Insights
Improving engagement on digital ads with delayed feedback
By
and
Thursday, 19 September 2019
Introduction
In digital advertising, machine learning models that predict user engagement on advertisements are trained continuously using real-time data. This is necessary due to rapidly changing factors such as audience characteristics and influx of new ads and new users, which all quickly degrade model freshness. However, there is often a delay between the time that an ad is served and the time a user engages with the ad, making it difficult to build a representative data set of ad engagements in real time.
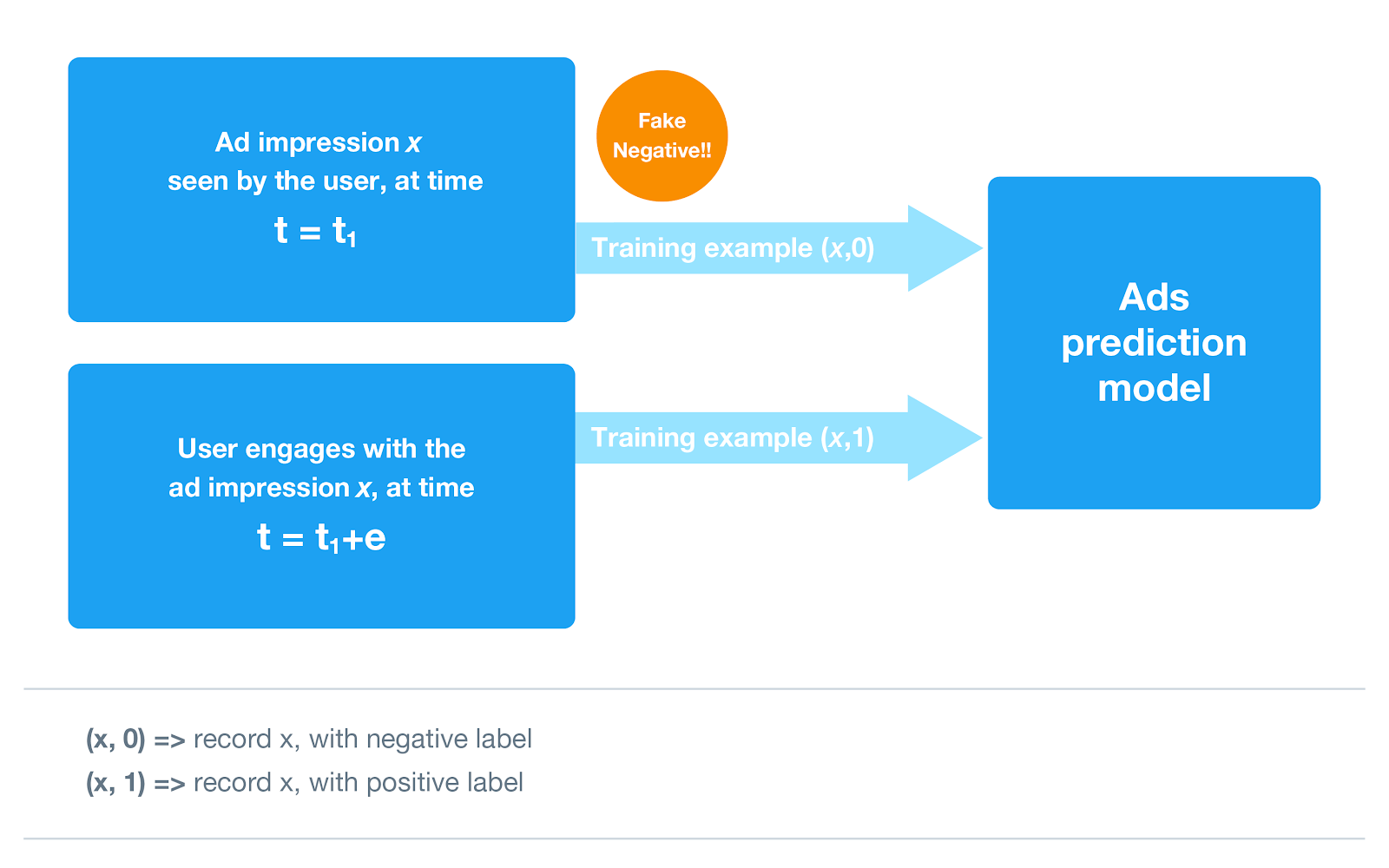
When someone on Twitter refreshes his or her timeline, Twitter serves both organic and promoted content, which are queued for consumption. The ad impressions can be added to the model training set at the time that ads are served, at which point none of the ads have been engaged with. Over a theoretically infinite window of time, users can engage with the queued ads.
At the time of serving, ads can be labeled as negatives (no engagement), or left unlabeled until the user engages with an ad and labeled as positives. The former approach dilutes the training set with fake negative examples, as some of these ads may actually be engaged with in the future. The latter approach requires regular updates to capture positive engagements, which creates both significant infrastructure costs when deployed at huge scale and also runs the risk of deploying a stale model.
To build a model that successfully learns from a continuous stream of data with delayed labels, a team of researchers and engineers at Twitter collaborated to explore several approaches in a large-scale production environment, observing statistically significant improvements in model and revenue performance against the baseline strategy of the naive log loss.
