Infrastructure
Kerberizing Hadoop Clusters at Twitter
By
Thursday, 23 February 2023
Ashwin Poojary, Head of Platform Services SRE, @ash_win_p
Sampath Kumar, Senior Site Reliability Engineer, @realsampat
Santosh Marella, Senior Staff Software Engineer, @santoshmarella
Twitter runs one of the largest Hadoop installations on the planet. The use cases Hadoop serves range from general purpose HDFS storage to search, AI/ML, metrics & reporting, spam/abuse prevention, ads, internal tools etc. The diversity in the use cases means Hadoop hosts several large datasets (including some sensitive ones) that are accessed by a variety of internal teams such as engineering, product, business, finance and legal.
As Twitter evolved over the years, so did the Hadoop footprint at Twitter. Tens of Hadoop clusters, with thousands of nodes, hundreds of PetaBytes in logical storage (without replication), running tens of thousands of MapReduce/Spark jobs/day (and many such metrics) has been the norm for a few years now.
Such a battle tested and stable Data Infrastructure Platform has a few challenges:
a) Making any change has a high amplification risk
b) Asking customers to make any code changes to their apps doesn’t scale
c) Cross cluster dependencies develop organically
d) Clusters can’t afford downtime as it affects Twitter’s bottomline.
With the number of Hadoop datasets and jobs growing year-over-year, it became imperative to enforce strong Authentication, Authorization and Accountability for Hadoop data access.
Much like most Hadoop installations, Twitter adopted HDFS’ native Unix-like permission model for authorization from day one. Files/Directories in HDFS are marked with LDAP user/group ownership and access permission bits. The ownership on nested directories is revisited from time-to-time to enforce least privilege based access.
For accountability of Hadoop data access, Twitter uses HDFS audit logging, which is also a natively built-in HDFS feature. As users perform various HDFS operations (list directory, file open, read, delete etc), the user’s LDAP name, IP address are logged along with the resource accessed and the operation performed.
Strong authentication, however, had been a tough puzzle to solve at Twitter, due to the challenges outlined in the above section. While Hadoop natively supports Kerberos based authentication, turning it ON on several Hadoop clusters at Twitter without taking downtime, or avoiding large coordination efforts required some creative thinking, testing and gradual execution.
Several systems at Twitter use Kerberos for authentication. So, luckily we had a Kerberos Key Distribution Center (KDC) pre-existing when we set out to Kerberize Hadoop. However, the scale of Hadoop meant KDC had to be ready to notch up in scale as well.
Tens of thousands of additional service principals (for Hadoop Services)
Thousands of client principals for service accounts (for Hadoop clients)
Hundreds of additional QPS(Queries per second) to KDC due to auth/service-ticket requests
Thanks to the KDC team at Twitter, these numbers (along with other similar requests from other teams) were easily accommodated with some tuning to the master KDC, and adding some replicas.
In addition to KDC, Hadoop kerberization required tooling to place the requests and secure distribution of keytabs to appropriate host destinations. Twitter’s platform security team received multiple similar requests from other teams that were trying to enforce strong authentication between services. A keytab generation service and a secure material distribution service were developed to help teams request for keytabs and tag the appropriate host destinations to distribute them to. The APIs were flexible to develop additional tools on top of these, such as generation of per-host keytabs and a web UI to make this self-service for our internal teams.
One of the design principles we’ve chosen while kerberizing Hadoop at Twitter was to use per-host service principals (of the form fooService/bar.host.com@baz.domain). The reason for this choice is simple - reduce the blast radius in the event a host gets compromised.
However, the Hadoop NameNodes are configured for High Availability via a Zookeeper based failover mechanism between the active and standby NameNode instances. So, when the active NN fails over and the standby is promoted to serve the requests, the Hadoop clients start connecting to the now active NameNode. If 1000s of clients are connected to HDFS and the NameNode fails over, it can easily flood the KDC with service ticket requests for the newly active NN. To prevent this, we’ve chosen to relax usage of per-host principals for NNs, and instead chose to use the exact same service principal for both the NNs (e.g. namenode/hadoopClusterOne@DOMAIN.COM).
