In the previous post in our series on distributed training of sparse ML models, we described the techniques we use to build an effective strategy. These techniques combine data parallelism and model parallelism. Here, in our final post of the series, we show the actual gains achieved on some real models deployed at Twitter.
Timelines Tweet ranking model
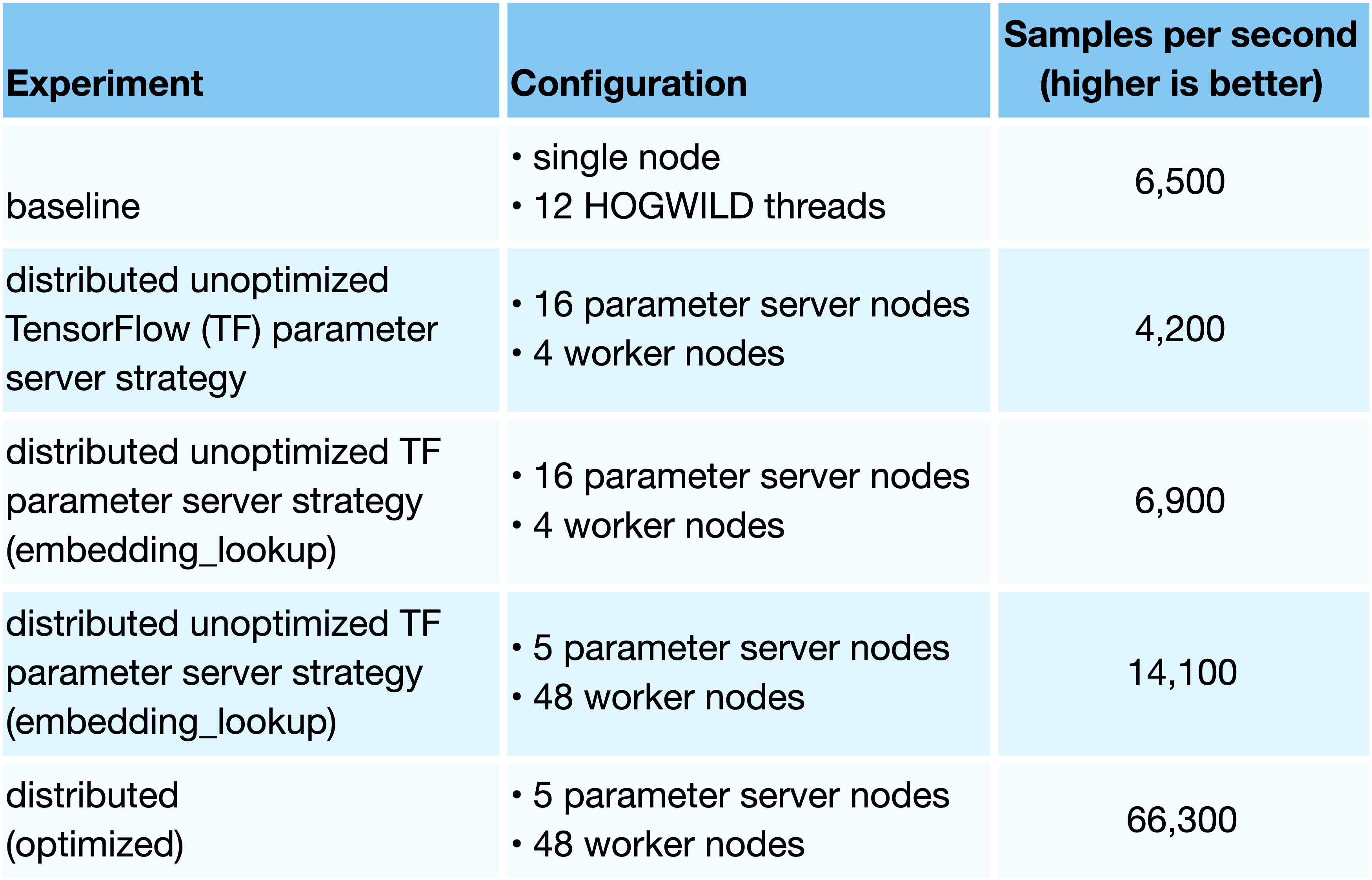
First, we applied these optimizations to train a timelines Tweet ranking model with roughly 23 million weights. The total size of the three sparse layers is 92MB. We trained the model in our data center with egress limits of 150MB/s, and we used the Fully Connected cluster architecture shown in Figure 2.4 of the previous post.
