Infrastructure
Stability and scalability for search
By
and
Friday, 14 October 2022
The Search Infrastructure team’s goal is to provide a low-friction, self-service platform that simplifies and accelerates the end-to-end journey of creating and iterating on a search experience.
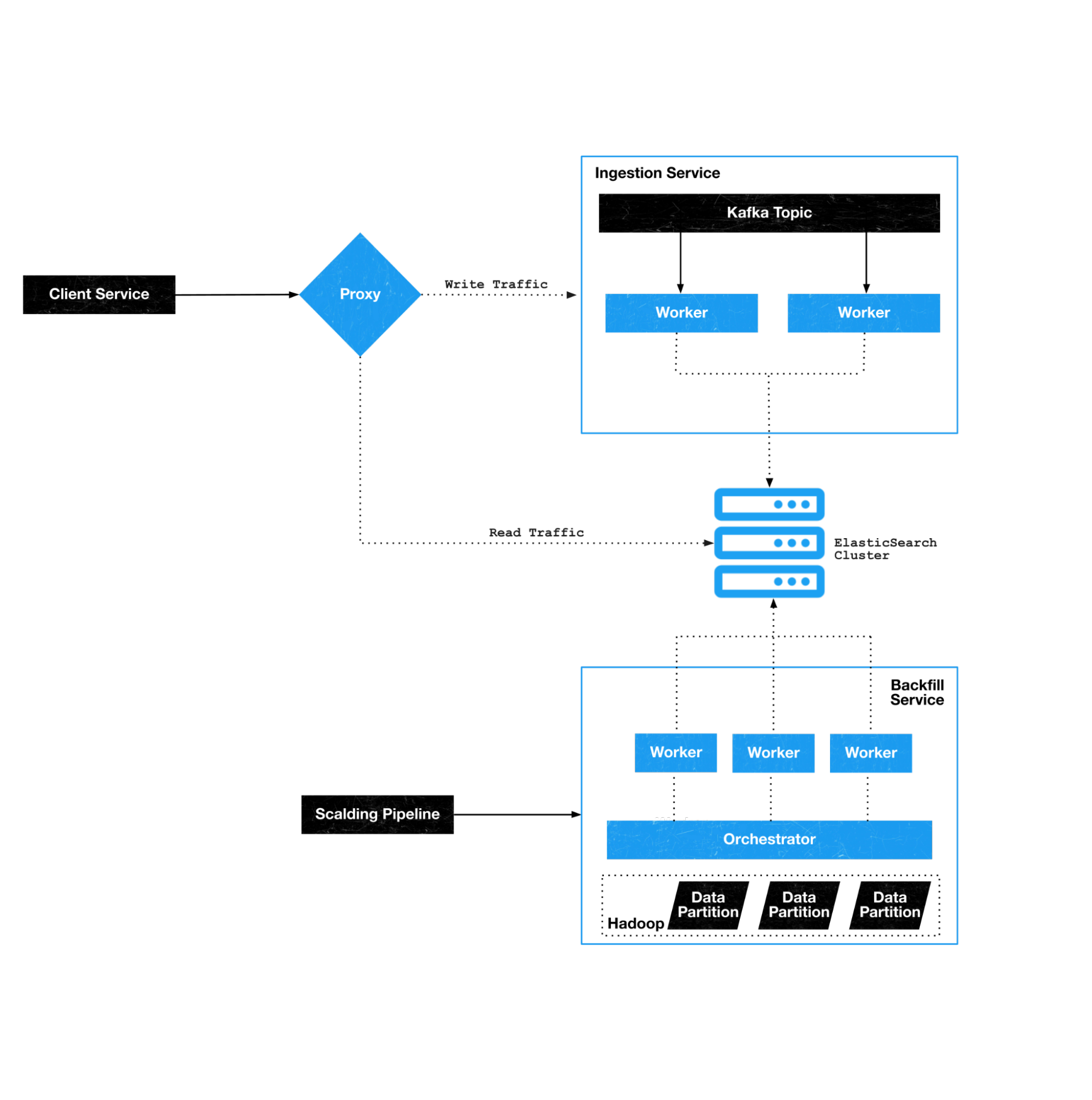
We power real-time search for Tweets, Users, Direct Messages and more! As a platform team, operating at Twitter scale, it is crucial to offer a high level of stability and performance to our customers. To accomplish this, for a portion of our use cases, we use Open Distro for Elasticsearch. This blog will explain the work we have done, in addition to what Elasticsearch provides, to make sure our product teams at Twitter can scale quickly and efficiently for our customers. To improve the search experience at Twitter, we added a proxy to Elasticsearch, and created an Ingestion Service and Backfill Service.
Elasticsearch is a search engine based on the Lucene library. It is a popular open source tool widely used in industry and is known for its distributed nature, speed, scalability, and simple REST APIs.
The Search Infrastructure team builds infrastructure to host search as a service. Since we are such a central infrastructure team, we need to maintain a high level of stability and performance for our customers. Our team exposes all Elasticsearch APIs because they are powerful, flexible, and well-documented. We then provide plugins and tooling to ensure compliance and easy integration with Twitter services.
