serverset can be thought of as a service registry that keeps its metadata in sync with the current state of instances in the service. For the remainder of this article, we use the term announcement path (or path for short) as a convenience to refer to either the high-level Finagle path or the ZooKeeper serverset path it corresponds to.
As shown in Figure 1, after we decompose the AdServer monolith into microservices, the server instances for each service use a per-shard announcement. That is, each shard of a service announces itself on a separate Finagle path. Thus, any service that is a client of a downstream sharded service needs to maintain a separate Finagle client for each downstream shard as well. For example, since Admixer is a client of ads-default, and ads-default has 24 shards, Admixer maintains 24 separate hardcoded Finagle clients for connecting to ads-default.
Complexity of Sharding after Microservice Decomposition
Decomposing the AdServer monolith into the product bidders and ads-selection greatly improved development efficiency. Separate teams can now be responsible for each service. This decomposition created a few new issues, however. Namely, (1) it created replicated code in each bidder for managing the communication with shards of ads-selection, and (2) it introduced coupling between services, when one service is a client of the sharded server of another service.
This first issue is a relatively simple one to understand, and is illustrated in Figure 1. Every service needs to maintain a separate Finagle client to every downstream shard of each downstream service, which results in significant code replication, particularly for a service like Admixer with multiple sharded downstreams services. Refactoring the sharding logic into a common library partially addresses this first issue of code replication.
Refactoring does not, however, address a second, more fundamental issue of coupling between services in terms of resharding, or changing the total number of shards and/or hash range boundaries in a sharding scheme. A service can choose to reshard because it.
To understand the coupling of ads services due to sharding, let’s consider what is required to support resharding. As a concrete example, consider resharding ads-selection from 24 to 12 shards. A normal change to ads-selection can be deployed independently, without redeploying a bidder, because each bidder works correctly with both versions of ads-selection, before and after the change. For resharding, however, each bidder shard instance has a separate Finagle client for communicating with each shard of ads-selection, and these shards are fixed on startup because of the per-shard service announcement. Therefore, deploying ads-selection with a different number of shards requires redeploying each bidder. Thus, resharding requires a group deploy of multiple services, namely, all bidders plus ads-selection.
At first glance, a group deploy might seem simple, but it can quickly turn into an operational nightmare. With separate teams managing the operational processes for each bidder, a group deploy means coordinating the deploy schedules of four bidders services plus ads-selection, making sure that all five services agree on the same shard count for ads-selection. At Twitter, we partition ads service instances into clusters. All instances of a service within a cluster run the same version of a service in a steady state. Normally, independent services within a single cluster can be deployed independently within a cluster. Since a bidder instance is not compatible with both old and new versions of ads-selection for a resharding change, the group deploy requires shutting down all the services one cluster at a time, and then rolling out the new version of each service one cluster at a time. What normally would be five independent, automated, and decoupled service deployments becomes one massive coordinated deployment, with potentially significant manual intervention required from on-call engineers if any one service has to get rolled back.
Simplifying Sharding with ShardLib
With these challenges in mind, we set out to build ShardLib, a sharding library to simplify the process of maintaining sharding schemes for services in the AdServer architecture. In addition to providing common library code for managing sharded servers and clients, ShardLib also enables dynamic resharding. That is, a server can change its number of shards without requiring coordination with the client service(s) and deploying them together with an operationally painful process. ShardLib enables this flexibility by providing a sharded client that works seamlessly even when multiple sharding schemes for a server are simultaneously active. In the remainder of this article, we describe the ShardLib support for sharded servers, and then the support for sharded clients. We close with a discussion of some of the challenges we faced migrating the various services onto ShardLib.
After the AdServer decomposition, sharded ads services lacked a common abstraction for the service’s sharding scheme. Instead, each service would define a total shard count and use a derived value to determine the shard ID for a particular instance. Additionally, the per-shard announcement of each service makes resharding the service prohibitive in nature due to coupling of deploys of servers and clients. As we explain in this section, ShardLib solves these issues by providing a common sharding abstraction as well as allowing each service to use sharded announcement – announcing all shards under a single Finagle path.
