Insights
Productionizing ML with workflows at Twitter
By
and
Friday, 22 June 2018
Cortex provides machine learning platform technologies, modeling expertise, and education to teams at Twitter. Its purpose is to improve Twitter by enabling advanced and ethical AI. With first-hand experience running machine learning models in production, Cortex seeks to streamline difficult ML processes, freeing engineers to focus on modeling, experimentation, and user experience.
Machine learning pipelines were run at Twitter through a series of scripts or ad-hoc commands. Training and serving a model meant manually triggering and waiting for a series of jobs to complete or writing a collection of custom scripts to do so. Example jobs include extracting, transforming, and loading data, as well as training, validating, and serving models.
The process of managing and triggering machine learning pipelines presents problems that can impact the quality of models. Firstly, it reduces the frequency in which models can be retrained by creating unnecessary overhead and causing frequent errors. Each full run of the training pipeline requires active monitoring from engineers in order to trigger next steps and remedy issues with the data or scripts. Secondly, it reduces the rate of experimentation and tuning that can be done to improve the model. For example, in order to tune the hyperparameters of a model, engineers would have to manually trigger, manage and record results from multiple runs of a machine learning pipeline. This tedious and repetitive task reduces engineering productivity and slows iteration time.
In an effort to reduce the cost of maintenance of production machine learning pipelines, improve engineering productivity, and increase the rate of experimentation, Cortex developed ML Workflows: a tool designed to automate, schedule, and share machine learning pipelines at Twitter.
When we started building ML Workflows, our philosophy was to create a simple solution that would solve most ML needs while reusing existing components and open source technologies. Rather than reinvent the wheel, Cortex evaluated technical solutions based on a simple Python API to describe workflow DAGs paired with a backend job execution system.
After careful consideration of open-source projects, such as Luigi or Azkaban, as well as internal solutions, we picked Aurora Workflows and Apache Airflow as the frontrunners.
Why Airflow?
Aurora Workflows is an orchestration engine part of our company’s continuous deployment efforts. It supports full automation and is used to coordinate test and release stages across Aurora and CI (Jenkins) jobs.
Apache Airflow is an open source technology for creating, running, and managing data pipelines. It has a powerful UI to manage DAGs and an easy to use API for defining and extending operators.
Despite Aurora Workflows being integrated, we chose to base our product on Airflow as it:
Integration at Twitter
Integrating Airflow as a productionized system within Twitter required modifications to Airflow and its deployment procedures. Here are some of the most noteworthy contributions we made.
Authentication and authorization
At Twitter, engineers generally authenticate with internal web services via Kerberos. To support Kerberos in Airflow, we took advantage of the existing framework provided by Flask-Login and created a child class of LoginManager. At initialization time, this class verifies that the principal name is known to Kerberos. It then sets up before and after-request filters that drive the GSSAPI process. On success, LDAP groups for the user are queried and and carried along with the user object. This allows us to offer group-based DAG-level control of actions or even visibility. Taken together, this approach allows Airflow to neatly drop into our authentication and authorization infrastructure with no fuss.
Self-service model
We are working towards a self-service model for teams to stand up their own instances. Which provides user groups complete control of their instance and DAGs, and it is much simpler to manage permissions and quotas of a single service account. This approach also paves the path to a potential multi-tenant Airflow server at Twitter.
In our self-service model, each team’s deployment differs from another in only Aurora configuration and DAG population. So rather than copy and paste of a whole lot of config, we use a simple, short json file to specify the per-instance variables such as owning service
account, allowed groups, backing database, Kerberos principal credentials, and DAG folder locations. At start up time a simple command invoked through a custom CLI generates the appropriate Aurora configurations to start the scheduler, web server, and worker instances.
Stats integration
Airflow, like most python-based open sourced systems, uses the StatsClient from statsd. Twitter uses StatsReceiver, a part of our open-source Finagle stack in github/twitter/util. However, the two models are different: in util/stats, each metric is registered, which places it on a list for future collection; in statsd, metrics are simply emitted and the right thing happens on the back end. To solve this problem we built a bridge that recognizes new metrics and register them as they appear. It is API compatible with StatsClient which allows us to inject an instance of our bridge object into Airflow as it is starting. With metrics now collected by our visualization system, we are able to provide a templated dashboard to simplify creation of a monitoring dashboard for our self-service clients.
