Insights
Twitter meets TensorFlow
By
and
Thursday, 14 June 2018
Machine learning enables Twitter to drive engagement, surface content most relevant to our users, and promote healthier conversations. As part of its purpose of advancing AI for Twitter in an ethical way, Twitter Cortex is the core team responsible for facilitating machine learning endeavors within the company. With first-hand experience running machine learning models in production, Cortex seeks to streamline difficult ML processes, freeing engineers to focus on modeling, experimentation, and user experience. Our mission is to empower internal teams to efficiently leverage artificial intelligence by providing a platform and unifying, educating, and advancing the state of the art in ML technologies within Twitter. Indeed, Cortex is Twitter’s ML platform team.
In this blog post, we will discuss the history, evolution, and future of our modeling/testing/serving framework, internally referred to as Deepbird, applying ML to Twitter data, and the challenges of serving ML in production settings. Indeed, Twitter handles large amounts of data and custom data formats. Twitter has a specific infrastructure stack, latency constraints, and a large request volume.
The Twitter ML Platform encompasses the ML tools and services Cortex provides to accomplish our mission. The ML Platform provides tools that span the full ML spectrum, from dataset preparation, to experimentation, to deploying models to production. The subject of this blog post is only one of the components of this platform: internally designated as DeepBird. This framework is for training and productionising deep learning models. Implemented using Python, TensorFlow (v2), Lua Torch (v1). The framework has undergone various changes since the summer of 2017, and we wanted to share our experience here.
Twitter acquired Madbits in 2014 to bring deep learning expertise in-house. After successfully applying this technology to derive better content understanding in images, the team became Cortex mid-2015. Cortex grew with the integration of people from other teams, and other acquisitions. The original mission was to refine and transform Twitter’s product with state-of-the-art AI capabilities. Starting mid-2016, the team’s goals shifted to unifying and improving the usage of AI for all Twitter engineers, that is, build a “machine learning” platform. In that context, DeepBird (based on Lua Torch) became the first project to meet broad internal adoption, leading to significant product gains. Some of these gains are described in Using Deep Learning at Scale in Twitter's Timeline. Cortex later grew to integrate others from the company and from other acquisitions like TellApart, Gnip and Magic Pony.
DeepBird is an end-to-end solution for training and serving deep learning models at scale. In order to ease the transition from an existing internal machine learning framework that was using YAML configuration files, its configurations were also written in YAML. The data was expected to be encoded in an internal DataRecord format, which conveniently handles sparse feature configuration.
In the summer of 2017, given the migration of the Torch community from Lua to Python via PyTorch, and subsequent waning support for Lua Torch, Cortex began evaluating alternatives to Lua Torch. After careful consideration of frontrunners PyTorch and TensorFlow, we decided to migrate DeepBird to the latter. The primary deciding factor was that TensorFlow had much better support for serving models in production.
Unlike Lua Torch, TensorFlow is here to stay. It supports HDFS out of the box, has lots of documentation and a large community. During experimentation, model metrics can be easily visualized using TensorBoard. These aspects were also strong arguments in favor of TensorFlow.
Since then, Cortex has been working to migrate DeepBird from Lua Torch to TensorFlow. We have also decided to move away from YAML, which was also used to abstract away Lua. This version 2 of DeepBird still expects most data to be stored in DataRecord format, but training scripts are now written in Python using a combination of TensorFlow and our own DeepBird extensions.
Training with DeepBird v2 at Twitter has never been simpler. Typically, any modeling workflow involves the following steps:
1) Frame the ML task: what are we optimizing, and what are the inputs and features?
2) Prepare datasets
3) Define a model suitable for the problem;
4) Write a training script to optimize a model and evaluate it on different datasets;
5) Define hyper-parameters and run the script on Aurora Mesos; and finally
6) Repeat from Steps 3 to 5 until the desired results are obtained.
v2 provides an easy UI to tune their models until obtaining the desired results. With the help of DataRecordTrainer, which encapsulates a tf.estimator.Estimator, we are able to address most of Twitter’s use cases. This training supports DataRecord datasets compressed in LZO format.
