Insights
GNNs through the lens of differential geometry and algebraic topology
By
Tuesday, 14 December 2021
Differential geometry and algebraic topology are not encountered very frequently in mainstream machine learning. In a series of recent works, we show how tools from these fields can be used to reinterpret Graph Neural Networks and address some of their common plights in a principled way.
“Symmetry, as wide or as narrow as you may define its meaning, is one idea by which man through the ages has tried to comprehend and create order, beauty, and perfection.”
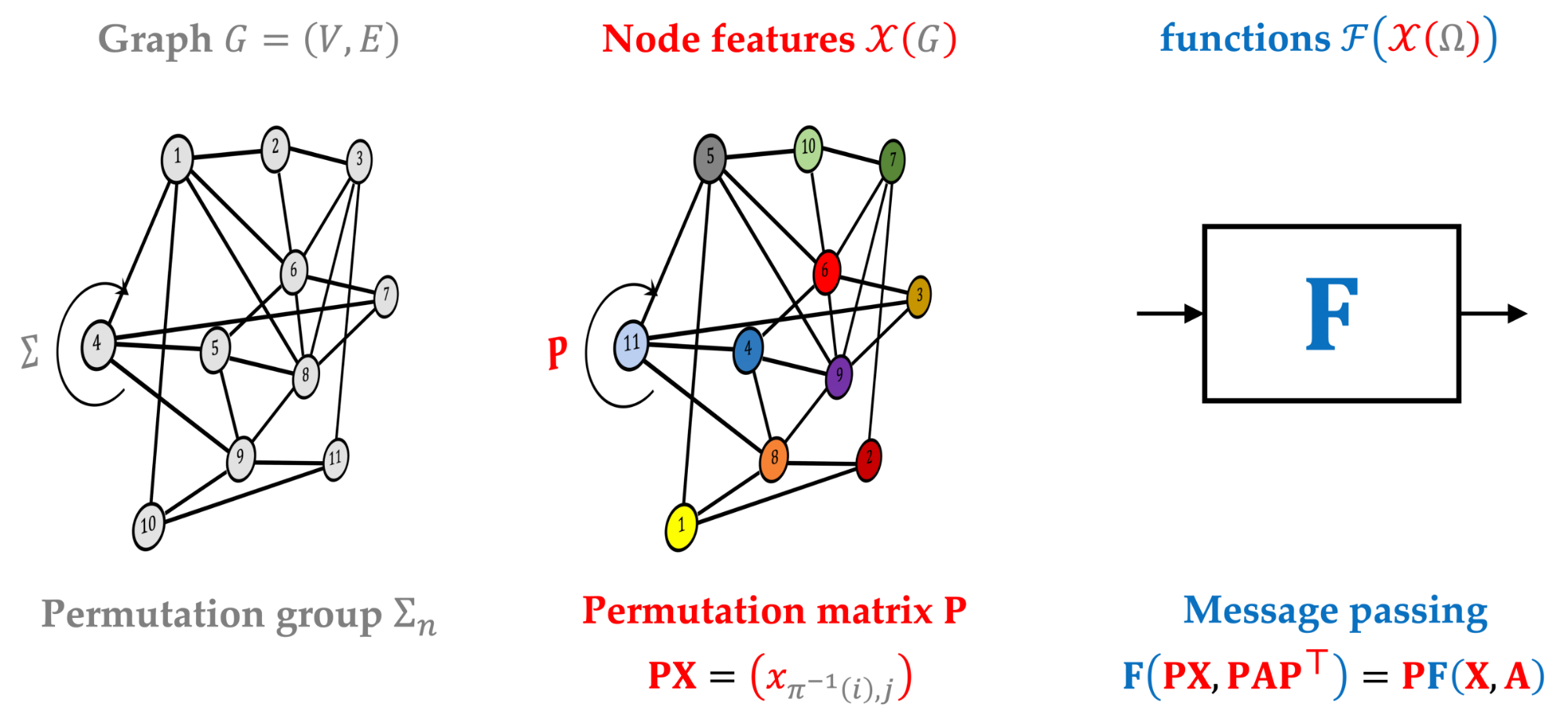
This somewhat poetic description by Hermann Weyl [1] underlines the cornerstone role of symmetry in science. Felix Klein’s 1872 “Erlangen Programme” [2] characterized geometries through symmetry groups. Not only was this a breakthrough in mathematics, unifying the “zoo of geometries,” but also led to the development of modern physical theories that can be entirely derived from the first principles of symmetry [3]. Similar principles have emerged in machine learning under the umbrella of Geometric Deep Learning, a general blueprint for deriving the majority of popular neural network architectures through group invariance and equivariance [4].
