Insights
Forecasting SQL query resource usage with machine learning
By
Friday, 5 November 2021
The Interactive Query team at Twitter is pursuing high scalability and availability to fulfill the increasing need for data analytics on a petabyte (PB) scale of data. To overcome performance issues that can arise in developing and maintaining SQL systems with increasing volumes of data, we designed a large-scale SQL federation system across on-premises and cloud Hadoop and Google Cloud Storage (GCS) clusters.
We did this by leveraging Presto as the core of our SQL engine clusters. The SQL federation system, together with other projects under the umbrella of “Partly Cloudy”, paves the path for democratizing data analytics and improving productivity at Twitter.
During the daily operation of our large-scale SQL system, we found that not forecasting SQL-query resource usage created unique problems such as:
To forecast the query resource usage, pre-existing database management system (DBMS) approaches usually use query plans generated from SQL engines. This approach limited our ability to predict resource usage for query scheduling and preemptive scaling when we did not use SQL engines.
By contrast, we now leverage machine learning techniques to train two models on historical SQL query request logs for CPU time and peak memory prediction. In this blog post, we will elaborate on our journey at Twitter of establishing a prediction system for SQL query resource usage that is based in machine learning.
The blog post is based on the paper C. Tang, B. Wang et al., “Forecasting SQL Query Cost at Twitter”, 2021 IEEE 9th International Conference on Cloud Engineering (IC2E).
At Twitter, each SQL query processed by the SQL federation system generates a request log record. The query-cost prediction system uses request logs as the raw dataset for training. Each request log sample contains query-related information, including the unique identifier, user name, environment, and query statement. Logs from the last three months (90 days) are a good indicator for forecasting the cost of online queries from our experiments. Such a typical dataset consists of around 1.2 million records and more than 20 columns.
The training cluster performs the machine learning computation for model training. We train two machine learning models, a CPU model and memory model, from historical request logs for CPU time and peak memory prediction. The training cluster does the following:
The model repository manages the trained models and stores them in a central repository such as GCS. The serving cluster fetches models from the model repository and wraps the models into a web-based prediction service. This process exposes RESTful API endpoints for external requests. These endpoints can be used to forecast the CPU time and peak memory for online SQL queries from notebook/BI tools (for customers to obtain an estimate of query resource usage) and the router (for query scheduling and preemptive scaling).
Prior DBMS statistical approaches apply regression techniques, such as time-series analysis, to solve DBMS problems. However, as the distribution of SQL-query resource usage follows a power law, conventional regression approaches are challenging to use due to the large fluctuation in the tail of the distribution.
Moreover, we noticed that quick estimates of resource consumption, scheduling, and scaling do not require an accurately predicted value for customers and the router. Instead, we need to know whether a query is a low resource-consuming query, a medium one, or a high one. Because of this need, we apply data discretization to the raw dataset, transforming the continuous data to discrete data.
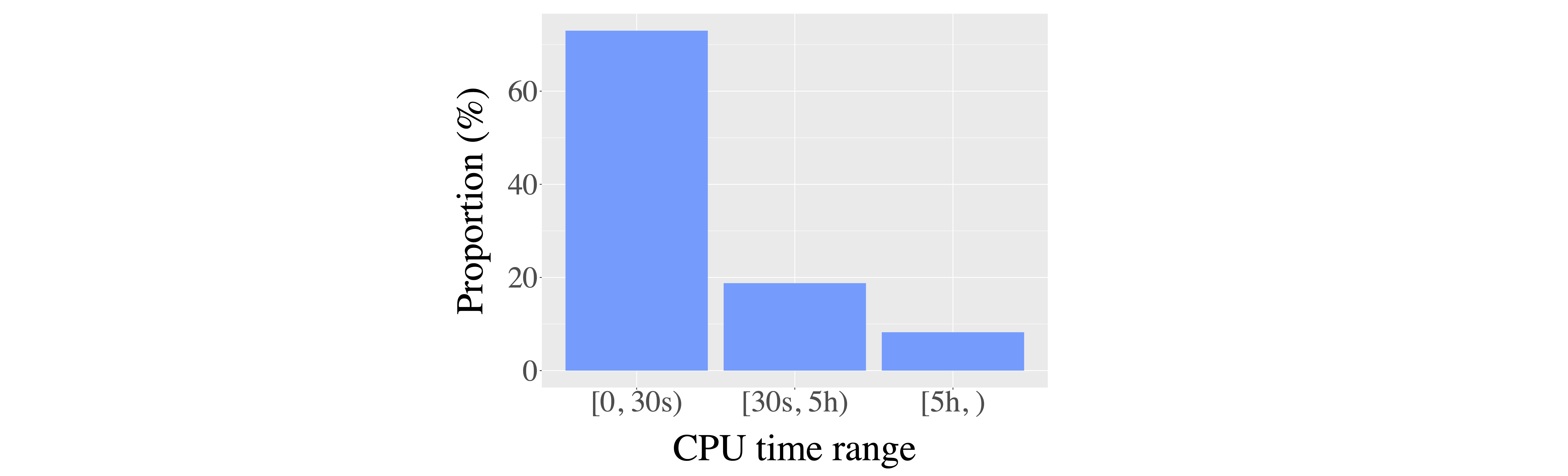
How do we group these queries? First of all, we select 5 hours and 1 TB as thresholds for high CPU usage and memory usage respectively. This is because these are the prior thresholds we applied in our SQL federation system and were obtained from our operational experience in running analytical queries.
