Insights
Measuring perceived video quality on mobile devices
By
Monday, 9 July 2018
Like many online video services, Twitter adapts the video we deliver based on your network connection in order to provide you with the best possible quality of experience. If you’re on a low bandwidth connection you’ll get a lower quality video, while on a high bandwidth connection, we’ll serve you high quality video. This allows us to deliver instantaneous and smooth playback regardless of the quality of your network connection.
Understanding how our users perceive the visual quality of each of the different video variants is important. To achieve this, we needed to find a way of measuring perceived quality that is:
We hoped that two simple methods - Mean Opinion Score (MOS) and Double-Stimulus Mean Opinion Score (DS-MOS) - would provide good results. However, these metrics couldn’t provide us with sufficient precision to monitor small changes in quality, or produce consistent quality estimates between different sessions. To solve for this, we collaborated with Katherine Storrs to develop a new subjective video quality assessment method: Adaptive Paired Comparison (APC), which is described in this paper and summarised in this blog post.
But first, let’s look deeper into the existing industry standards and explain why we decided to create our own method for subjective quality assessment.
Subjective quality evaluation methods typically require specialized equipment and a standardized environment to limit variations (such as lighting conditions, display type, screen distance, …) [1]. Within these tightly controlled environments, results are reproducible. However, there are no standardized methods to measure the subjective video quality on mobile devices under normal viewing conditions.
We were aware that MOS and DS-MOS have known issues with reliability across raters and experiments [2, 3], but they are easy to implement and fast to execute with non-experts. As this addresses three important requirements, we hoped these methods would yield satisfactory results. So with limited engineering efforts we added both methodologies to our mobile visual quality evaluation infrastructure.
To evaluate the consistency of the measurements and their robustness to external factors, we evaluated the test-retest reliability for the MOS and DS-MOS procedures independently. For each procedure, we evaluated the subjective quality of the same samples in two different tests. In the first test we randomly intermixed a low quality variant, while in a second test we added a high quality variant. To limit bias, the two tests were done on different days. For all tests, we used the same 10 second samples, which cover a broad range of video characteristics. Our dataset consists of 30 samples, extracted from open-source videos [5, 6]. We encoded the dataset with three different settings to represent the low, medium, and high quality encodes:
Our in-house mobile visual quality evaluation app downloads all the encoded samples to local storage and plays a randomly selected sample (preceded by the high quality original in case of DS-MOS). This allows for smooth and uninterrupted playback so our raters only evaluate visual quality.
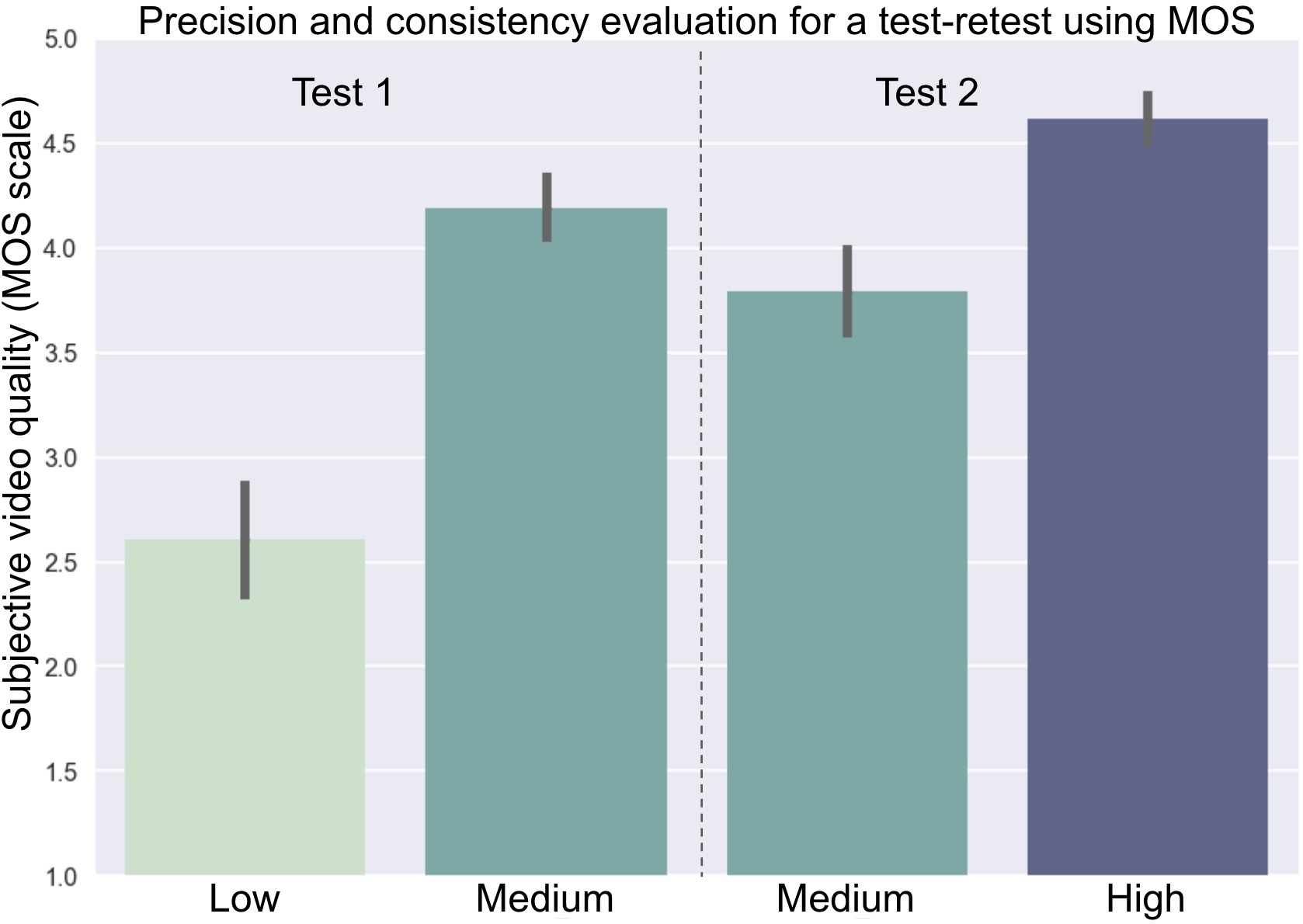
The graphs below show the results for MOS and DS-MOS respectively. In each graph, the heights of the first two bars represent the average scores of the first test, while the third and fourth bars represent the average scores for the second test. The two middle bars therefore represent repeated measurement of the quality of identical samples, in two different experimental sessions. The line on each bar indicates the 95% confidence interval.
These results demonstrate the two known problems when using the MOS and DS-MOS methods. First, the ratings given by different viewers to the same video variants can vary widely, as indicated by large confidence intervals. This lack of precision is problematic, because it means we cannot pick up small difference in quality variations. Second, the rating given by the same viewers to the same videos in a different session can vary substantially (compare the middle two bars in each graph). In a reliable subjective quality measure, the same encodes should have identical results between Test 1 and Test 2.
As these results do not align with our requirements - high precision and consistency for a short test duration - we decided to create a new subjective quality assessment method for mobile devices.
When an optometrist tests your visual acuity, they ask “which looks better, lens A or lens B?”, rather simply asking you to describe the visual quality of each lens. People can more sensitively and reliably make relative quality judgements than absolute ones. Therefore, in the scientific study of visual perception, “paired comparison” tests are considered the most rigorous measurement methods [7]. In a paired-comparison trial, we show two versions of a video sample: a ‘reference’ sample chosen from a predefined quality scale, and a ‘standard’ sampe which we wish to measure the quality of. After each trial, the rater indicates which video had the highest quality. This relative judgement eliminates the unclear meaning of quality ratings, and limits the impact of external factors.
Paired comparison tests have in the past been considered impractical as each standard video had to be compared exhaustively with each possible reference quality level [8]. For 10 second samples, each rater would need over 8 hours to complete session for our 30 samples. By using a Bayesian adaptive procedure a small subset all possible pairwise comparisons is intelligently selected. This provides us with a good quality estimate in the same number of trials as a DS-MOS test.
