Insights
Gotta catch ’em all
and
Friday, 29 March 2019
This article is a follow on of thoughts related to The Testing Renaissance article.
If you have ever worked in a server architecture before, then odds are that you have come across many different styles of error handling (especially within the same server). This is very common in legacy code bases where many engineers have come and gone, influencing the code with their own techniques and styles.
From our experience, if you can design your core system around a catch-all architecture, then it is trivial to reason about the success and failure of that system. Additionally, writing tests (especially TDD) is much easier and more natural. The lead time from a customer-reported bug to a regression test capturing that bug is extremely fast. Most importantly, overall confidence in your system is high because testing is easier and error handling is in a centralized location.
Our main goal in this article is to describe an error handling design that we have successfully utilized in our own servers to simplify and improve the readability of our systems.
As you can see in the charts above, 100% success rate and not a single failure in last 2 hours with requests per minute at 6 million! In fact, at the time of this writing, the last week had not had a single failure which is pretty impressive.
The high level design is a few steps:
When our system’s success rate goes down, we look at the single graph from step 4 with all these exception stats and know exactly the issue immediately most of the time.
First, to kick this pattern off, you will need to create a few base exceptions. This allows many common components/filters to respond to common exceptions and reused in most servers.
Now, if you have an http server, you will have a few more such as:
Some may disagree with having a normal case like NotFoundException in your system, but the advantages on the practical side have been ten-fold. I guess it’s whether you stick with theory or practicality on making your life easier. Customers (an operations team perhaps) generally don’t care about your theory and only care about you delivering a good experience, so we lean towards making the operations team happy.
As an example we have hit on 404, some systems just record number of 404s that happen. We instead throw a few different exceptions:
This in turn gives us statistics on these specific events happening while all still returning a 404 to the clients. It also records better in our logs about what specifically went wrong if a client asks us so we can distinguish between a client hitting the wrong route and using the wrong account id.
Next, let’s look at a picture of some reusable filters
CatchAllFilter [Req, Resp]
The first filter is called CatchAllFilter and is reusable if the protocol exceptions it translates to are the same for every server (hopefully they are). It then has the simple job of translating any exceptions into the protocol exception to be returned to the client. In the case of http, there would be an HttpCatchAllFilter that translates all the base exceptions into the http status codes. That is completely reusable as well. The request and response are generically typed to work with any request/response type.
StatsFilter[Req, Resp]
This is where we get some huge power in our design. Many people add stats throughout their system, littering the code with more unnecessary code. Instead, this lets you do it all in one place. Ours also separates exceptions into ‘ignored failures’ and ‘failures’. ‘Ignored failures’ are things like BadClientRequestException and ValidDiscardingRequestException. They do not impact our success rate, which is why we have systems at 1,000,000 rps that also have 100% success rates. The real beauty of StatsFilter though is in how it records stats like so
stats.getCounter(exception.getClass).increment()
Notice that exception.getClass returns the subclass of BadClientRequestException (or a subclass of any of the base exceptions). This way, anytime someone adds a new subclass, we automatically get a new statistic of how often it is happening. Even for the success cases of ValidDiscardingException, we see things like DuplicateException or SettingNotOnForUserException so we can visually see all the stats. One of our failures graphs has many lines and we easily cursor over the offending spike, pinpointing the issue without looking at logs.
And looking at the legend tells us the exact exception of what issue just occured in production.
TxLoggingFilter[Req, Resp]
Since we have systems that are doing tons of requests every second, frequently we want to log the result of every request and the result of the last seven days to one month for looking into what happened when we get inquiries. This filter typically logs to a persistent store the request and response where the response may have been an exception. Again, this is a reusable piece that can be configured to write to a different table each time.
Now, let’s say we did all this with response codes — many people will propose we do that instead, actually. Great, now you are going down the path of no reusability as each system’s response codes are different (and you can’t subclass those codes). The one thing that remains the same, however, is the base exceptions or categories they all fall under so while we have infinite base exceptions, we only have four abstract exceptions.
The other option is to just do response codes from server back to client and internally throw exceptions. In this case, however, each client following this pattern will have to create translations from response codes to exceptions for all their clients creating much more work for client teams. This is much better than doing a whole system internally with response codes, but also don’t like to give client teams more work.
There is a big debate on response codes vs. exceptions, so let’s go with specific examples as in each case we have applied this to a system built on response codes, it has been quite a reduction in code and an increase in simplicity. The specific example below only talks to two services, but in reality, our systems talk to five or more. With five or more, you can imagine the complexity exploding to really see how much more complex code becomes.
