Insights
Using machine learning to predict the value of ad requests
By
and
Monday, 1 June 2020
Twitter’s Adserver is our revenue engine. Our system, consisting of a number of microservices, processes all incoming ad requests to populate them with relevant ads for users. We receive requests from two predominant supply sources: Twitter.com (apps + web) and MoPub.
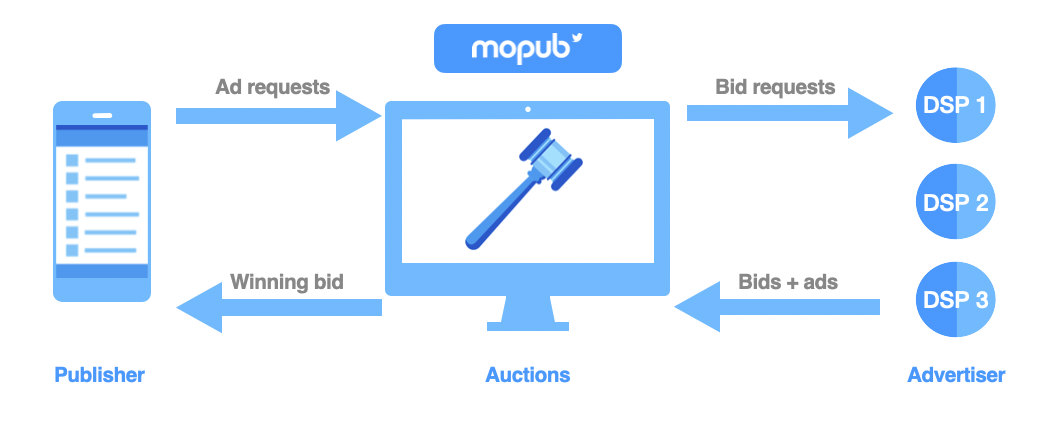
On Twitter, the ads you see are from the search page, another user’s profile or the home timeline (the main source of our revenue). We refer to these as our Twitter Owned and Operated (TOO) products. MoPub, on the other hand, brings 3rd party publisher supply for Twitter advertisers to extend their campaign reach. This is known as the Twitter Audience Platform (TAP).
Twitter has its own sales, marketing and engineering teams to bring advertisers to our platform. Not all app publishers need their own sales team, however, and will often work with platforms like MoPub to help them sell their inventory at scale. MoPub connects these publishers who have “ad inventory” or supply - spaces in their app where they can show ads to users - with advertisers who have demand for this ad inventory.
Through MoPub, we are able to reach over a billion users across a number of popular apps. TAP specifically refers to advertisers who come to Twitter, but would like to show their ads on apps from MoPub publishers.
Twitter advertisers often value TOO inventory differently due in part to its engaged audience and unique platform content. As a result, we needed to find a way to balance the ad requests from TOO and TAP, accounting for the difference in value of the two types of ad requests.
To solve this problem, we initially used a heuristic solution to get an idea of how “valuable” an ad request was. We used a set of intuitive features to represent each ad request, such as device ID and app category. We then keep track of how often the Adserver returns eligible ad candidates for requests containing these specific features. If there have been no candidates successfully returned in a while, the next time we see those features we just drop the request without doing further processing. For example, the table we use to keep track of these stats could look like this:
| Device ID | App Category | Number of requests with zero impressions |
| Device1 | App1 | 0 |
| Device2 | App1 | 8 |
| Device3 | App1 | 2 |
We see that for Device1 and App1, we haven’t had any requests with zero impressions. This can either mean that we recently showed an ad to Device1 through App1, or that this is a new (device, app) pairing that we haven’t seen before. In either case, our heuristic filter wouldn’t filter out the next request from (Device1, App1).
However, we see that the last 8 times we had an ad request from Device2 through App1, we weren’t able to find appropriate ads to show. So the next time we get a request from (Device2, App1), we won’t allow it through our filter as it’s only likely to waste computational power. For Device3, whether it passes through the filter depends on our exact threshold. If our threshold was set at 3 for instance, we would allow the request to be processed this time, but if it fails to find an ad again, we’ll update the table and then filter it out on the following request.