A kerberized service instance expects all its clients to present valid kerberos service tickets for the service instance (this in-turn requires the clients to perform a successful kinit and obtain a valid TGT from the KDC). Client connections that fail to prove their kerberos credentials are simply dropped.
With 100s of teams accessing Hadoop and 1000s of jobs running in the clusters every day, this simply meant ALL of them have to be kerberos ready before Hadoop services are kerberized.
Another option was to modify Hadoop services to “fail-open” or have a “whitelist” of users. Both these options initially sounded promising, but had a few of cons associated with them:
MicroServices with 1000s of instances are common at Twitter. Several of them run with an embedded Hadoop client library in order to interact with Hadoop. Kerberization of Hadoop requires that all these microservices be kerberized. i.e:
All instances of a service foo running as unix-user bar, needs to have a kerberos keytab with principal for bar on all the 1000s of hosts the service instances are running on.
All the instances are restarted and kinit’ed from bar’s keytab, in-order to make successful calls to a kerberized Hadoop service (or be ok to take a hit on service’s QoS)
Restarting a service with thousands of instances is a large, coordinated effort that could sometimes take a few days (due to other dependencies on the service). “Hadoop kerberization” event, where we say “Hadoop will be kerberized on this day and you need to restart all your service instances following it”, simply doesn’t fly when you have multiple services that have thousands of instances.
Another challenge at Twitter was that there are tens of Hadoop clusters and by no means we could kerberize them all in a single major deployment, even by taking a down time. Therefore, we had to plan for the situation where some clusters are kerberized and some are inevitably not. So, what happens when a job that runs in a non-kerberized cluster wants to access data from a kerberized cluster? Obviously, those calls will fail (as kerberization is an all-or-none deal).
We tried to lay down a graph of these cross-cluster dependencies and see if there are any access patterns that can help us chalk out a kerberization order. However, it looked pretty bad, as there were several cyclic dependencies that were harder to disentangle. Moreover:
One possibility we considered (before we fully understood the cross-cluster dependencies) was to stand up a set of kerberized clusters and migrate the use-cases from non-kerberized to kerberized clusters. The biggest pro in this approach is that we don’t need to worry about “what would break”, as we are starting on a clean slate. The downside is that we face a long-tail of migration and additional CapEx and OpEx. Also, once we discovered the cross-cluster dependencies were too many, this option quickly fizzled out as there was no way any cross-cluster use cases would work when one of the clusters is kerberized and the other is not.
Hadoop actually has a component called HttpFS that basically exposes a REST proxy interface via which http clients can interact with HDFS. Taking a cue from it, we thought about developing a proxy that enforces strong authentication on its clients (need not be kerberos auth), but talks to Hadoop using the end-user’s kerberos credentials.
This approach solves the problem of not needing the Hadoop clients (1000s of them) to be kerberized, but shifts the problem to still make them strongly authenticate with the proxy (via, say, s2s). The “cross-cluster dependencies” problem still exists, though. Another drawback is that a proxy host compromise has a very large blast radius, as it compromises the keytabs for every single HDFS user.
Taking downtime on one cluster seemed reasonable to start with. But the cyclic dependencies meant we needed to take downtime on multiple clusters simultaneously, which was a huge risk to undertake.
After much dwelling, we took a multi-pronged approach to deal with the constraints and develop code changes, strategies as needed.