Distributed workers with Celery
Airflow makes use of Celery to orchestrate a scaled multi-worker node configuration. We configured Celery to work with Twitter cloud containers and by default use a SQLAlchemy broker to exploit Airflow’s MySQL database as a message queue for Celery. This allows our users to setup their scalable Airflow workers without having to maintain an extra Redis or RabbitMQ service. However this does not prevent them from switching over to another message broker if they decide to support one in the future.
ML on Airflow
In order to make machine learning pipelines easy for our customers to build on Airflow there were a series of extensions we needed to add or improve upon.
Custom ML operators
Firstly, to help Twitter engineers run ML tasks, we developed reusable operators for them, including:
Type checking in operators
We did not want our users to incur the cost of encountering errors while DAGs were running due to compatibility in arguments being passed from one operator to another. Thus we developed a type checking system for operators, which verifies input and output data types of all operators in DAGs (args and XCOMs).
For example, suppose that we have two connected operators Foo and Bar in a DAG. Foo outputs an integer XCOM value, and Bar takes that XCOM value but is expecting a string. Our type checking system would raise an error to let the DAG developer know the types do not match.
All our operators are built upon this type checking system and have their input and output types declared through python decorators.
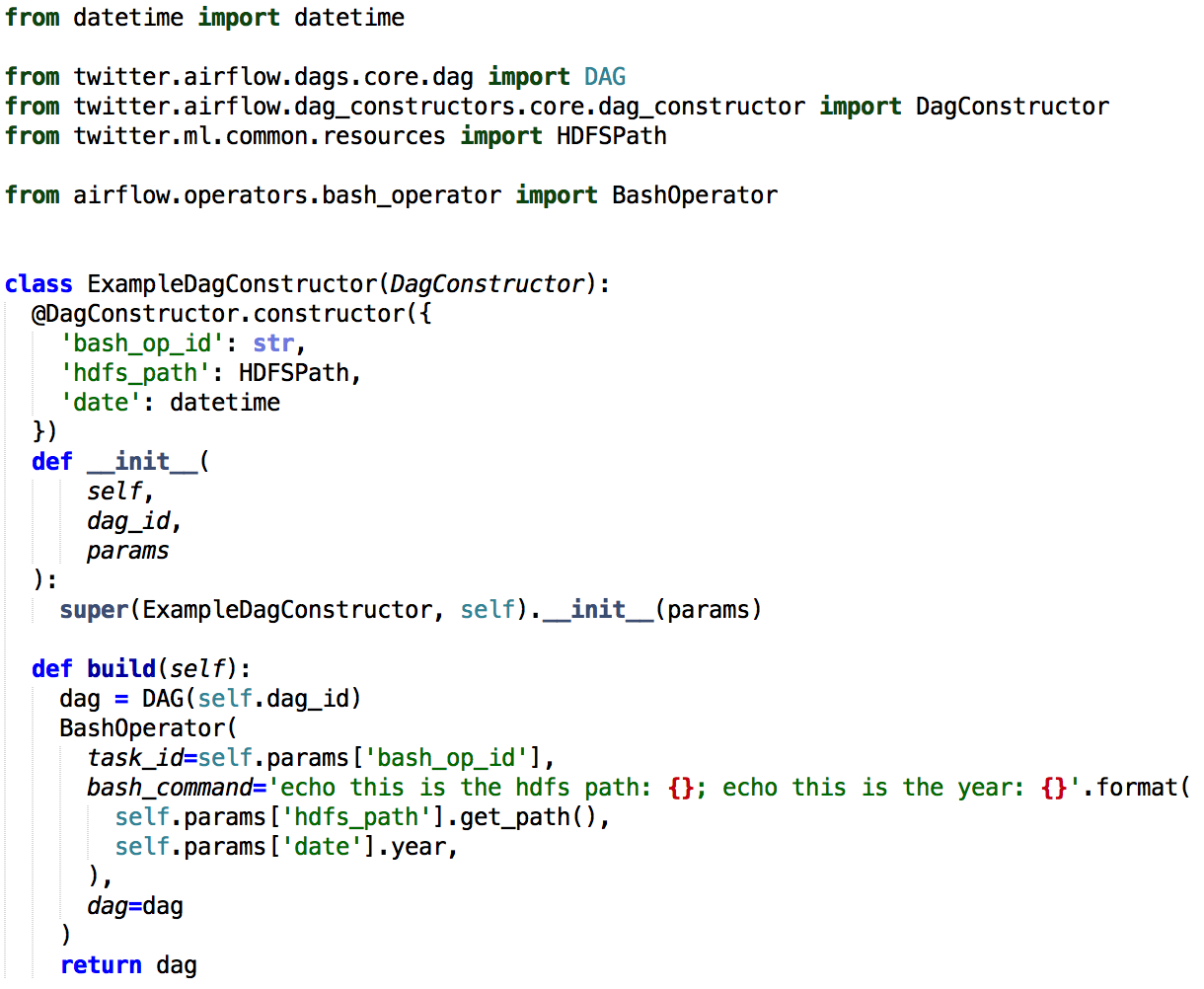
DAG constructors