What is Data Record
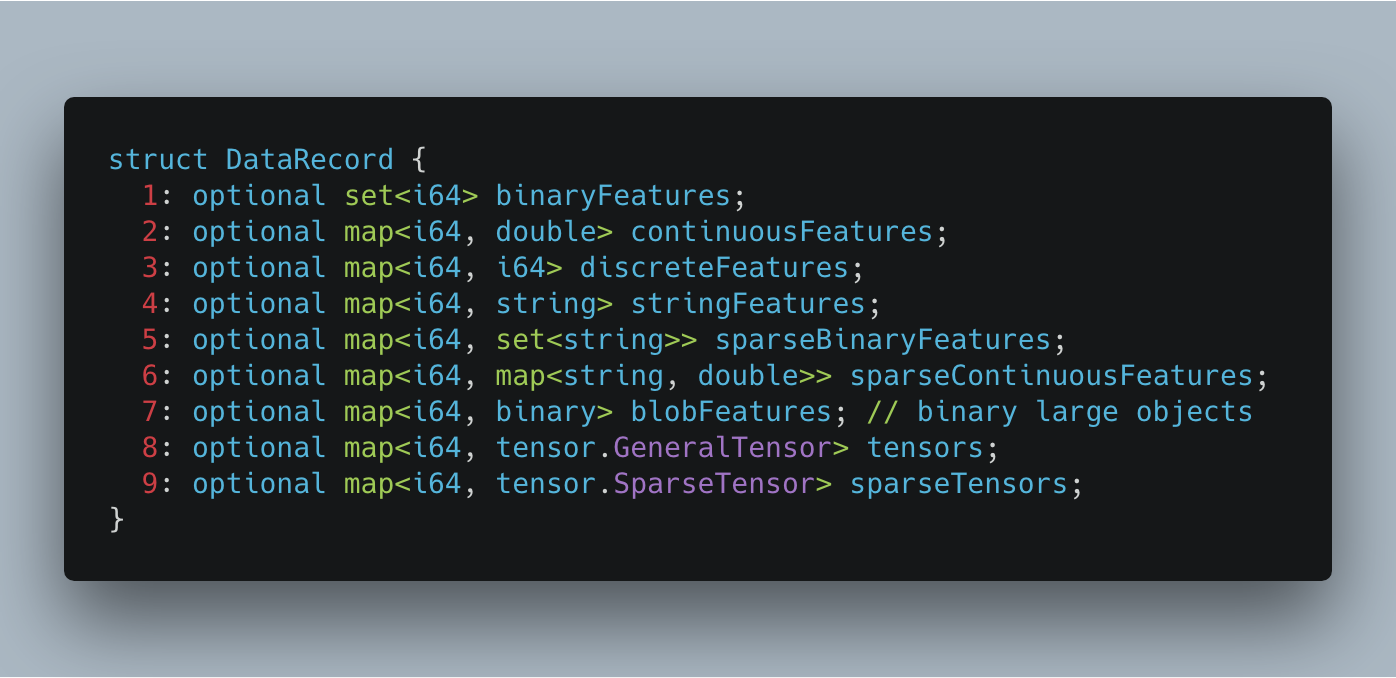
Twitter’s choice data format is the DataRecord. It has a long history of use for ML tasks at Twitter. DeepBird v2 recognizes data saved using this format. Below is the Thrift struct of the DataRecord:
DataRecords were originally implemented as a way to conveniently store different combinations of sparse and dense features in single unified struct. It has since evolved to support more modern features like tensors and blobs.
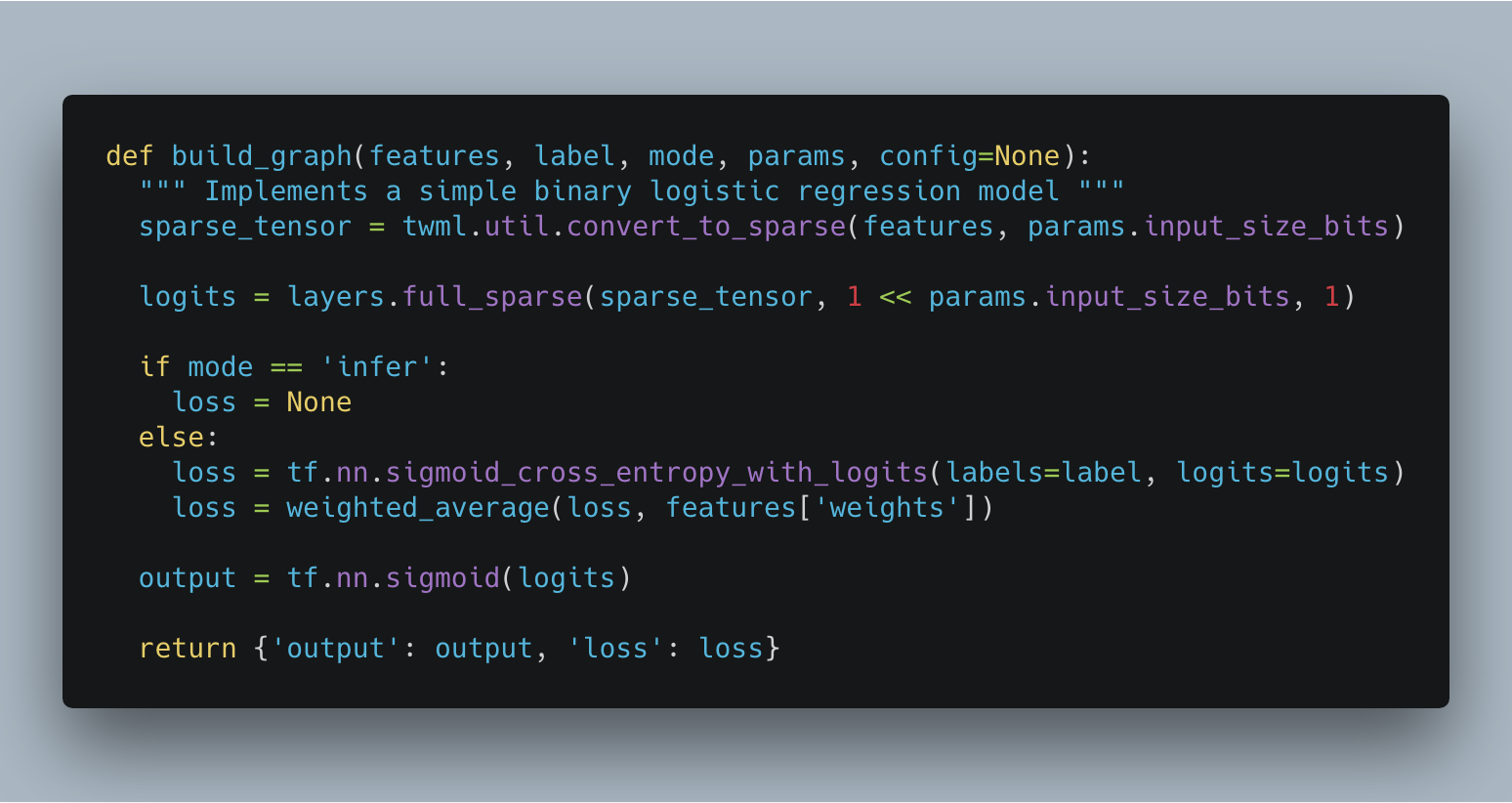
In order to use DeepBird v2 to process DataRecords, the DataRecordTrainer can be initialized with a build_graph to specify a model. A simple binary logistic regression would look like:
The build_graph function is used in three modes: training, evaluation and prediction. These are respectively represented below:
The Trainer and Estimator APIs provide the means to configure each mode of the graph with different input_fn, metric_fn, serving_input_receiver_fn, and export_output_fn functions. The last graph is the one used in production. Like everything else at Twitter, the production models are served as microservices. The ML services implement a Prediction API which was defined years ago by the legacy ML frameworks. The Prediction API is simple. A client submits a PredictionRequest and the service replies via a PredictionResponse. Both are Thrift objects that encapsulate one or many DataRecords.