The following were our guiding principles:
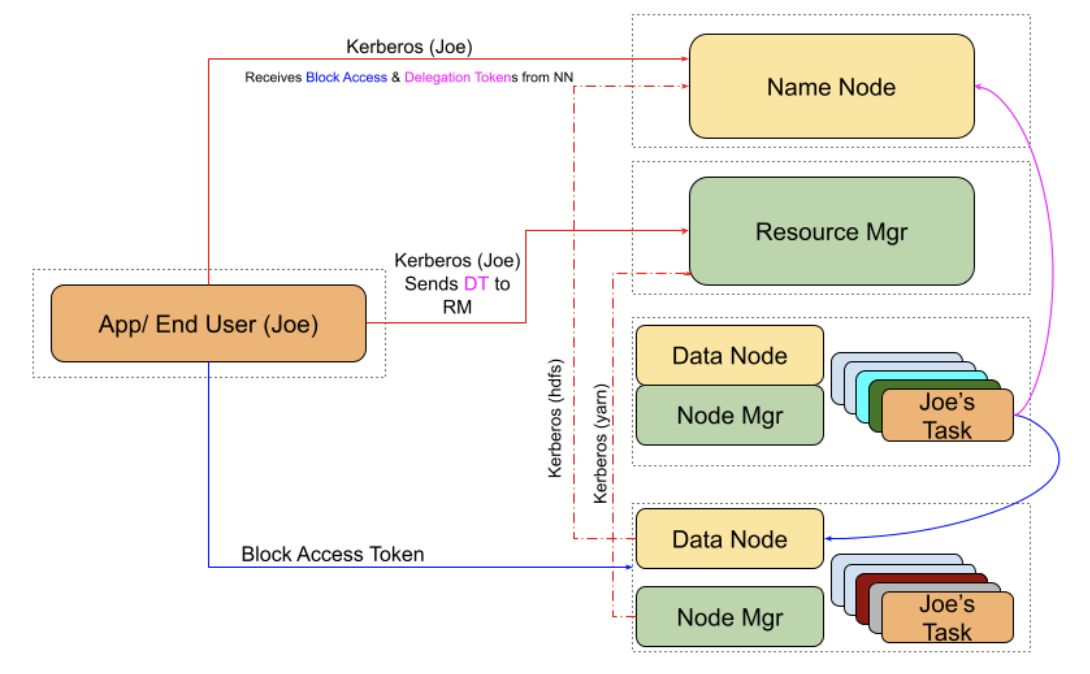
Typically Hadoop requires any application that uses kerberos keytab to execute UserGroupInformation.loginUserFromKeytab(keytabPrincipal, keytabPath) in order to authenticate with KDC (i.e. perform kinit from keytab). When any of the Hadoop operations are later performed (e.g. list files under a directory or submit a MapReduce job), the Hadoop RPC layer, picks up the TGT and obtains an appropriate service ticket in order to talk to one of the Hadoop services (NameNode/Resource Manager).
At Twitter, services that talk to Hadoop take compile time dependency as well as runtime dependency on the Hadoop client library. The services also pick up the Hadoop configurations (core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml) at runtime. Therefore, as long as the client library changes are API compatible, it is safe to deploy a new client library version to all the hosts at Twitter, without breaking the Hadoop client applications.
With this in mind, we decided to enhance the UserGroupInformation.getLoginUser() and introduce the notion of auto login the user from the user’s keytab, should one exist at the standard location on the host where the user application is running. The standard location is typically a location on the local filesystem at which the keytab distribution service drops the keytab. The path to the keytab can easily be constructed from the application’s unix user name. The functionality simply performs the following:
Additionally, the HDFS audit logs typically show the UGI of the calling user. E.g. if foo unix user performs a directory listing, and foo has kerberos credentials, the audit log could read something like (these timestamps are not real):
Without kerberos credentials, the same call on a kerberized cluster’s HDFS audit log would read:
Without kerberos credentials, the same call on a non-kerberized cluster’s HDFS audit log would read:
The capability to auto-login from keytab, clubbed with the ipc.client.fallback-to-simple-auth-allowed=true setting and HDFS audit logging, helped us to get a high leverage in kerberizing 100s of 1000s of Hadoop client applications. Where applications were still not kerberized, it was easy to query them from HDFS audit logs and reach out to the owners of those applications (usually being less than 10 teams).
With the ipc.client.fallback-to-simple-auth-allowed=true setting, kerberized client applications can submit jobs to a kerberized cluster and access data from a non-kerberized cluster. For e.g. a DistCp job can be launched in a kerberized cluster and it can copy data from a non-kerberized cluster.
However, kerberized client applications cannot launch jobs in a non-kerberized cluster and read data from a kerberized cluster. This is because, beyond the initial kerberos based authentication, HDFS uses Delegation Tokens for applications like MapReduce to call into the HDFS Name Node when the MapReduce tasks execute, without requiring the tasks to authenticate with the KDC again (doing so would flood KDC with auth requests).