Our users often had DAGs which processed the same operations but with different parameter values. To prevent having to create multiple DAGs they created a constructor class around a DAG, and then exposed a dependent set of parameters within it’s constructor.
We decided to support this pattern by making DAG constructors a first class citizen in ML Workflows. We developed a DAG constructor base class which allows users to declare a list of parameters of their DAG. For example:
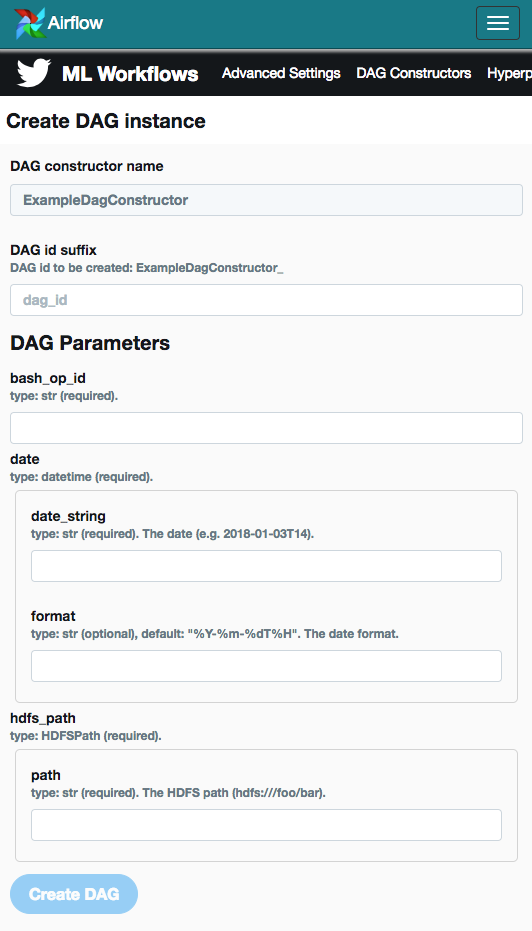
We also developed a UI for our users to ad-hocly create instances of their DAGs with different parameters:
A python file is generated when a user creates a new DAG and is placed in Airflow’s DAG_FOLDER which makes use of Airflow’s ability to automatically load new DAGs.
To make these DAG instances persistent on our stateless cloud containers, we record information of them in the user’s Airflow database. When Airflow schedulers and workers restart, the DAGs are automatically re-created and loaded by Airflow.
Airflow administrator UI plugin
While creating many additions to Airflow to better support our ML use cases on the backend we also wanted to provide a nice UI layer to interact with certain features on the frontend. In order to achieve this we developed a UI plugin that adds a Flask view to the Airflow webserver. The view loads our JavaScript bundle, which is a small single page web app built with React. The app contains user interfaces of our features, such as hyper parameter tuning and DAG constructors, and calls Flask endpoints declared in our plugin to fetch data and invoke corresponding functionalities.