As presented in Table 3.1, we first trained the Tweet ranking model on a single host using 12 local asynchronous (HOGWILD) worker threads. This configuration is the highest training throughput we could achieve using a single node with 64 cores. For distributed training with standard TensorFlow, we experimented with an implementation of the sparse matrix multiply using the TensorFlow embedding_lookup op, which internally has optimizations to reduce network usage. However, the performance of this implementation was still unacceptably slow. We then trained this model in a distributed manner using our optimizations for a speedup of roughly 10.2X under egress limits of 150MB/s.
Ad candidate ranking model
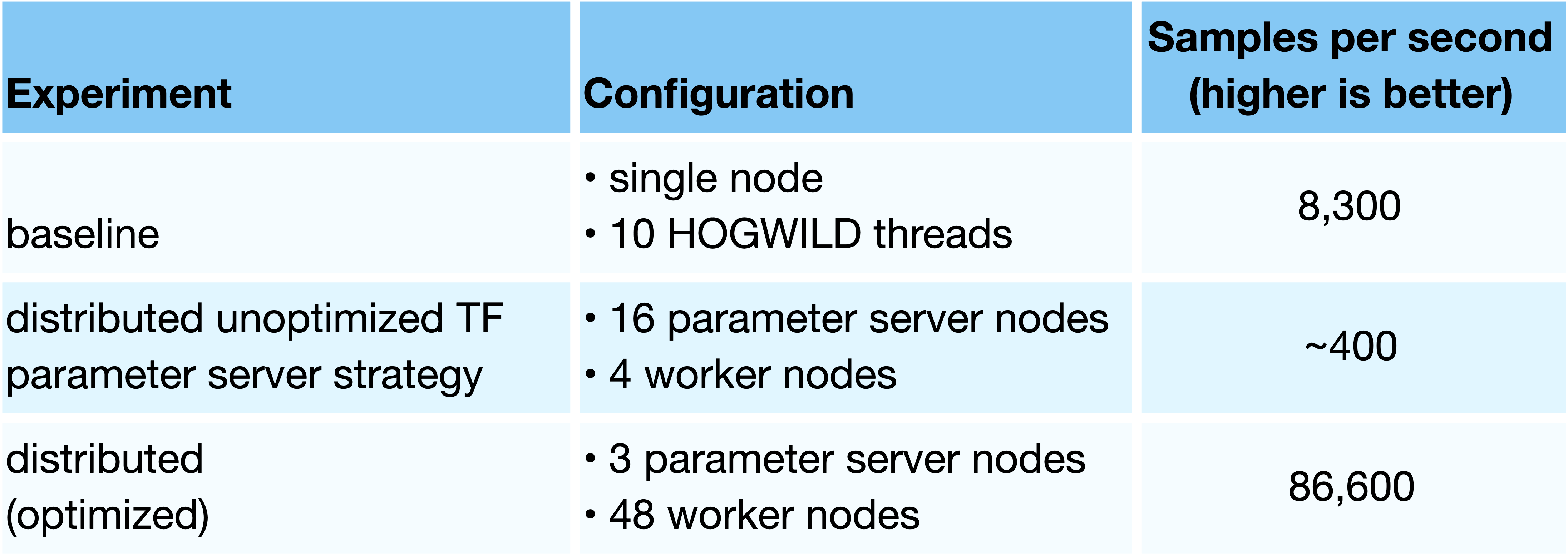
We also applied our optimizations to train a sparse model for ad candidate ranking with roughly 478 million weights. These results are given in Table 3.2. The total size of the sparse layers is 1.9GB. Again, we used the Fully Connected cluster architecture and trained this model in our data center under egress limits of 150MB/s.
We first trained the ads model on a single host using 10 HOGWILD worker threads. This configuration is the highest throughput we could achieve using a single node with 64 cores. We then trained this model in a distributed manner using our optimizations for a speedup of roughly 10.4X over the single-node baseline, and over 200X faster than the standard TensorFlow distributed-training strategy.