While this was a simple heuristic solution, this did a great job of removing a large number of low-value ad requests to save processing power, which could instead be utilized to serve the high-value TOO requests.
This solution worked in the short-term, but it did come with certain disadvantages. It meant that we relied on the Adserver mechanism to naturally sort out valuable ads from less valuable ones, and required us to tune a threshold to decide which requests to let through. It’s easy for heuristics like these to fail quietly, meaning that some small change could cause the threshold we use to no longer be valid and break the system. We thus wanted to come up with a more robust and reliable solution to this problem. In other words, we had to find a way to predict how valuable a request is (in terms of how much revenue it can generate) based on a few simple request features. It seemed natural to turn to machine learning for this task.
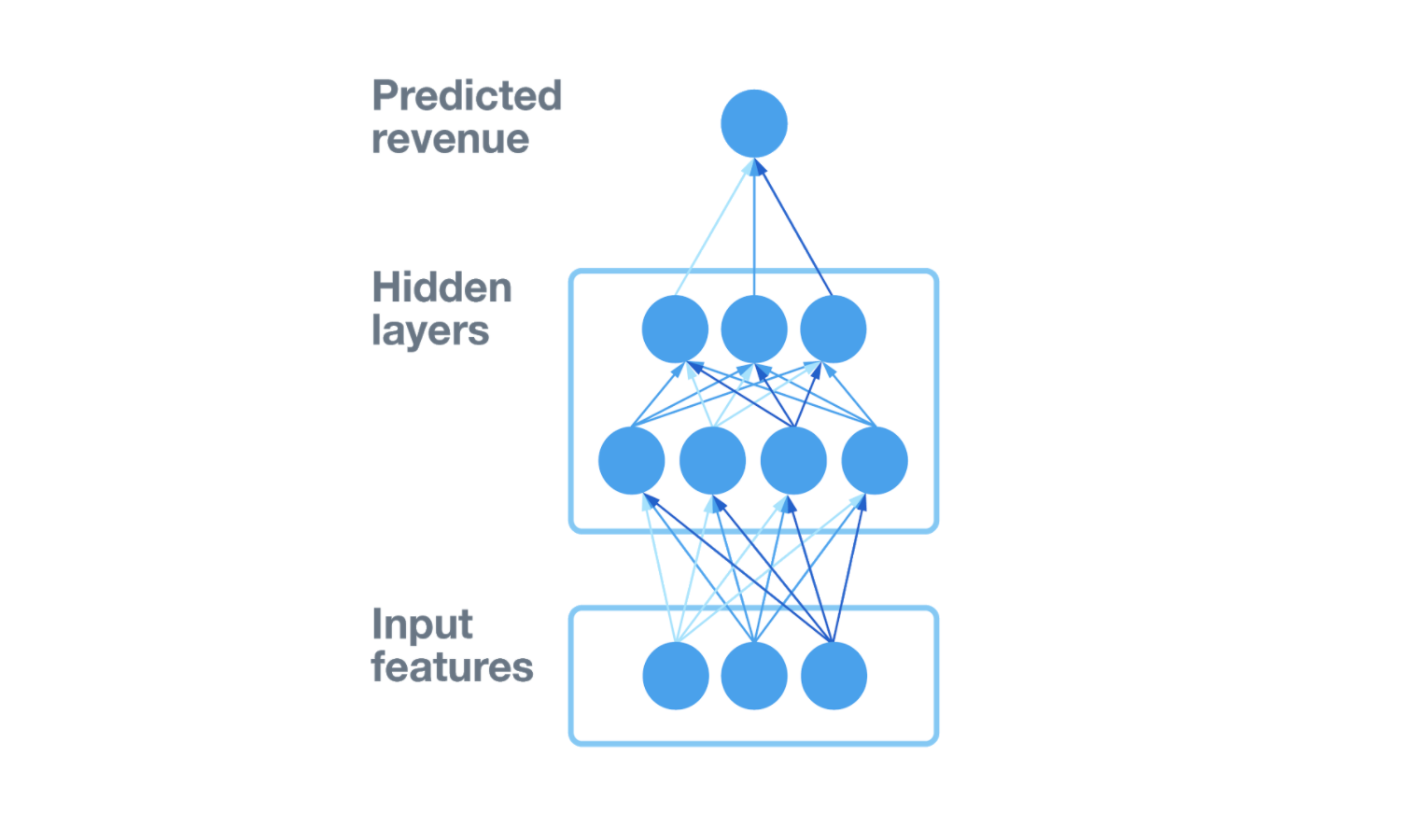
This ML model would be running very early on in the pipeline to filter out invaluable requests. It was vital that this model be lightweight and not add too much latency to the overall system. After some experiments, we decided on a simple feedforward neural network with low depth and width to trade off accuracy and speed. We used very similar features to the previous heuristic filter, and as a label we used essentially the revenue for that request.
