Insights
How Twitter deploys its widgets JavaScript
By
Wednesday, 21 September 2016
Deploys are hard and it can be frustrating to do them. Many bugs manifest themselves during deploys, especially when there are a large number of code changes. Now what if a deploy also goes out to millions of people at once? Here’s the story of how my team makes a deploy of that scale safely and with ease.
Publishers on the web use a single JavaScript file, widgets.js, to embed Twitter content on their website. Embedded Tweets, embedded timelines, and Tweet buttons are powered by the same JavaScript file, making it easy for web publishers to integrate widgets into their websites. We update widgets.js weekly, deploying bug fixes and adding features without requiring our publishers to do any work to receive the updates.
But to ensure things stay simple for our customers, we need to take on some of the complexity. Specifically, we need to deploy a single, unversioned, well-known, static asset which publishers trust to run within their page. This code is executed roughly 300,000 times a second by over a billion visitors every month. We know this is a big responsibility for us and that’s why we recently invested in upgrading the widgets.js deploy process to catch mistakes early, and avoid negative customer impact.
We began this project by cementing what an ideal deploy would look like. Specifically, we identified three qualities of a safe deploy that we were after:
These were the goals we set for ourselves. Now, let’s dive into the details of how we accomplished them.
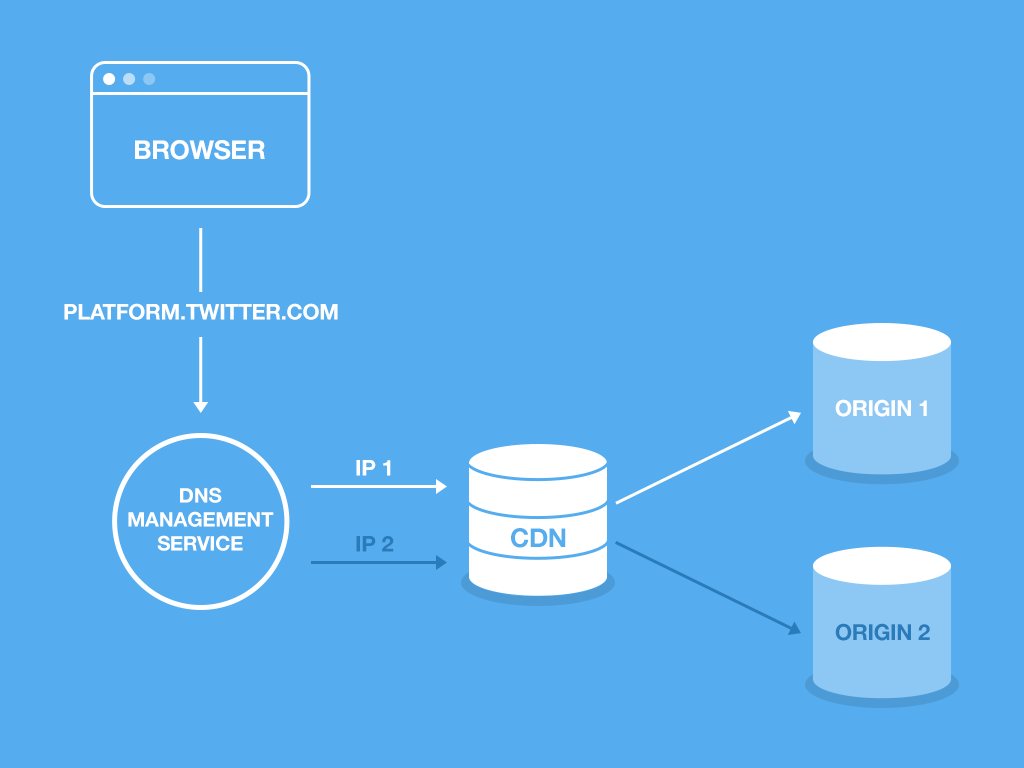
Because widgets.js is a well-known asset (platform.twitter.com/widgets.js), it has no versioning in its file name which makes it harder to control the progress of its deploy. The way we decided to control the release of a new version of this file is by controlling how our domain, platform.twitter.com, gets resolved at the DNS level. This way, we can set rules to resolve the file to either the new version, or the old version, during the deploy.
Deploy architecture
To implement such control over our DNS, we had to configure three components:
DNS Management service: This is a service that lets us control how platform.twitter.com gets resolved to an IP address. We use geographic regions to control the roll-out, based on the following three rules, which correspond to each phase of the deploy:
Phase 1: 5% of traffic from Region A gets IP2 and others get IP1.