ShardLib introduces the concept of a placement, a unified abstraction that encapsulates the sharding scheme (the total shard count and hash ranges) for a service. The placement is a centralized source of truth for the service's own sharding scheme and for clients of the service to discover the sharding scheme of the service during runtime.
The placement abstraction is composed of two main components: a placement.json and an equivalent Java interface.
The placement JSON file is a static file that is populated with the application’s sharding scheme. The JSON file contains a placement version – a unique identifier for the sharding scheme – and a list of shards, named by the shard ID. Each shard defines the hash range that it is responsible for. For example:
{
"version" : "9585a7ba223005177647cc910d707627",
"shards" : [ {
"id" : 0,
"range" : {
"lower" : 0,
"upper" : 4611686018427387903
}
}, {
"id" : 1,
"range" : {
"lower" : 4611686018427387904,
"upper" : 9223372036854775807
}
} ]
}
The above JSON file defines a sharding scheme that has two shards, each of which is responsible for equal halves of the range [0, LONG.MAX_VALUE]. The placement version is essential for resharding, since it allows for disambiguation between two competing sharding schemes that might be active at the same time.
The Placement Java interface provides an in-memory representation of the JSON file that is queryable by the service. A sharded server uses the Placement interface to determine if it is responsible for indexing a particular database entity in memory. Additionally, a sharded server uses the Placement interface to determine if it should reject a particular request, which can happen if a sharded client incorrectly sends a request to the wrong downstream shard.
Additionally, we created a new HTTP endpoint that lets clients fetch a placement.json from the server at runtime, when they encounter a placement version for the first time, rather than hard-coding this information in the client at compile time.
To implement sharded servers in a way that supports dynamic resharding, we needed to change the process of service announcement for sharded services. We changed ads services to announce themselves using sharded announcement – announcing along one single Finagle path for all shards, instead of per-shard announcement as described above. ShardLib supports sharded announcement by adding metadata to ZooKeeper to enable shard-aware routing and load balancing within a single serverset by clients.
As discussed above, when a Finagle client wants to connect to a server for a service, it configures a client to connect to the Finagle path for the service. For example, for Admixer to send a request to ads-takeover, it must have a Finagle client configured to connect to the path /s/ads-takeover. When a client tries to send a request to ads-takeover, Finagle at a high level:
Before onboarding services onto ShardLib, each service performed a per-shard announcement. For example, shard 3 of ads-selection would announce itself on path /s/ads-selection-s3. For a bidder to connect to shard 3 of ads-selection, it would explicitly create a Finagle client to connect to path /s/ads-selection-s3. ShardLib changes services to use sharded announcement. That is, each sharded server announces itself to a single path. For example, after onboarding to ShardLib, all shards for ads-selection now announce themselves on a single Finagle path of /s/ads-selection-sharded.
The complications introduced by this change lie primarily on the client side. If we simply changed the server-side announcement, and all clients connected to the one sharded path, then the serverset for that path would contain server instances from all shards. Thus, the normal load balancer would send requests randomly to any shard, even if they were originally intended for one specific server shard. As we describe in the sharded client section, some extensions to the default Finagle stack are needed to achieve more intelligent shard-aware routing and load balancing. To provide the client with enough information to perform shard-aware routing and load-balancing, however, we require some small changes on the sharded server. We now populate additional ZooKeeper metadata during service announcement. In particular, we require metadata in ZooKeeper so that a load balancer can distinguish which addresses within a single serverset correspond to which shards. The metadata looks like below, where each instance in the serverset has its corresponding metadata attached:
"metadata":{
"placement.shard_id":"11",
"placement.version":"abcdef"
}
Sharded announcement enables dynamic shard discovery, or the discovery of new sharding schemes online. ShardLib can hide the complexity of multiple shards and multiple sharding schemes within a single path, and clients no longer need to care how many shards a downstream service is using.