Making measurement efficient with Bayesian Active Learning
To estimate the perceptual quality with as few ratings as possible, we apply a Bayesian active learning procedure using a particle filtering simulation [9]. The Bayesian active learning uses previous responses to estimate which reference quality level will provide the most information if selected next. This reference quality is paired with the next sample and the rater’s binary response (reference quality is better/worse) is fed back to the Bayesian active learner, which updates the known information and repeats the process until all samples have been evaluated.
Establishing the reference scale
The APC method relies on a reference quality scale against which the quality of samples is measured. As we want to measure small quality fluctuations, we decided to create a 50-point reference quality scale. To have a meaningful scale that can be used for easy comparison across experiments, we had four criteria:
We have created this scale using a four-step approach:
To construct a rough initial scale, we encoded a set of 100 sample videos at seven different resolutions, and all integer CRF values between 12-52. We took the convex hull of the resulting rate-distortion curves, indicated by the points in the left-hand graph below (which plots PSNR vs bitrate for each resolution per curve). To obtain our initial rough reference scale, we sampled the bitrate at 50 logarithmically spaced points on the convex hull. Where necessary, we interpolated the crf values of two neighbouring points.
In a human experiment, 22 raters judged the relative quality of pairs of videos sampled from this initial scale. We used gradient descent to infer the relative perceptual quality of each reference level. These inferred qualities are shown as dots in the right-hand graph below. Non-linearities in the estimated perceptual quality function (blue interpolated curve) indicate where the perceived quality of the initial reference scale changes abruptly. As we aim for a subjectively linear scale, we resampled the initial scale (horizontal lines). This resulted in 50 combinations of resolution and CRF values (vertical lines).
We created a 50-point reference scale expressed as resolution-crf pairs, which results in (approximately) subjectively linear behaviour between samples. These resolution-crf pairs are used as encoding settings that we apply to the content of an evaluation.
To assess the precision and reliability of APC compared to MOS and DS-MOS, we repeated the previous experiments using APC. On each trial, a randomly selected standard sample was paired with a reference quality of that same video (the order of the standard and reference sample is random). The active learning procedure uses previous responses to select the next quality level. After rating all samples, we have sufficient data to accurately predict the perceived visual quality
APC is more precise and reliable than MOS or DS-MOS
The graph below shows the subjective quality of the same videos described previously, measured using APC. We can see that APC:
Through innovations like APC, Twitter’s Media Infrastructure group is continuously working to improve the quality of experience when viewing media on Twitter. We are hiring across many of our teams, so if building new tools like APC excites you then come join us!
We would like to thank everyone at Twitter who has been involved with this work and in particular our post-doctoral research intern, Kate Storrs, without whom this wouldn’t have been possible.
[1] Methodology for the subjective assessment of the quality of television pictures, Rec. ITU-R BT. 500 -13, Jan. 2012.
[2] Streijl, RC, Winkler, S and Hands, DS. "Mean opinion score (MOS) revisited: methods and applications, limitations and alternatives." Multimedia Systems. Vol. 22. No. 2. (2016)
[3] Mantiuk, RK, Tomaszewska, A and Mantiuk, R. "Comparison of four subjective methods for image quality assessment." Computer Graphics Forum. Vol. 31. No. 8. (2012)
[4] Aaron, A., Li, Z., Manohara, M., De Cock, J. and Ronca, D, “Per-Title Encode Optimization,” in online blogpost https://medium.com/netflix-techblog/per-title-encode-optimization-7e99442b62a2, Dec. 14, 2015.
[5] Schuler, A and Donato, M., “Engineers Making Movies (AKA Open Source Test Content), ” in online blogpost https://medium.com/netflix-techblog/engineers-making-movies-aka-open-source-test-content-f21363ea3781, May, 11, 2018
[6] Blender Foundation Open Movies (https://www.blender.org/)
[7] Kingdom, F.A.A., and Prins, N., Psychophysics: A Practical Introduction, Elsevier Academic Press, London, 2010.
[8] ITU: “Subjective video quality assessment methods for multimedia applications”, ITU-T Recommendation P.910, Geneva, Switzerland, September 1999.
[9] Huszár, F., and Houlsby, N.M.T, “Adaptive Bayesian quantum tomography,” Physical Review A, vol. 85, no.5:052120, pp. 1-5, 2012.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.