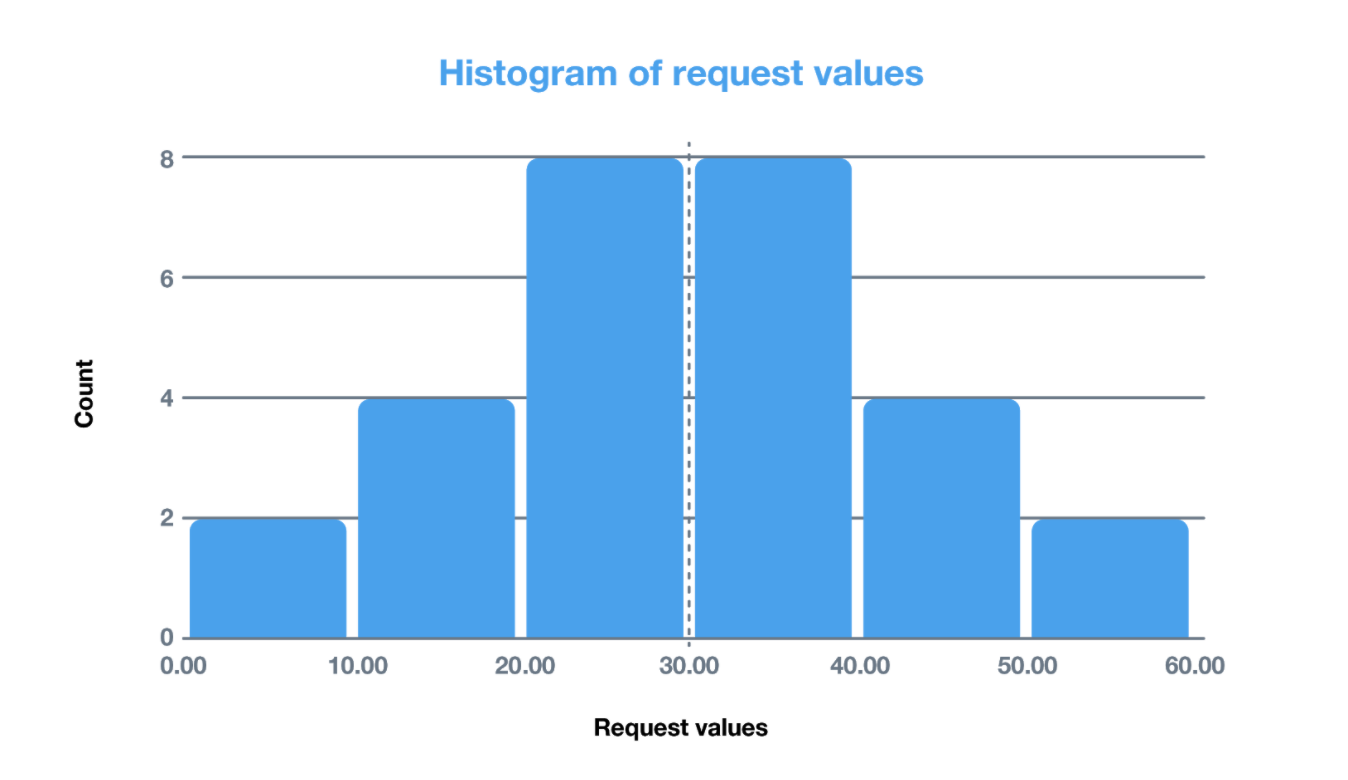
This model is trained continuously, and outputs a new updated model every hour to be picked up and used to prioritize new requests. To do this, we keep track of a histogram of model scores for recent requests. We have a single parameter to control this system - the percentage of incoming requests that need to be let through. The histogram helps us to set a model score threshold based on this percentage, and we then use this threshold to decide which requests have a high enough score to warrant further processing. For example, suppose we had this histogram of recent predicted revenue values for each request:
If we wanted to allow 50% of the requests to pass through, we would have our cutoff threshold as 30, as only 50% of historical requests have had a predicted value higher than 30.