In the previous architecture, there was no concept of dynamic shard discovery (discovering new sharding schemes), so it was impossible for sharded-to-sharded services to communicate without coupled configuration or hard-wired Finagle clients. Services had to use Finagle clients specific to each shard when communicating to sharded services. For example, if a client wanted to connect to the ads-selection service that is sharded 10 ways, it had to initialize 10 Finagle clients corresponding to each shard. ShardLib removes the coupling between the client and the downstream service on the sharding scheme.
Clients of a service sharded with ShardLib use a simple interface to communicate with the service’s server. The ShardLib client is responsible for:
Pruning intent encapsulates the portion of a data space that a particular client service represents. This information is used to decide which downstream service’s shards should receive the request. ShardLib takes care of translating that pruning intent into the relevant sharded backend nodes without leaking downstream service’s sharding information to the client.
In ShardLib, the pruning intent is based on pruning ranges, or contiguous ranges of the hashed shard-key's keyspace, the same keyspace used in the ranges in a server’s placement.
In the most trivial example, a client is not itself sharded and no pruning is required, so the pruning intent object would represent the entire range: range [0, MAX_LONG].
Alternatively, for a client that is sharded four ways, each of the client’s instances would be responsible for ¼ of the entire range, so the pruning intent for shard 0 would be range [0, MAX_LONG/4].
The ShardLib client wraps an existing Finagle StackClient to implement the appropriate functionality to route requests to the right set of shards. More precisely, the ShardLib client works with a client whose destination is a service sharded with ShardLib using a placement file that has a compatible sharding scheme.
At a high level, the ShardLib client inserts a custom Finagle Stack module into an existing Finagle StackClient to provide the following functionality:
The ShardLib client is responsible for fetching changes in downstream service’s ZooKeeper serverset. These changes usually happen when a node goes down during some failures, or when nodes are updated and added as part of the usual deploy operations of the service. These updates happen asynchronously, out of the request path.
Each request dispatched using a Finagle client flows through various modules in a specified order. The modules are logically separated into three stacks: client, endpoint, and connection stacks. In particular, modules in the client stack are in charge of destination name resolution (Binding module) and deciding on which server(s) to route the request to (LoadBalancing module). The Binding module sets the LoadBalancing destination parameter to specify the list of servers that the LoadBalancer can forward a request to. ShardLib inserts a new Router module in between these two modules. The Router module modifies the LoadBalancing destination parameter to filter the list of servers that the LoadBalancer should forward the request to, based on the sharding metadata for the request.
The Router module listens to downstream node updates, retrieves sharding related metadata, and proceeds based on the situation:
After determining the placement details, the Router module then uses its per-service placement knowledge to decide which downstream service’s shard(s) the particular request is sent to.
Because the client can respond to downstream sharding scheme changes dynamically and adjust the request fanout strategy, we can change the sharding scheme of the downstream without worrying about redeploying the client services. For this purpose, the ShardLib client maintains logic to distribute requests between multiple sharding schemes since two sharding schemes can be active at the same time during resharding. It uses a weighted random balancer algorithm where weighting is based on the minimum number of replicas present for each shard of a particular sharding scheme.
Migrating the previous ads-serving service-to-service communication architecture to ShardLib had its own set of challenges. The rollout plan needed to be gradual without any downtime on any of the onboarded services. Shutting down traffic to services and redeploying the ads services was not an option.