For CPU time, based on our DevOps experience, we consider queries whose CPU time is less than 30 seconds as lightweight queries. This also helps us capture the large proportion of queries that are in the range [0, 30s), which includes more than 70% of total queries. By contrast, only 1% of queries fall in the range of [30s, 1min).
For peak memory, we found that the distribution tends to be more evenly distributed. As a result, we generally evenly categorize the queries whose peak memory is lower than 1 TB and select 1 MB as the boundary for low and medium-memory-consuming queries.
In summary, we categorize:
After the dataset is transformed, we partition the dataset into a training dataset (80% of queries) and a testing dataset (20% of queries).
We apply vectorization techniques from Natural Language Processing (NLP) to generate essential features for the transformed dataset with peak memory and CPU time categories. Each SQL statement is mapped to a vector of numbers for subsequent processing using vectorization. This makes running classification algorithms on text-based data easier.
We employ bag-of-words (BoW) models, in which each word is represented by a number such that a sequence of numbers can represent a SQL statement. Word frequencies are a typical representation. We also use term frequency-inverse document frequency (TF-IDF) values, a popular representation, to generate features. BoW models are known for their high flexibility. In addition, they can be generalized to a variety of text data domains.
BoW models produce features without computing in a SQL engine or communicating with a metadata store. We do not use table-specific statistics for feature engineering as this type of data requires additional costs for analyzing SQL statements and fetching table-related metadata.
We also observed that tree-based machine learning algorithms, such as XGBoost, that allow for easy interpretation of feature importance, can capture some SQL-related features such as access to specific tables and usages of time ranges. These features are usually used in traditional query plan-based cost models. This implies that machine learning techniques can also help developers gain insights from large-scale SQL systems.
After preparing the features extracted from TF-IDF, we use XGBoost, a tree-based gradient boosting approach, to train classifiers from the training dataset. A 3-fold cross-validation is used to find the optimal hyperparameters. Then, we test the trained classifiers on the testing dataset. The CPU model achieves 97.9% accuracy, and the memory model achieves 97.0%.
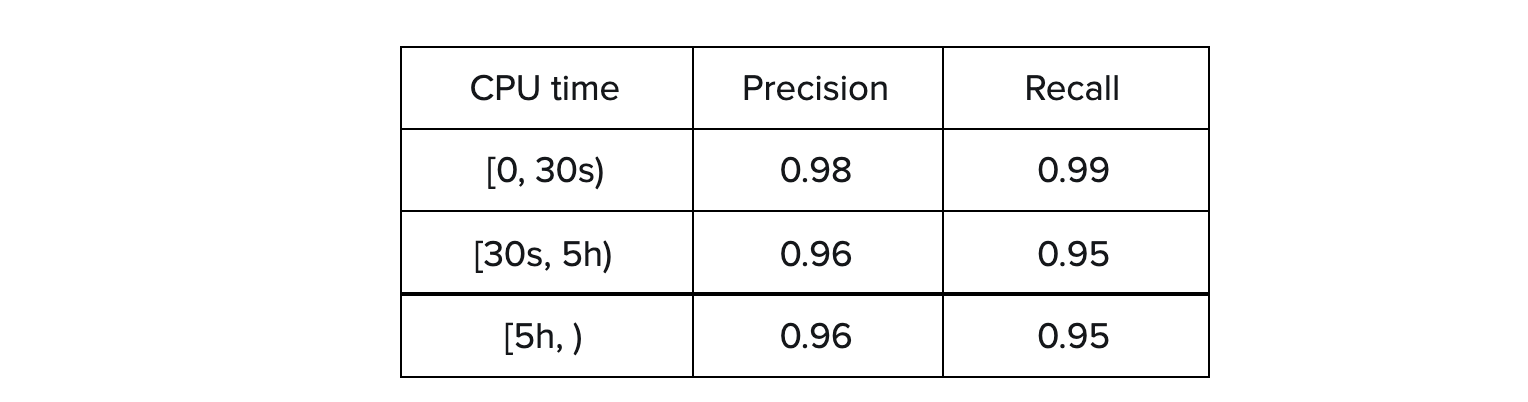
Accuracy is a popular metric to evaluate model performance, but it is not the only one. In particular, considering the imbalanced classes in the training dataset, a high overall accuracy does not always indicate a high capability of predicting all classes. High accuracy of classifying a class containing a dominant number of samples can conceal the low accuracy of predicting classes with smaller numbers of samples.