One of the most powerful use cases of ML Workflows is hyperparameter tuning. Leveraging Airflow’s DAGs, we enabled this feature in ML Workflows by implementing DagConstructor, which parameterizes a DAG, along with HyperParameterTuner, which builds a DAG that conducts the experiments and reports results to the user.
After a user fully automates a workflow using ML Workflows, hyperparameter tuning can be applied to the DAG by:
The HyperparameterTuner will generate a DAG with several subdags, each conducting an experiment using hyperparameters as specified by the HyperparameterTuningSpec. The DAG also includes tasks for recording results and reporting them to the user.
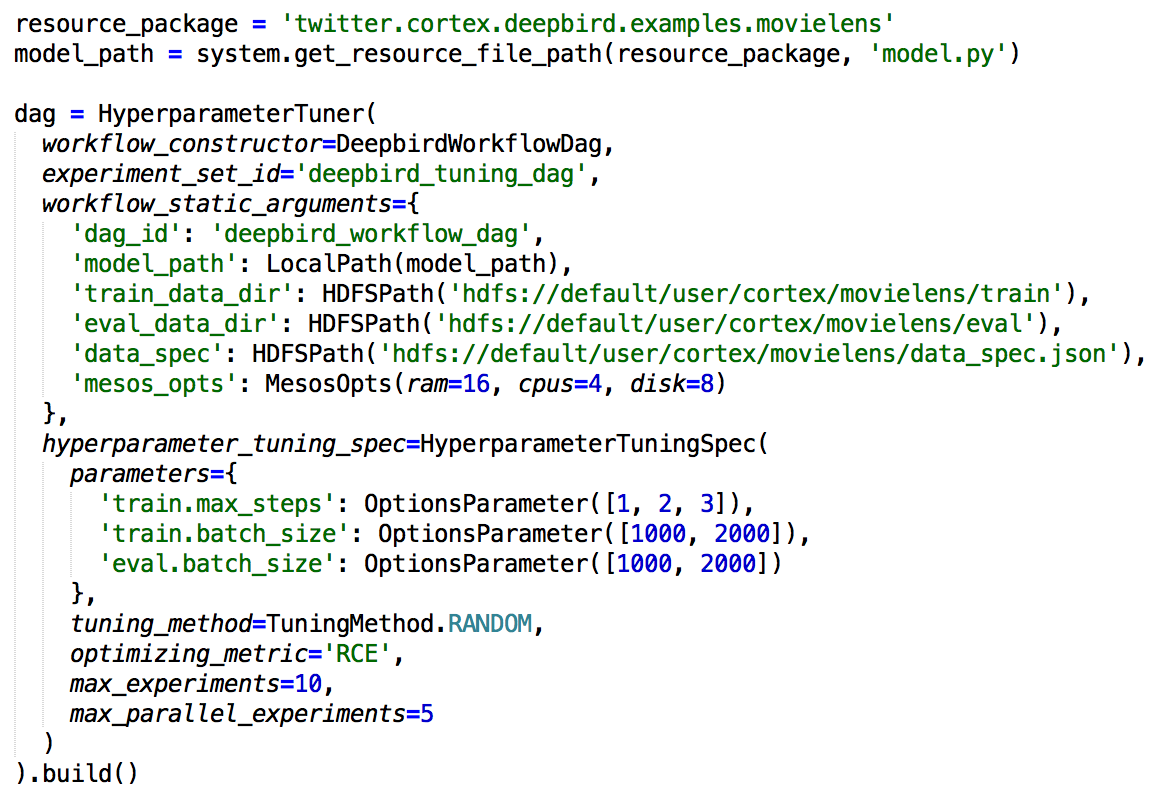
To make this more tangible, suppose a user has created a simple DeepBird model defined as a Python file which can be trained given some parameters. To apply hyperparameter tuning, the model needs to be wrapped in a SubDAG that exposes the parameters to the tuner.