Once the model is defined, we can pass build_graph to the DataRecord API in order to train our model:
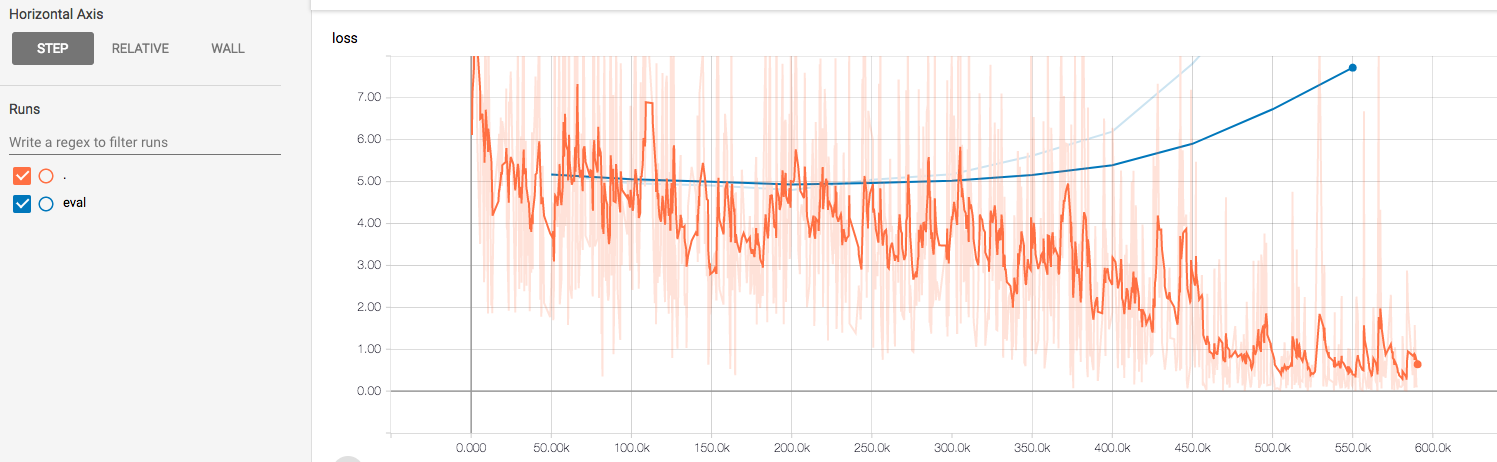
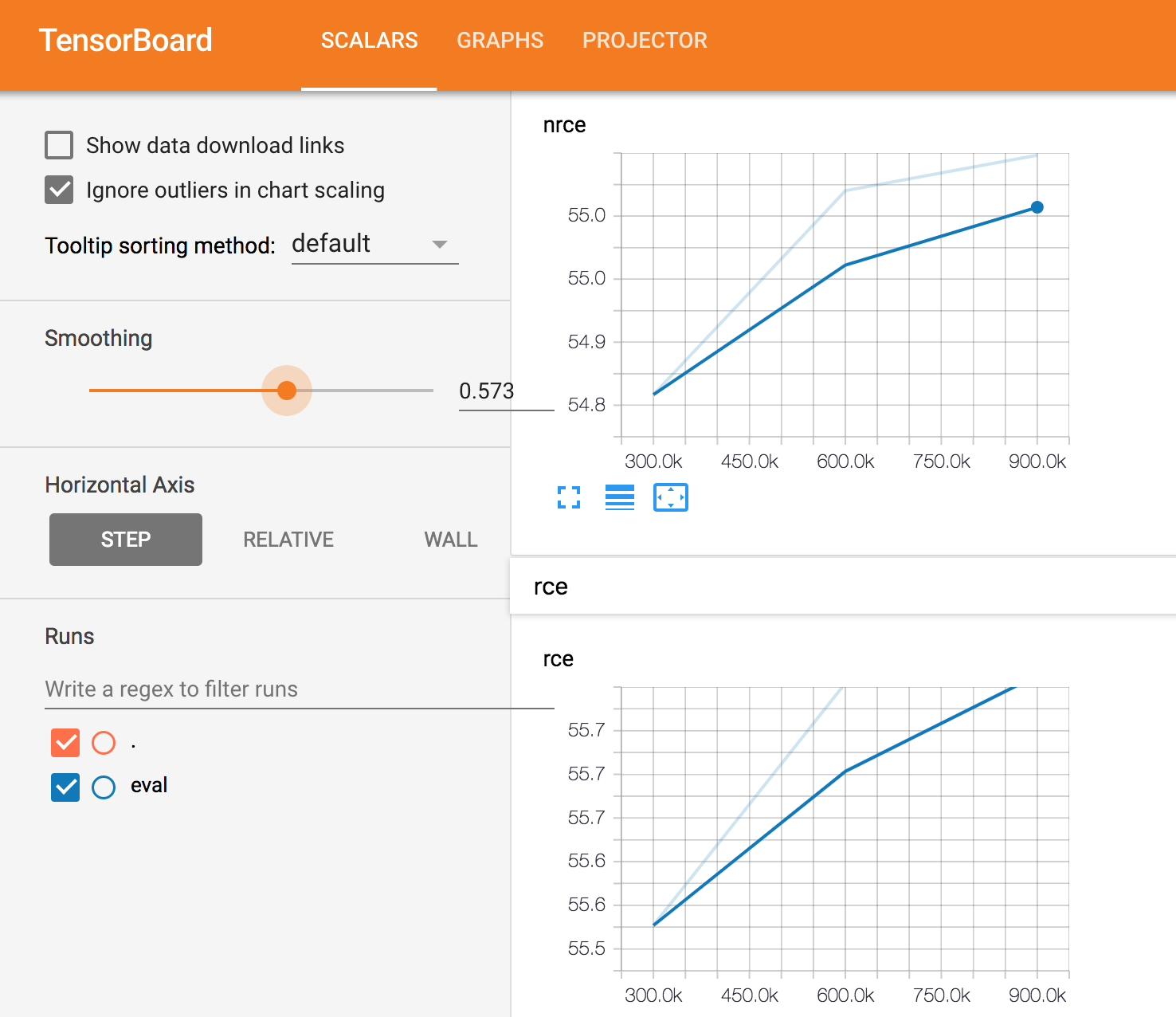
Models can be tracked through TensorBoard in order to see the desired metrics in real-time:
Additionally, models can also be tracked through our internal tool: Model Repo. Model Repo’s goal is to reduce friction in developing, deploying, maintaining, and refining models. This tool, as seen in the image below, acts is a complementary manner to Tensorboard as it provides the ability to visualize hyperparameters and easily compare the results of multiple runs.
