Insights
Moving Top Tweet Search Results from Reverse Chronological Order
By
Monday, 19 December 2016
Twitter is live and real-time, so naturally Twitter search must surface recent, yet still relevant, results. Historically, these search results have been largely presented in reverse chronological order. In many cases however, the most recent results may not be what the searchers are looking for. They could be searching for popular Tweets to engage with or to better understand context around the search query, and the most recent Tweets are not necessarily best suited for that. In order to improve this experience, over the last few months we’ve adjust the top tab of your Twitter search results page to start with relevance-ordered Tweets (rather than time-ordered Tweets). We retrieve Tweet candidates from various sources within a larger time range and rank them with a machine-learned model.
We performed several experiments with the following variables:
Through experimentation, the major challenges we faced were:
The Twitter search results page has a blend of various result types: Tweets, accounts, news, related searches, etc. We often encounter the problem where if we increase the quality of one result type (and subsequently raise the position at which it is shown), we end up losing engagements on other result types. This is especially evident in the case of Tweet results vs. account results.
Initially, we experimented with showing a gallery of Tweet results instead of individual Tweets and observed a negative impact on the engagement metrics of account results. The Tweets gallery would take up a lot of space at the top of search results page, which consequently drops the accounts gallery (if there is one) to a much lower position because it can’t appear between the relevance-ordered Tweet results. In a later iteration, we observed that showing individual Tweet results allows us to improve overall engagement while not heavily hurting the metrics related to account results so we decided to move forward with the individual Tweets layout.
To further avoid losing account engagements, we made score adjustments so that the range of Tweet scores do not overpower the accounts. We also implemented logic to adjust the scoring and positioning of Tweets and the accounts gallery based on whether the query has an inferred intent to search for accounts.
We noticed from early iterations of the experiment that Tweets with media content (images and videos) tend to receive more engagements and be ranked very high. This was good in bringing popular Tweets to the top of the search results but it also meant several non-media Tweets were pushed down too much. In fact, we observed a negative impact on overall search engagements.
Because Tweets with media content are auto-expanded, they are usually much larger than non-media Tweets and take up more space on the search results page. Assuming that people have some subconscious limit to their scroll span, we end up showing them fewer results, and they will potentially miss out on many good non-media Tweets. This same point can be applied to a person’s attention span with regards to time – people usually take more time to consume media Tweets. In some sense, we would like to optimize for the sum of relevance scores per page (relevance density). As illustrated in the example below, presenting three Tweets with good relevance scores (left) results in a higher sum of relevance scores per page than presenting one Tweet with the highest relevance score (right). To remedy this issue, we experimented with different diversification methods and adjusting the weights of features in our ML model that are related to Tweet render size.
Figure 1. Relevance density comparison. The layout on the left shows three Tweets with relevance score in the red box. The Relevance density (sum of relevance per page) is 0.9. The layout on the right shows one Tweet with large media area, and therefore, its relevance density is 0.7.
The problem here is a manifestation of the more general Search Result Diversification problem. The key observation is that the relevance of a set of Tweets depends not only on the individual relevance of its members, but also on how they relate to one another. For example, we should not show many Tweets with the same video or from the same author. Ideally, the Tweet set should properly capture various attributes about the query and account for the interests of the overall population. We are currently working on different methods to further diversify our search results.
A person’s behaviour on Twitter provides an invaluable source of relevance information. This data contains both attributes about the Tweets shown and the consumer’s reactions to them. Using this information, we can train machine learning models that predict how likely a Tweet is to be engaged with (Retweets, likes and replies). We can then use these models as scoring functions for ranking by treating the probability of engagement as a surrogate for the relevance of Tweets.
However, the information in scribe logs (used for training our models) is very biased. A key source of bias is the presentation order: the probability of engagement is influenced by a Tweet’s position in the result page. To adjust for this positional bias, we factorize the observed engagements at a position to two terms: one describes the perceived relevance of a Tweet and the other captures positional bias (1). Building on top of this, we devised a simple heuristic to assign relative importance to training examples, which proved to be very effective in practice.
The scribe logs are also noisy. We essentially use the implicit feedback inferred from people’s behavior (e.g., likes), which might not accurately indicate their preference to Tweets. For example, a person may accidentally tap on the “like” button while scrolling down the page. Another example is that one Tweet may be engaged by some people but not by others, resulting in opposite labels in training. This is especially problematic for low complexity models as they do not have the capacity to capture real signals from noises. We have tried several denoising methods and smoothing techniques to deal with the implicit noise in data and obtained models with very good performance.