Ads video view model
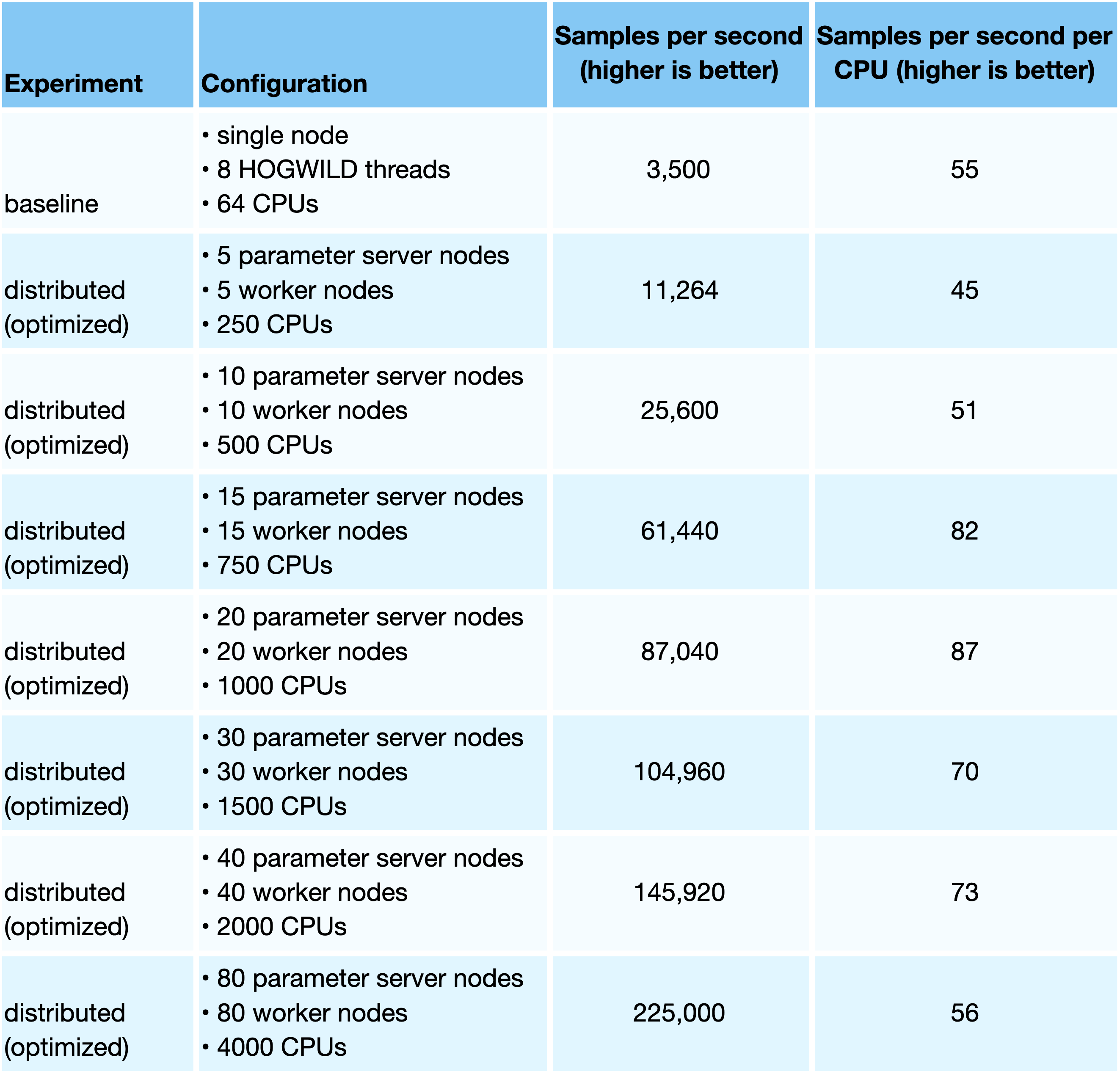
Finally, with results shown in Table 3.3, we used our distributed-training system to train a model for predicting the viewing of video ads in the Home timeline. This model is similar to the ad candidate ranking model discussed above. In this case, we used the Bipartite cluster architecture shown in Figure 2.5 of the previous post. We trained the model in our data center under egress limits of 500MB to 1000MB per second. The variation is due to hosts having varying hardware configurations.