Phase 2: 100% of traffic from Region A gets IP2 and others get IP1. Repeat for increasingly larger regions.
Phase 3: 100% of all traffic gets IP2. This includes TOR traffic and any requests that we could not identify what region it is coming from.
CDN (Content Delivery Network): This is a service that helps serve our static assets in a performant manner. Ours is configured so that if a request is made through IP1 it’ll serve the asset from ORIGIN 1, otherwise ORIGIN 2.
Origin: A storage service, like Amazon S3, where widgets.js is uploaded. CDN asks the origin for the latest version to serve.
The default state is that all requests are served by the asset in ORIGIN 1. A deploy starts with uploading a new version of widgets.js to ORIGIN 2. Then we start moving traffic to ORIGIN 2 by going from Phase 1 to 3, as described above. If the deploy is successful, we copy assets from ORIGIN 2 to ORIGIN 1 and reset all traffic to ORIGIN 1.
Our goal was to execute a safe deploy, so let’s evaluate how we did. By having 2 origins, we were able to rollback instantly – a rollback here is moving all traffic back to ORIGIN 1 where we have the previous version of widgets.js. The geography-based deploy gave us a way to incrementally rollout the new version and only move forward if it was safe to do so. Lastly, our client code logs the release version, so we were able to build real-time graphs that told us if the deploy was successful or not.
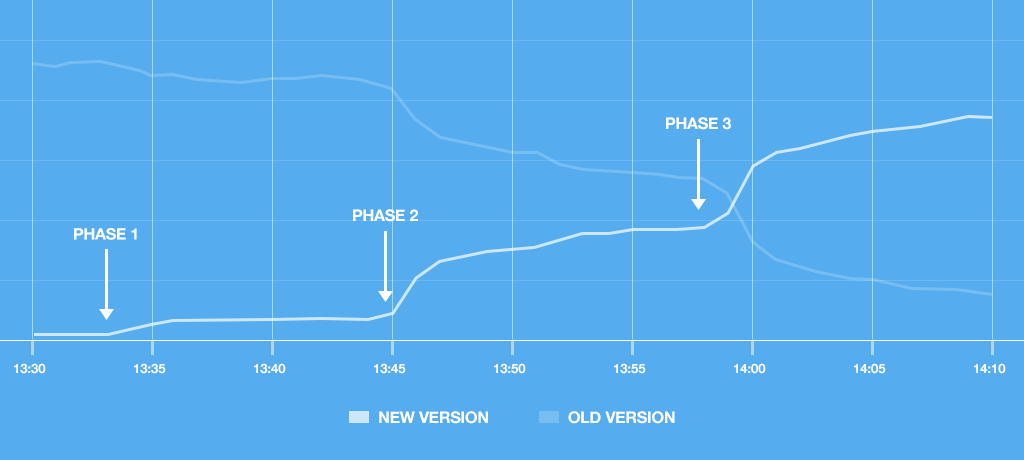
A successful deploy looks like this today:
Traffic changes of the new and old version during a successful deploy
We have used this deploy process for nearly a year now, and detected several regressions earlier than we would have previously. For example, we recently had a bug in our code where a lazy loaded JavaScript file was incorrectly addressed which resulted in our widgets not rendering completely. But thanks to this deploy process, we quickly saw the impact and were able to address it before it affected customers widely.
We have big ideas on what we can improve for the next iteration. One thing we have learned is that our DNS rules could be better. We would like Phase 1 to be a small but significant number of users to give us quick insight into critical regressions. In Phase 2, we would like the sample of users to be bigger to catch more subtle bugs that show up only at scale. Matching our phases to these goals requires some tuning of DNS rules which is an area we want to invest going forward.
Another area we would like to improve is the total deploy time. With so many moving pieces, our deploy time has increased from a few minutes to a couple of hours, and this is mostly because we have to wait for all intermediate caches to invalidate each time we move traffic from one phase to another.
We would also like to add performance metrics in the future, so we can expand our release verification from raw successes/failures to deeper performance insights such as render times in different locations around the world.
We use external vendors for CDN and DNS management and all the configurations that I describe here at the DNS level use publicly documented APIs that you can use for your deploys today. Overall, we are very happy with how the new deploy process works for us today because it has emboldened us to ship updates more often while still keeping things simple for publishers.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.