Overall, we’ve observed that people who have experienced this new Search results page tend to not only engage more with the Search results but also Tweet more and spend more time on Twitter.
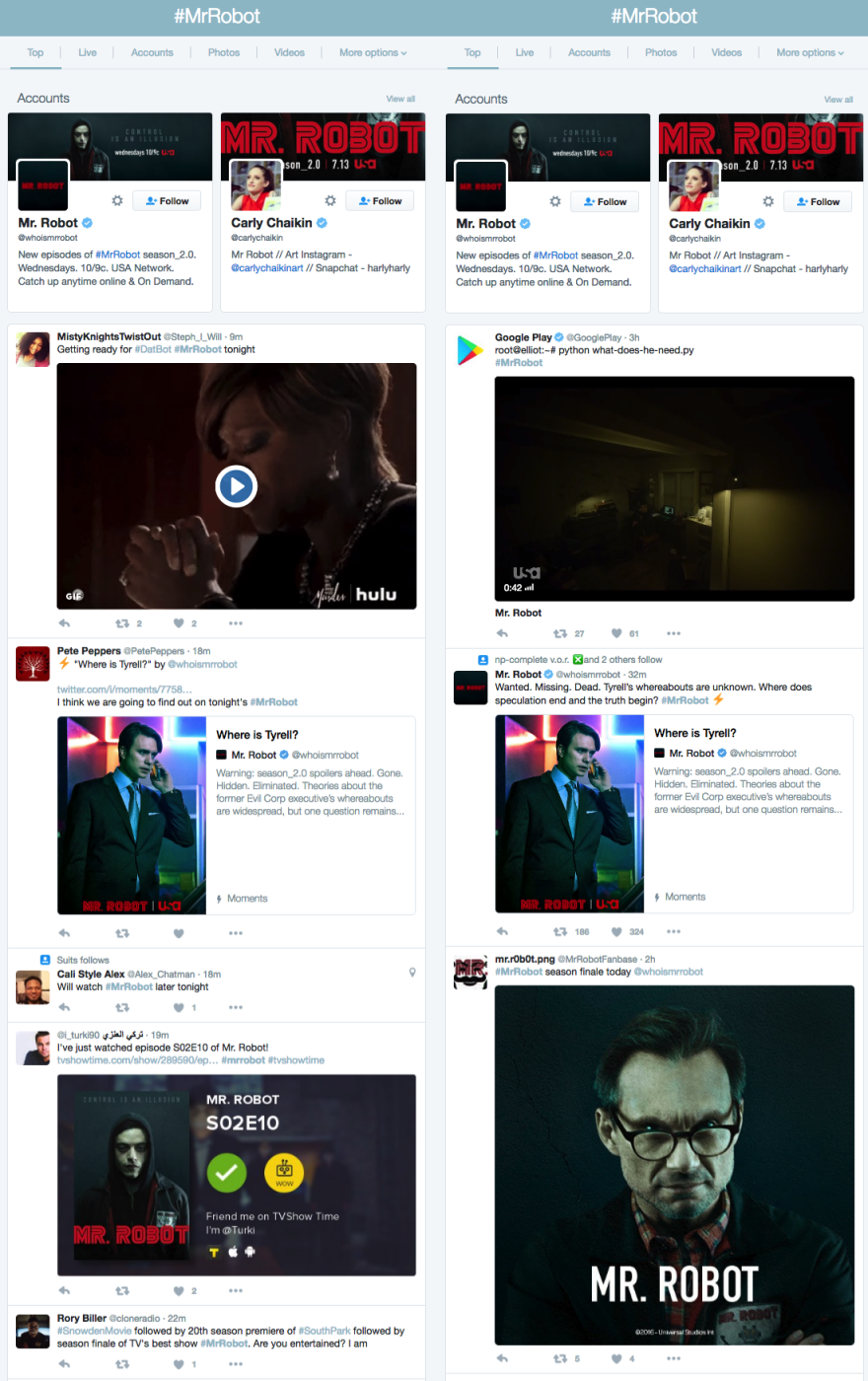
Here is an example before (left) and after (right) search for #MrRobot around the time of the launch:
This launch sets us up for further relevance-based experimentations and improvements that we look forward to shipping to people in the future!
Acknowledgements
Lisa Huang, Yan Xia, and Tian Wang worked on this project with lots of support from the rest of the Search Quality team: Yatharth Saraf, Juan Caicedo, Jinliang Fan, and Gianna Badiali. We would also like to thank the Search Infrastructure team for all of their assistance.
(1) We were confident this methodology would work based on reviews of academic experimentation on the issue. See, for example, in An Experimental Comparison of Click Position-Bias Models
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.