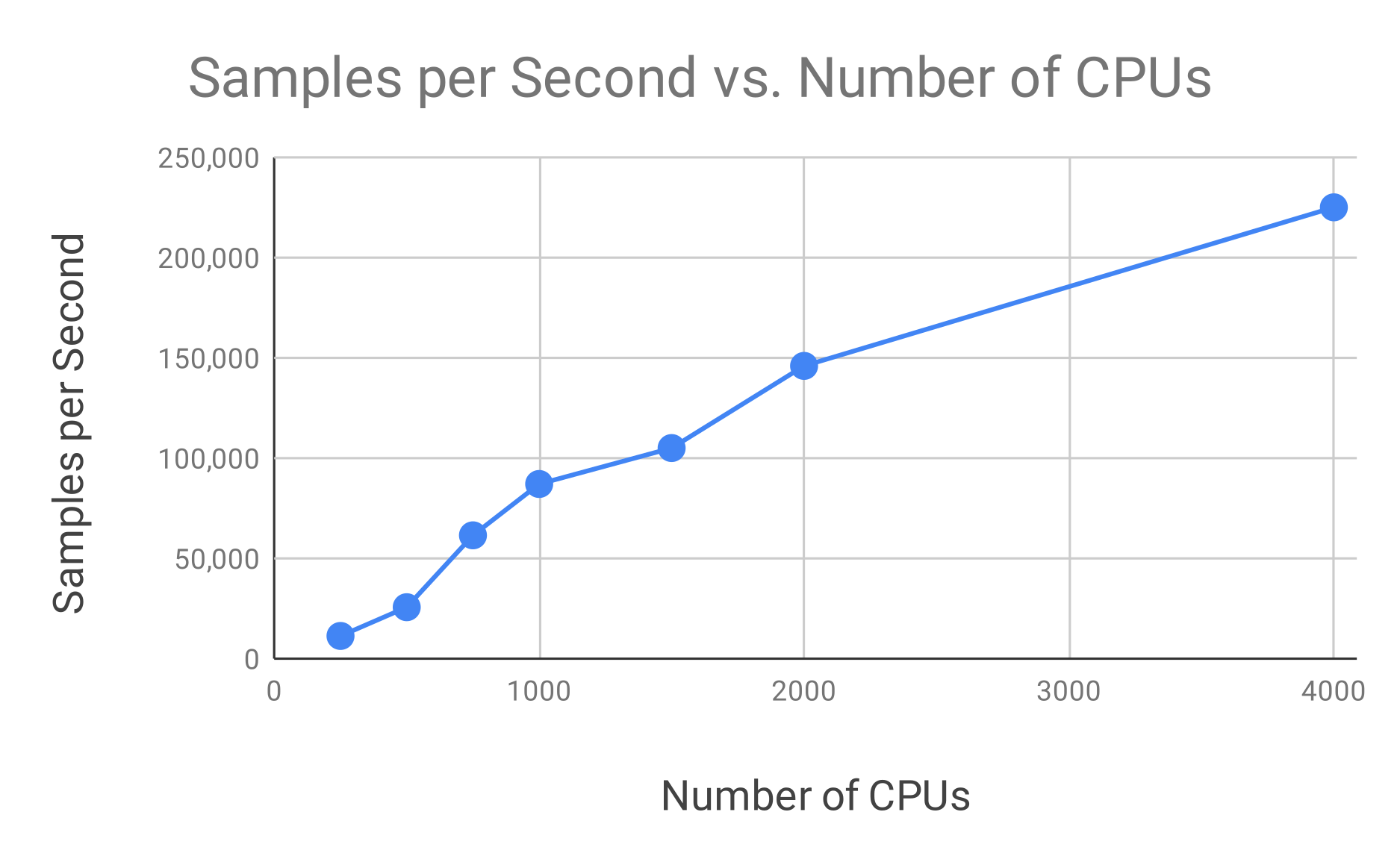
Here, we get more than 60X speedup over our fastest single-node configuration. These results also show that the performance scaling of the training speed versus the number of CPUs allocated is linear for a wide range of cluster configurations. (See Figure 3.1.) In fact, the performance per CPU for distributed training is similar to the single-node setup. When measured in samples per second per CPU, single-node training achieves around 55 samples per second per CPU, while distributed training often does even better, achieving in the range of 45 to 80 samples per second per CPU in the configurations above.
Where do we go from here?
Twitter has a lot of sparse models, but these are not the only models we work with — we also have large language models, image models, sequence models, etc. Optimizing training time for these models will likely involve different strategies from those used for the sparse recommender models.
The solution we've presented is for a particular set of hardware constraints. There are diverse settings, however, in which we can train our models. For example, we may want to use several GPUs. These may be distributed among a number of machines on a network, or they could all be in the same multi-GPU server. We are also expanding our machine learning capabilities to cloud solutions, where there are entirely different capabilities and constraints from what we experience in our own data centers.
Finally, it's our goal to use distributed training in Twitter-scale production ML systems. This goal comes with additional considerations on training jobs that we are currently working to address, including observability, reliability, and alerting.
These innovations represent exciting and challenging opportunities, as we continue to improve the efficiency of the machine learning practice at Twitter.
If work like this excites you, come join the flock.