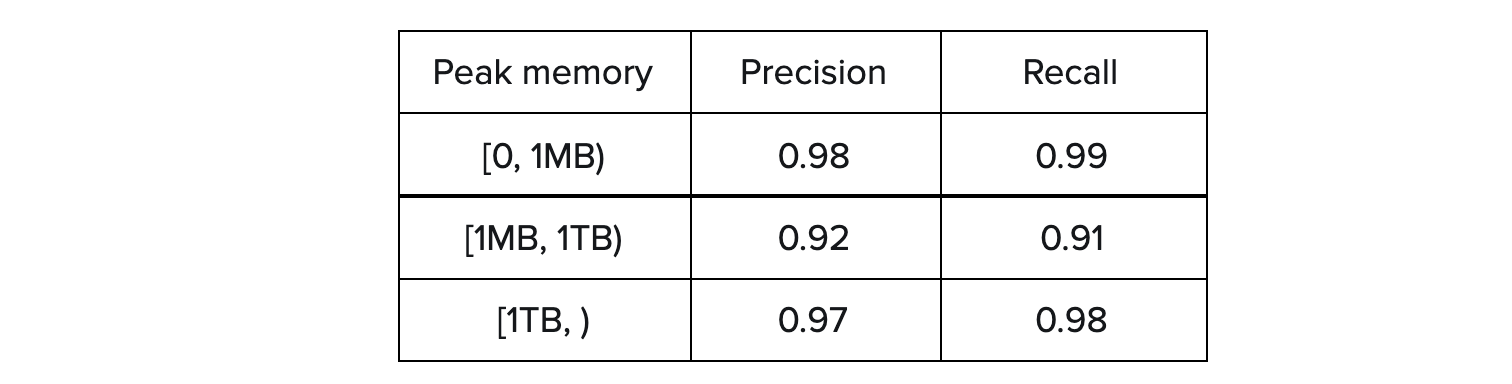
To overcome the potential issue here, we also consider the precision and recall of each class, especially the classes representing CPU or memory-intensive queries. In the tables below, our models achieve high precision and recall for all classes, as well as high overall accuracy. Particularly, they reach no less than 0.95 of precision and recall for resource-consuming queries: [5h, ) and [1TB, ).
After the models are trained and tested, we wrap the models into a web application for real-time production traffic serving. The service, held in the serving cluster, is deployed in Aurora containers on Mesos, the stack widely used at Twitter. As each deployment unit is stateless, the application's scalability can be enhanced by increasing the number of deployment replicas. The service exposes two RESTful API endpoints to forecast CPU time and peak memory of a SQL query. The inference time is around 200 milliseconds.
With machine learning techniques, we developed a SQL-query-cost prediction system to accurately (>97%) forecast the CPU time and peak memory consumption of SQL queries. Unlike prior work, the system learns from plain SQL statements and builds machine learning models from historical query request logs without dependency on any SQL engines or query plans. We believe the approach described in this blog post can provide an innovative solution for traditional infrastructure-related performance optimization.
We would like to express our gratitude to Beinan Wang, Zhenxiao Luo, Huijun Wu, Shajan Dasan, Maosong Fu, Yao Li, Mainak Ghosh, Ruchin Kabra, Nikhil Kantibhai Navadiya, Da Cheng, Fred Dai, Prachi Mishra, and Prateek Mukhedkar for their contributions to this project.
We are also grateful to Vrushali Channapattan, Daniel Lipkin, and Derek Lyon for their strategic vision, direction, and support. Finally, we thank Bethany Lechner, Megan Martin, Brenna Sanford, Ramia Davis, Alex Angarita Rosales, Neal Cohen, and Shrut Kirti for their insightful suggestions that helped us significantly improve this blog.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.