The Delegation Tokens are renewed by Resource Manager, immediately after a job is submitted as well as when a token is about to expire (up to a configured max lifetime).
Consider a kerberized client application, running as user kerbFoo, submitting a job to a non-kerberized Hadoop cluster nonKerbHadoop and wanting to read data from a kerberized Hadoop cluster kerbHadoop:
With the above understanding, we simply needed to make some changes to this delegation token renewal flow, which seems to be executed only when security is turned ON (i.e. when hadoop.security.authentication=kerberos). By doing so, we pass the delegation token obtained from a kerberized HDFS cluster to a non-kerberized Resource Manager. This doesn’t weaken the security posture, as we started off with no kerberization at all, and the token is still protected with HDFS ownership and permission bits.
When the cross cluster jobs are submitted, the MapReduce job submission flow allows obtaining delegation tokens for all the MapReduce input and output directory paths. However, since the HDFS paths at Twitter are backed by ViewFS, which mounts all the accessible HDFS clusters from a source cluster, the call to get a FileSystem object for a job’s input or output HDFS Path would result in obtaining a FileSystem object that is essentially a composite of other FileSystem objects for each accessible HDFS cluster. This resulted in every single M/R job submission sending out HDFS delegation token requests to every single HDFS cluster!
We added an API to FileSystem called getTargetFileSystem(final Path p) which returns the FileSystem that’s hosting a given Path, and called this method for the M/R input and output dirs.
With the client library changes plugged into the Hadoop applications, and ipc.client.fallback-to-simple-auth-allowed=true set for both end-user applications and Hadoop services, we were almost ready to kerberize one Hadoop cluster at a time. We came up with the following rough rollout sequence to help us with minimal disruption to customer use cases, minimal YARN downtime and zero HDFS downtime:
The rollback sequence is opposite of the rollout sequence. However, the rollback doesn’t need to be executed fully, and hence is a much quicker step. We simply needed to un-kerberize the Journal Node, Name Node, ZKFC, Resource Manager, Job History Servers and Shared Cache Manager processes. These are < 10 hosts in a cluster compared to thousands of Node Manager/Data Node hosts.
With the above mentioned solutions and rollout steps in place, we could carry out the kerberization process one-cluster-at-a-time and do it in-place without much disruption to use cases (job submissions to our clusters automatically retry in case of a failure).
The HDFS audit logging capability helped us much to know well in advance, which client applications were already kerberized and which were not. This gave an easy path forward to have meaningful tracking and discussions with the teams and get them ready for the deployment days.
The rollout steps were well documented after a couple of initial clusters (huge thanks to our site reliability teams for streamlining it.) This gave us good confidence in the repeatability of the whole process.
The success ratio at the end was very high, with the number of unique failures after a deployment being extremely low.
The Hadoop Kerberization project was a long, tedious effort at Twitter at the outset. However, as we dwelled in the problem space understanding the constraints and set out a few guiding principles, we were able to come up with optimal changes and processes that ultimately set us up for success, saving millions of dollars to the company (comparing with having to stand up parallel kerberized clusters), several man hours in operations, planning and execution.
A long list of folks to thank for ideation, collaboration and partnership, including but not limited to - Abhishek Jagannath, Aline Bandak, Andre Pinter, Anil Sadineni, Bill Dimmick, Chris Trezzo, Chris Petrilli, Daniel Templeton, Dave Beckett, Derek Lyon, Doyel Sinha, Drew Gassaway, Evgenii Seliavka, Heesoo Kim, Jeremy Inn, Joep Rottinghuis, John Yeh, Lakshman Ganesh Rajamani, Lohit VijayaRenu, Manjunath Shettar, Mark Schonbach, Maziar Mirzazad, Navin Viswanath, Ran Wang, Shashank Singh, Srinivas Inguva, Tray Torrance, Tripati Subudhi, Vignesh Ganapathipalayam Swaminathan, Vrushali Channapatan, Xiaoyang Ma and Zhenzhao Wang.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.