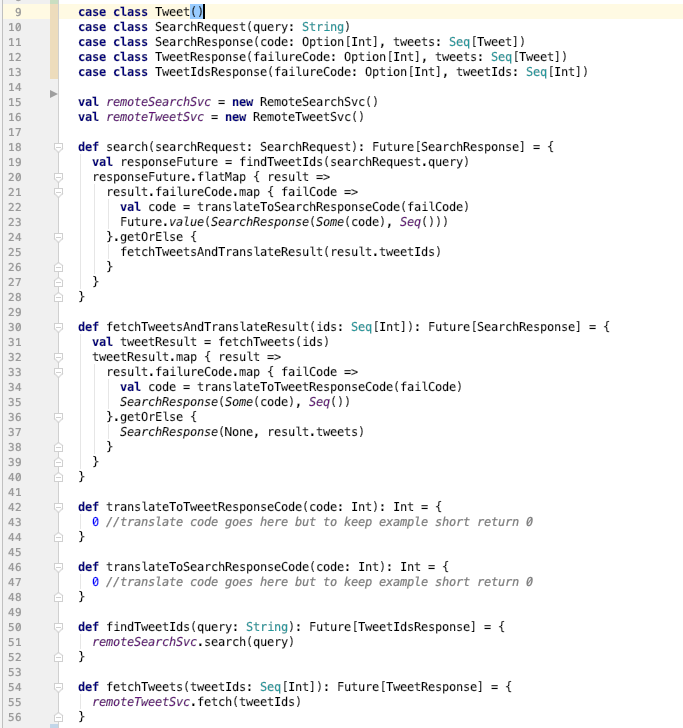
Below is an example of the complexities
Note that we isolate ‘most’ exception handling in the filters making business logic very quick to ramp up on and maintain.
Now, we can explain what the code above is doing. The first step is to issue a search query to get all the Tweet IDs to the search cluster. Once we have the Tweet IDs, we then need to issue a request to the Tweet store to get the actual Tweets. In our real system, we further need to get all the user IDs out of the Tweets and geo IDs and go to those systems as well. However, just by using two remote systems, we can easily see how much more complex our code is made by trying to use response codes. Next imagine if it were five systems and how the code grows exponentially.
Another issue that comes up with response codes and exceptions is monitoring those cases. In our team, we monitor every exception automatically. As seen above, it pops up with a human-readable name. Our stats graphs do not even know the name of the exception ahead of time. In a response code based system, we see the system littered with counters throughout the code to record all the different paths. With exceptions (including exceptions that mean success but discard the request), we record all those paths and isolate them into one ‘aspect’ of the system, a StatsFilter.scala class.
Imagine a world in which you further increase the complexity of the above ‘Response Code’ example. You now need to sprinkle more code throughout hiding your intention of what the business logic success path is really doing. It is very important for a developer to ramp on the success path first and then start understanding the failure cases after that.
The naming of ‘Exception’ is actually quite unfortunate. The way we use it is actually an ‘InterruptCode’. One example is that we have a UserSettingOffInterruptCode, though we call it UserSettingOffException(ick). In this case, a request comes in, and then deep in the logic we find out the user has a setting off. We don’t want to continue down the normal logic chain, so we short-circuit with a UserSettingOffException, which jumps all the way up to the filters and records the count of this code path happening. This is very useful to us as we
Naturally constructing an exception for normal success cases can hurt performance a little as it fills in the stack trace. In those cases, you can override the method fillInStackTrace with a no-op to bring the performance back to normal(ie. Very, very fast). We actually use this on ValidDiscardingRequestException above and for each unique reason, we have a unique exception so, at the very least, we do not need the very last line in the stack trace as each unique exception is only thrown from one location in the code.
There are two cases where you may not be able to throw the exception all the way to the top level stats filter entry point into your server:
In this first case, your system intakes one request and sends N requests where one of those N events may fail, but you want the others to continue and succeed. One example is if you personally have a tablet, a phone, and an email, and we tell a server to send out a notification to all your devices. The first request is send this information. This fans out into three requests and N of those three can fail. In a case like this, we may throw a PartialFailureException or a FullFailureException back to the client that called us with the initial request. They can then inspect and decide what to do next.
When using this catch-all pattern, it is always best to fail closed to start with (keep your system simple, KISS) and only go to a fail open strategy if failing closed is truly causing issues.
In failing open, you now have more work to do. Here are some of the new issues now:
One disadvantage is lack of documentation on all the possible exceptions a client can receive. Of course, if you fail open, there is no exception back to the client, so this only applies for exceptions that go back to the client. Perhaps there is some hidden exception you think you can recover from. Perhaps there is an exception that is so critical that you want to be paged. The way we deal with this today is by putting all the exceptions in a single file that we can refer clients to. Of course, clients don’t always know about that file, or even to ask for it, which is a downside. In the end, this trade-off definitely did not outweigh the benefit of this pattern.
In summary, we have presented a way to organize your business logic separate from all the failure cases, stats, and logging, keeping your code extremely clear and clean for the next developer you hire. We have even converted legacy projects to return exceptions rather than codes which worked out very well for us. Please give it a try and feel free to contact us.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.