"Ads teams continuously train models on fresh data to account for seasonality, ads campaign changes, and other factors. Unfortunately, customers’ response (e.g., users click on ads) is usually delayed, leading to incomplete labels at the time of model ingestion. The naive approach to consider all delayed data as negative undermines clickthrough rate. Customers end up seeing more ads, and advertisers have a higher cost,” says Sofia Ira Ktena, lead author of Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction. This paper will be presented in September at RecSys 2019, the ACM Conference on Recommender Systems.
Process
The team explored two model architectures and five different loss functions to identify which combination would drive the best performance. They tested both a simple logistic regression model, which has strong precedent of success in online ads, and a wide & deep architecture which increases model complexity at the potential cost of increased latency. Minimizing latency is a key requirement for continuous online training for the ads use-case.
The team paired these model architectures with five loss functions, which used different methods to approximate the opportunity cost of incorrect prediction. In the case of display ads, this opportunity cost represents the expected revenue from serving another ad that would have been clicked instead. The loss functions explored rely on importance sampling, a method of simulating examples from a data set with a known bias, and positive-unlabeled learning. One baseline loss function uses a time-dependent model to inform the predictions. For more details on each loss function, we advise the reader to refer to the original research paper. The loss functions considered include:
- Log loss
- Delayed feedback loss
- Positive-unlabeled loss
- Fake negative weighted loss
- Fake negative calibrated loss
Fake negative weighted loss and fake negative calibration loss are proposed for the first time in this paper. The former uses the current model estimates in the importance weights, while the latter does not alter the training weights, but rather calibrates the output of the model to correct for the bias towards negative labels.
To mitigate risk and understand the benefits of each approach, the team first conducted offline analysis using both historical Twitter data and a public data set from Criteo Labs. The highest performing combinations were then tested online using real-time traffic in Twitter’s ad marketplace.
Results
During offline analysis, the team assesses performance using three key metrics:
- Log Loss: A weighted error measure for classification problems. Log loss increases as the predicted probabilities diverge from the actual label.
- Relative Cross Entropy (RCE): A measure that represents how much better a click predictor is when compared against a straw man of naive prediction (the case when no ad or user features are used in the model).
- Area Under Precision Recall Curve (PR-AUC): A measure that captures the performance trade-off between the true positive rate and the positive predictive value using different success thresholds. Precision is defined as TP / (TP + FP) and Recall is defined as TP / (TP + FN).
The following table shows online results with the wide & deep model and the best performing loss functions (Twitter data). Bold indicates the top-performing method. Differences between the top and second-best method are not statistically significant
Wide & deep - Twitter data
| Loss function |
Loss |
RCE |
PR-AUC |
| Log loss |
0.5953 |
7.81 |
0.5872 |
| Delayed feedback loss |
0.5781 |
12.11 |
0.5781 |
| PU loss |
0.5567 |
13.57 |
0.5927 |
| FN weighted |
0.5568 |
13.54 |
0.5925 |
| FN calibration |
0.5566 |
13.58 |
0.5923 |
In the online experiment, where the approaches were tested on live traffic, the team evaluated success by looking at another set of key metrics:
- Pooled RCE: RCE computed using both treatment and control traffic
- Revenue (RPMq*): Revenue normalized by volume of ads served
- Monetized clickthrough rate: Engagement rate, which measures ads relevance
*RPMq = Revenue per thousand queries
The following table shows online results with the wide & deep model and the best performing loss functions (Twitter data).
Wide & deep - Online experiment
| Loss function |
Pooled RCE |
RPMq |
Monetized CTR |
| Log loss |
7.68 |
100.00 |
100.00 |
| Delayed feedback loss |
12.27 |
137.00 |
118.59 |
| FN weighted |
13.39 |
155.10 |
123.01 |
| FN calibration |
13.37 |
154.37 |
123.19 |
Using these performance metrics, the team found that fake negative weighted loss and fake negative calibration loss using continuous learning showed the best performance. These techniques outperformed the baseline log loss function. Full results can be found in the research paper.
Conclusion
The team successfully deployed the technique of fake negative weighted loss throughout Twitter’s ad production system, where we utilize continuous deep learning. They plan to continue exploring improvements to the loss function to drive model performance.
Twitter’s Revenue Science team is the core ML team behind our revenue engine. The team’s mission is to create value between advertisers and users through the medium of online digital advertising. They combine information about both the user and the ad, matching the most relevant ads to users and determining a fair cost to advertisers.
Twitter’s Cortex team seeks to empower internal teams to efficiently leverage ML by providing platform and modeling expertise, and unifying, educating, and advancing state-of-the-art developments in ML technologies within Twitter.
To further these missions, the teams continuously explore advanced machine learning techniques and state-of-the-art architectures. If you’re interested in working on immense technical challenges, consider joining the flock!
Acknowledgements
The research paper was authored by Sofia Ira Ktena, Aly Tejani, Lucas Theis, Pranay Kumar Myana, Deepak Dilipkumar, Ferenc Huszar, Steven Yoo, and Wenzhe Shi.