This pattern is used so often it is included in ML Workflows as a general DAG constructor for the purpose of hyperparameter tuning, aptly named DeepBirdWorkflowDag.
HyperparameterTuner is then given this DAG, along with a HyperpameterTuningSpec to build the hyperparameter tuning workflow
The HyperparameterTuningSpec specifies the hyperparameters, tuning method, optimizing metric, and the number of experiments. This resulting DAG is generated:
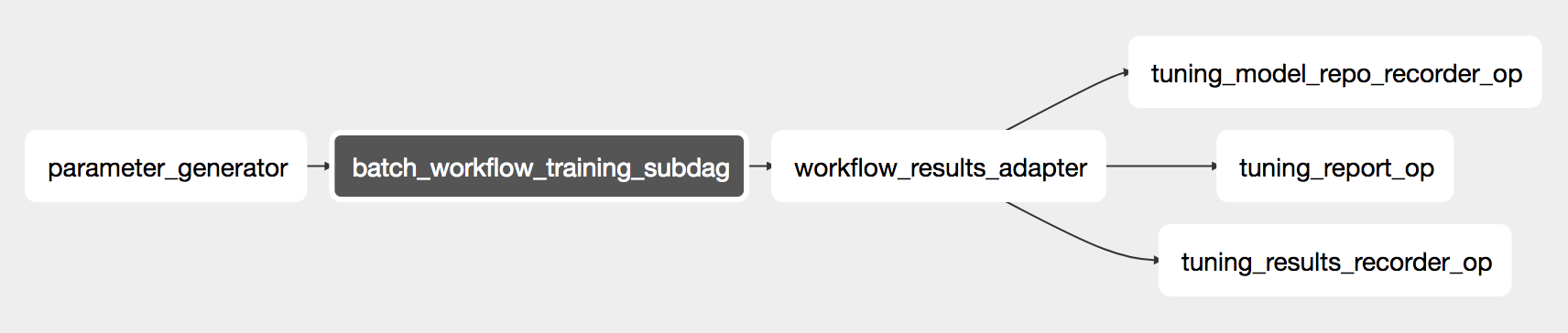
Zooming into batch_workflow_training_subdag, the individual experiments can be observed:
Here, each batch_workflow_subdag_op represents an experiment and is a DAG constructed from DeepBirdWorkflowDag.
After running this workflow, the results are recorded and sent to the user.
The ML Workflows product has been adopted by several internal teams so far and has delivered immediate impact. One example is in the Timelines Quality team which adopted ML Workflows and as a result reduced the interval for retraining and deploying their models to production from four weeks to one week. The team also ran an online experiment to examine the difference of having the models retrained more often. The result of the experiment was positive, indicating that shorter retraining intervals provide better timeline quality and ranking for our users.
Several teams have also begun to experiment with hyperparameter tuning on top of ML Workflows and are seeing early results. As an example, the Abuse and Safety team applied our hyperparameter tuning tools to one of their tweet-based models, which allowed them to automatically run a number of experiments and return an improved model based on offline metrics.
As teams have adopted ML Workflows, the common Python operators and utility functions have grown and teams are benefiting from reusing common components to construct their workflows. Teams have adopted the DAG constructor pattern making it easy to run workflows with different parameters. As more teams at Twitter continue to adopt ML Workflows, we expect to see a large-scale, positive impact on engineering productivity, iteration speed, and model quality.
While the initial results of ML Workflows are exciting, there is a lot of work for the team ahead:
We would like to thank Paweł Zaborski and Stephan Ohlsson for spearheading the integration of Airflow at Twitter. Major thanks go to the Cortex Platform Tools team for initiating the analysis of alternatives, developing the design document, and integrating Airflow into the Twitter stack: Devin Goodsell, Jeshua Bratman, Bill Darrow, Newton Le, Xiao Zhu, Yu Zhou Lee, Samuel Ngahane, Matthew Bleifer, Andrew Wilcox, Daniel Knightly, and Masoud Valafar. Honorable mention to management for supporting us in this endeavor: Nicolas Koumchatzky and Sandeep Pandey. And finally, a special thanks for all the Tweeps that contributed feedback during our beta offering.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.