Before we added the proxy, our customers interacted directly with Elasticsearch for everything. This included querying and indexing, request monitoring, and metrics collection. A custom plugin handled extra Twitter privacy and security rules and exported additional metrics such as overall success rate and latency.
Under normal workloads, interacting directly with Elasticsearch typically was not an issue, but at Twitter-scale this quickly proved to be a bottleneck. This design made it easy to bring down a cluster with excessive traffic (ingestion traffic being the most demanding traffic in our case).
It was clear that we needed a solution to stabilize Elasticsearch in a way that was transparent to our customers – a way to flexibly route and throttle requests, while providing security and visibility of the cluster.
To improve the connectivity to and observability of Elasticsearch clusters, we introduced a reverse proxy to Elasticsearch. The proxy separates read and write traffic from our clients. It is a simple HTTP service which adds an extra layer between our customers and their Elasticsearch clusters. The proxy handles all client authentication and acts as a front end to the Ingestion Service, which handles write traffic.
This design creates one entry point for all requests. It also provides additional metrics and supports flexible routing and throttling. This makes it easier for our customers to build solutions with out-of-the-box features. By adding this service in front of Elasticsearch, we can collect better metrics for request types, success rate, read and write requests, cluster health, and more.
Twitter’s goal to serve the public conversation faces unique challenges at scale – one such being the type of traffic Twitter (and subsequently a Search Infrastructure service) receives. The public conversation can change quickly and bring lots of user search requests with it. This means we often face large spikes in traffic to our services.
When traffic spikes, the standard Elasticsearch ingestion pipeline cannot keep up with Twitter’s scale. By default, the common safety mechanisms for traffic spikes (queuing, retrying, and back-off) are left to the client to implement and set up. The pipeline does not have auto-throttling or degradation mechanisms. So, when a spike happened, we noticed that Elasticsearch struggled to handle a heavy ingestion load. This led to increased indexing and query latency. In the worst cases, traffic spikes caused total index/cluster loss as all resources were consumed trying to keep up with the increased load.
To meet these unique demands, the Search Infrastructure team implemented the Ingestion Service to gracefully handle Twitter’s traffic trends. The Ingestion Service queues requests from the client service into a single Kafka topic per Elasticsearch cluster. Worker clients then read from this topic and send the requests to the Elasticsearch cluster. The Ingestion Service then does the following to smooth out the traffic to the cluster:
By using this process, a spike is less likely to overload a given cluster, without introducing too much latency into the ingestion pipeline.
At Twitter, we refer to any large data operation that adds missing data as a “backfill”. Just getting started with an empty Elasticsearch cluster? Adding or updating a field in your schema? Data missing from some downtime? These are just some of the most common reasons that we may need to perform a “backfill”.
A backfill often operates on the scale of several, sometimes even hundreds of terabytes of data and millions, or even billions, of documents. This is A LOT of data for an Elasticsearch cluster to handle coming in at once. And it’s a much higher throughput than we expect from a typical ingestion pipeline. This means backfills can take a long time to run and there is much more opportunity for things to go wrong.
Our old workflow used a custom Scalding (Scala on Hadoop for big data operations – see more here) sink to create an HTTP client, and start sending documents to an OmniSearch index. This workflow opened multiple connections/clients (one per reducer in the Hadoop job) and had no built-in guard rails, as data flowed as fast as it could. Once at scale, this often created issues where the index would fall behind or simply crumple under pressure from all the connections and incoming data. This affected query performance or, in the worst cases, caused the entire cluster to die. Failures often took a long time to surface, and because of the performance issues above, we often couldn’t safely backfill on a live cluster.
As a part of the stability and platform improvements the Search Infrastructure team launched in 2021, we set out to build a solution to the problems we faced. Enter the Backfill Service – a platform-managed service that addresses the above issues by loading large amounts of data safely and efficiently into an Elasticsearch index.
The new Backfill Service is broken into the following parts:
The new Backfill Service provides several key improvements over the old approach:
The following diagram shows how the proxy, Ingestion Service, and Backfill Service interact with an Elasticsearch cluster to improve stability:
Elasticsearch provides a great low-latency, customizable search experience that enables teams at Twitter to easily add search functions to their products. We provide this experience in a convenient, search-as-a-service platform. Operating at Twitter’s scale often pushes Elasticsearch to its breaking point, and can lead to serious instability. By adding guard rails such as the proxy to Elasticsearch, the Ingestion Service, and the Backfill Service, we have been able to maintain uptime, prevent crashes, and keep search running across Twitter products.
This work wouldn’t have been possible without the contributions and support from all members of the Search Infrastructure team at Twitter:
Andrii Nikitiuk, Lesian Lengare, Tom Devoe, Teena Kunsoth, Kareem Harouny, Judy Ho, Elias Muche, Nife Oluyemi, Mallika Rao, Niran Fajemisin
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.