After the experimentation phase, the model is ready to be exported for making predictions. Typically, the exported model will later be served in a production environment. After the model has been trained and saved to disk, the DeepBird Runtime enables teams to expose it as an efficient network service compatible with the Twitter ML Thrift API.
Who uses DeepBird?
DeepBird is used by Twitter researchers, engineers, and data scientists. ML theory and technology experience varies from the beginner to expert level. Not everyone has a PhD in ML, but again, some do. Our goal is to satisfy most users on the spectrum of ML knowledge.
As discussed previously, one customer who benefits from Deep Learning models is Timelines Quality. Their main goal is to ensure the most relevant Tweets are displayed to Twitter users. Their models train on terabytes of data and make use of many training and calibration phases, including:
In order to support their migration to DeepBird v2, we needed to support this kind of multi-phase training. DataRecordTrainer supports this out of the box.
Before deciding to transition to v2, we analysed different model serving alternatives, including TensorFlow serving. We decided to build our serving system due to TensorFlow Serving not being designed to interact with the Twitter stack (Mesos/Aurora/Finagle).
Caption: Aurora Mesos CPU usage graph for a DeepBird application.
The transition to v2 has involved multiple steps, including:
Verifying inference correctness and measuring prediction latency using dark traffic from production services.
Ensuring inference service stability and efficient resource usage at high loads.
The ability to load Tensors from v1 into v2 enabled us to certify the correctness of v2 components. A lot of our unit tests have these kind of correctness tests builtin.
The integration of v2 with our observability infrastructure has allowed us to reliably monitor our services, as shown below:
The DeepBird v2 API has moved into a stable state following a quarter spent in beta release. In this time, we have learned a lot about the intricacies of the TensorFlow Estimator API. We have invested a lot of effort in trying to use it in non-standard use cases (for example, multi-phase training). In so doing, we have been able to simplify, consolidate and expand the Estimator API into our own Trainer API.
What challenges did Cortex encounter?
The road to DeepBird v2 has not been one without its challenges. Throughout the past year, we have encountered and solved a decent amount of performance bottlenecks and other issues. Some of these challenges are outlined here:
Ultimately, we would like to democratize v2 inside Twitter. Concretely, this meant understanding and simplifying the Estimator API for engineers and data scientists, as well as ensuring a proper level of documentation, tutorial, examples and unit tests. Our goal is to make v2 simple to understand by engineers and data scientists.
Impact
We can already see the impact of using DeepBird v2 at Twitter. With it, we are able to achieve:
These are all very exciting news for our team; and we look forward to seeing what other benefits v2 will bring to Twitter in the future.
Going forward we will continue our work on DeepBird v2. In the upcoming months, we plan to add support to enable models in this new platform to train on GPU clusters. Additionally, we are also committed to adding support to online as well as to distributed training in v2. We believe that v2 is the future of ML at Twitter.
In the long run, this should help us to expand the usage of ML inside Twitter, and provide better services to our users.
We would like to thank Kovas Boguta, and Daniel Hasegan for the early adoption of TensorFlow at Twitter. Major thanks go to the Cortex Core Environment team for initiating the analysis of alternatives, developing the design document, and integrating TensorFlow into the Twitter stack: Yi Zhuang, Conrado Miranda, Pavan Yalamanchili, Nicholas Leonard, Ricardo Cervera-Navarro, Cibele Montez Halasz, Ruhua Jiang, Priyank Jain and Briac Marcatté. Honorable mention to management for supporting us in this endeavor: Nicolas Koumchatzky, Jan Pedersen and Sandeep Pandey. And finally, a special thanks for all the Tweeps that contributed feedback during our beta offering.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.