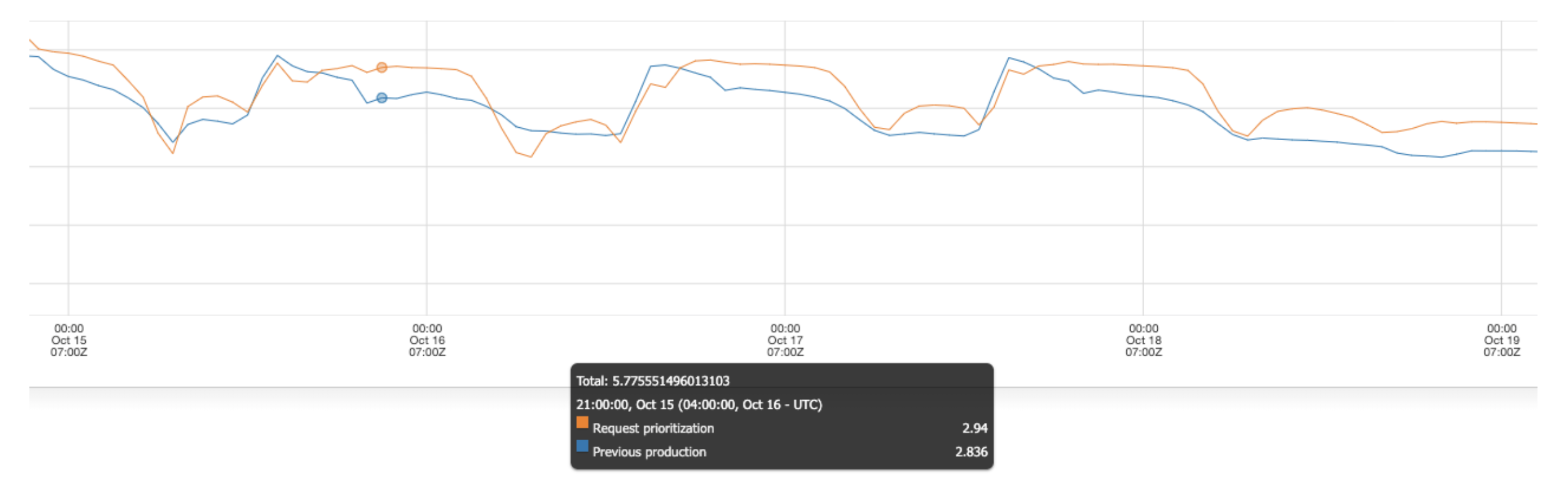
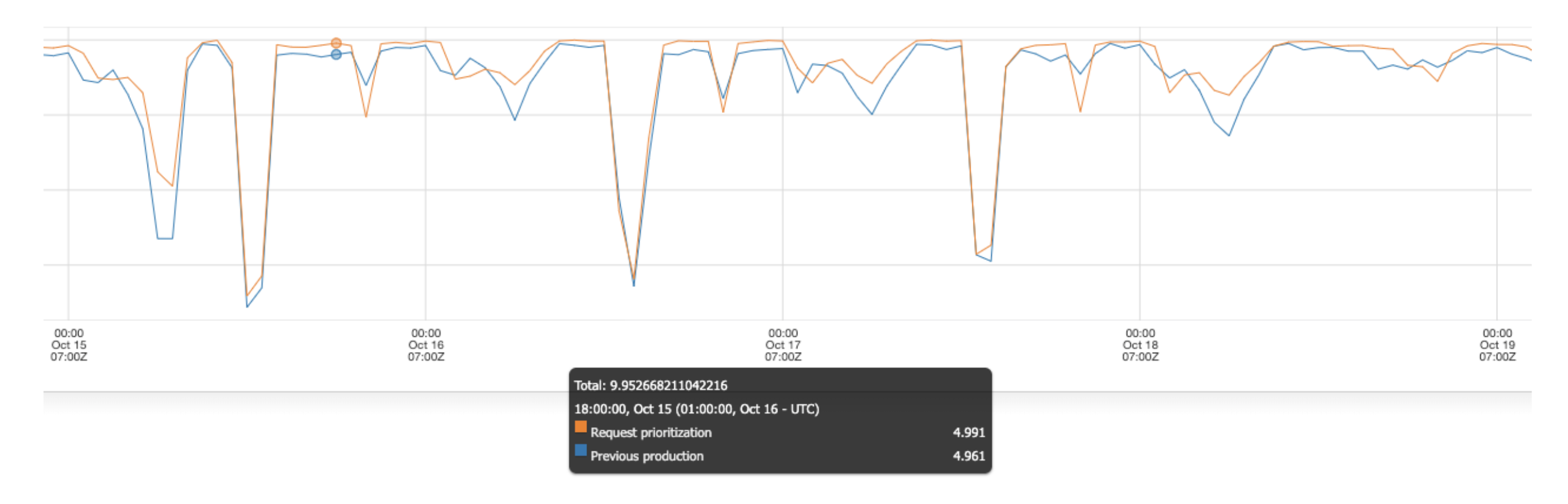
This effort reduced the number of TAP requests processed by more than half, while still increasing net revenue by serving more valuable requests that the previous heuristic filter was removing. Choosing more valuable requests to serve meant that a number of our product metrics went up as well. Overall, we are much more efficient in terms of utilizing limited computational power well. Here’s a graph showing the drop in requests processed:
We measure our system performance using a metric called QF (quality factor). With this change, we saw that the QF for TAP went up:
Another indication that we were being more efficient with our computation were system metrics for our TOO locations, specifically Timeline Home (TLH). We saw that TLH metrics improved, with request timeouts going down and QF being generally higher:
So this was a double win - we improved TAP revenue by serving more valuable TAP requests, and we improved TOO system metrics by dropping invaluable TAP requests and using the additional computation for TOO. All this with a model smaller than 3MB!
Using a simple ML model, we were able to increase Twitter’s revenue and improve computational efficiency. This paves the way for improvements in terms of request processing efficiency on TOO. Instead of having a binary decision to serve or not serve a request, as an example, we could use an amount of computational power proportional to the predicted value of the request. In other words, we’d spend more effort processing requests that we believe are capable of generating more revenue.
Ultimately, while applying state-of-the-art deep learning techniques can be impactful, applying simple models in the right contexts can prove to be more beneficial than one might expect.
The core request prioritization system was built by Deepak Dilipkumar, Eugene Zax, Yuanlong Chen, Rafael Barreto, Sheng Chang and James Gao and the broader Ads Prediction, Exchange Backend, Exchange Data and Ads Serving teams. We would like to thank Justina Chen, Chris Chon, Corbin Betheldo, Steven Yoo, Dasha Semenova, Srinivas Vadrevu and Luke Simon for their product support and leadership. We would also like to thank Alicia Vartanian for designing the illustrations in this post.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.