To ensure a smooth migration, we integrated the server portion of ShardLib into ads-selection service while ensuring backwards compatibility. As described above, the library does a sharded service announcement that has a different ZooKeeper serverset for the service than the individual per-shard ZooKeeper serversets used previously. We had to keep both the legacy service announcement and the new sharded service announcement when deploying ads-selection service. The legacy announcement is for backwards compatibility of upstream clients (the various ads bidder services) before they onboard onto the sharded client. The other aspect where we had to maintain backwards compatibility is around the usage of the placement scheme in ads-selection. This was relatively straightforward, since we refactored the existing logic to use the library-provided placement scheme instead of the ad hoc management of sharding related logic we had in the earlier system. We deployed the services with the same sharding scheme (same sharding key hash function and sharding key ranges) as the legacy system. Thus, we could verify the correctness of a sharded server onboarded to ShardLib by simply verifying that the old and new instances had indexed identical data in memory.
Once ads-selection service was 100% onboarded as a sharded server, we converted ads-video service, one of the upstream clients of ads-selection, to use the sharded client portion of the library. Since ads-selection has multiple ads bidder services as clients, however, with the rest of the bidders using the legacy clients with a slightly different request/response structure, we had to enable support in ads-selection service for both old and new kinds of requests during the migration period.
After the ads-video bidder migration was completed, we proceeded to onboard each of the remaining bidders (ads-takeover, ads-map, and ads-default bidder services) as sharded clients of ads-selection, one by one onto ShardLib. Naively, one might expect subsequent bidder service migrations to be simpler and quicker because of previous learnings. But as we discovered during the process, each bidder service had evolved to set up its sharding logic in a conceptually similar fashion, but using slightly different code structure. Thus, the testing and correctness verification process for each bidder migration often became the most time-consuming step, as the onboarding process also required us to fix code discrepancies between the services.
Similarly, after onboarding all bidder services as sharded clients of ads-selection, we started onboarding each bidder as a sharded server, since each bidder was itself sharded. This step turned out to be relatively straightforward compared to the previous client migration, as server-side logic for sharding is much simpler than the client-side logic.
Finally, we onboarded Admixer to use sharded clients to connect to each of the bidder services. This step turned out to be one of the more interesting client migrations onto ShardLib. Some of the Admixer-to-bidder communication was simple because Admixer would simply communicate with all downstream shards, that is, use a full-range pruning intent. A few of the bidders, however, including the legacy default bidder, have an additional functionality of skip sharding, where for some types of requests Admixer skips some shards and sends requests only to a subset of the bidder shards, based on historically profiled performance metrics and some additional predictive modeling. Instead of making more invasive changes to support this feature in Admixer, we added first-class support in ShardLib to allow for a skip-sharding pruning intent, where the sharded client can take in a list of shards to skip.
ShardLib unified the language and code used to communicate between ads services with different sharding schemes. Sharding schemes of such services can be discovered consistently now, with the centralized concept of placement. In addition to decoupling service-to-service communication, ShardLib was also able to provide a framework to experiment with different sharding schemes in a faster and controlled way. A lengthy error-prone operational process is no longer needed to change any service’s sharding scheme in the layered ads service communication stack. When compared to Figure 1, it’s clear how simplified the Shardlib architecture is, as illustrated in Figure 2.
If you're interested in solving such challenges, consider joining the flock.
This project and the subsequent migration and onboarding would not have been possible without the commitment and cross-functional alignment of many teams. We would like to thank the project team who also contributed to this blog: Gerard Taylor, Girish Viswanathan, Jean-Pascal Billaud, Jesus Sevilla, Jim Sukha, Praneeth Yenugutala, Shanthi Sankar.
And others who contributed to this project: Akshay Thejaswi, Andrei Savu, Arun Viswanathan, Christopher Coco, Corbin Betheldo, Dharini Chandrasekaran, Eitan Adler, James Gao, Juan Serrano, Kavita Kanetkar, Marcin Kadluczka, Michal Bryc, Moses Nakamura, Nikita Kouevda, Pawan Valluri, Ratheesh Vijayan, Srikanth Viswanathan, Styliani Pantela, Tanooj Parekh, Udit Chitalia, Yufan Gong.
We would also like to thank the Revenue SRE team and Revenue Product and Engineering leadership team for their constant support.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.