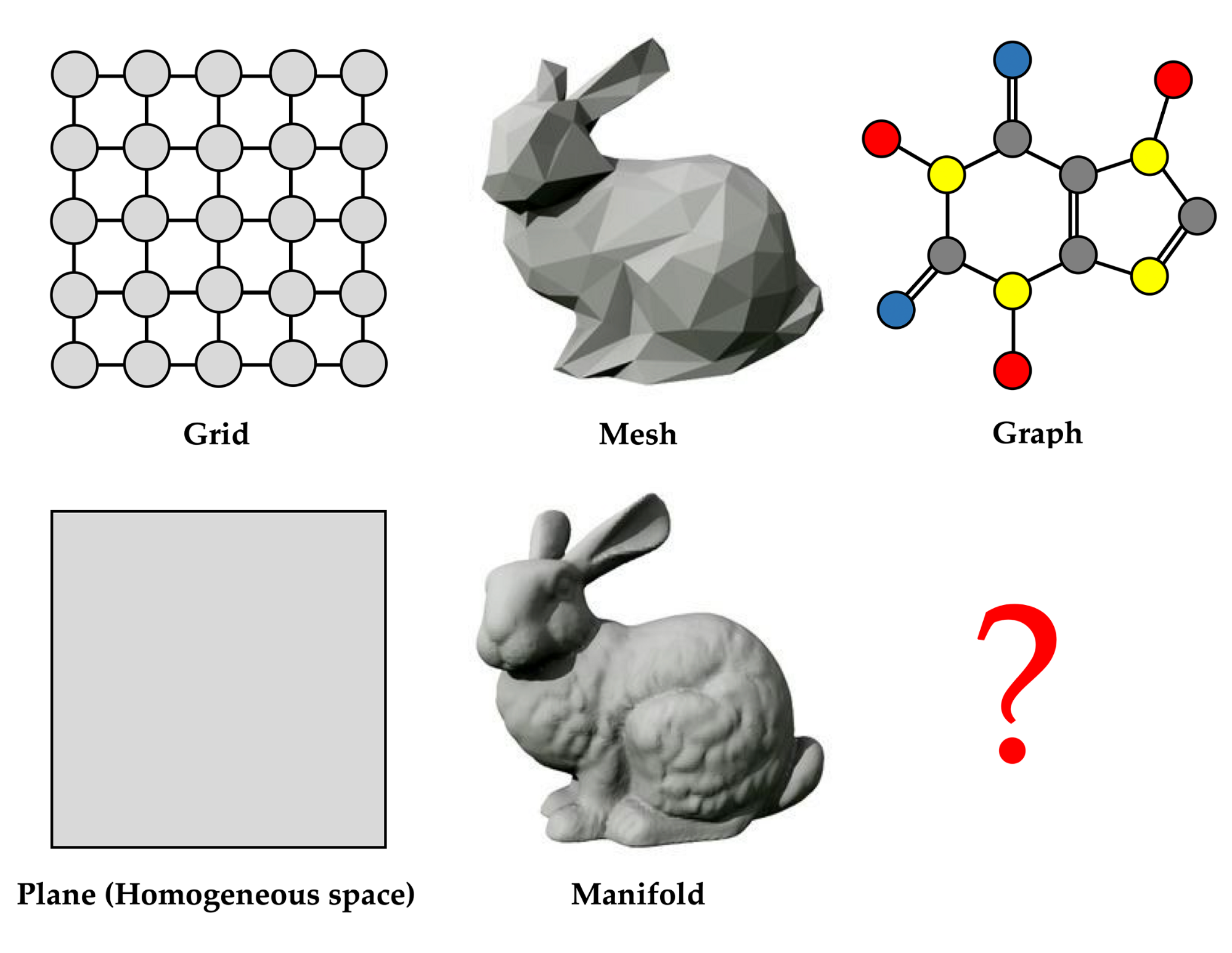
The Geometric Deep Learning Blueprint can be applied to different domains, such as grids, meshes, or graphs [5]. Yet, while the former two have clear continuous analogy objects (grids can be considered as a discretization of Euclidean or more generally homogeneous spaces such as the sphere, and meshes are a common discretization of 2-dimensional manifolds), there is no immediate continuous analogy for graphs [6]. This inequity is somewhat disturbing and motivates us to take a closer look at continuous models for learning on graphs.
Graph Neural Diffusion. Graph Neural Networks (GNNs) learn by performing some form of message passing on the graph, whereby features are passed from node to node across the edges. Such a mechanism is related to diffusion processes on graphs that can be expressed in the form of a partial differential equation (PDE) called “diffusion equation”. In a recent ICML paper [7], we showed that the discretization of such PDEs with nonlinear learnable diffusivity functions (referred to as “Graph Neural Diffusion” or GRAND) generalizes a broad class of GNN architectures such as Graph Attention Networks (GAT) [8].
The PDE mindset offers multiple advantages, such as the possibility to exploit efficient numerical solvers (e.g. implicit, multistep, adaptive, and multigrid schemes) with guaranteed stability and convergence properties. Some of these solvers do not have an immediate analogy among popular GNN architectures, potentially promising new interesting Graph Neural Network designs. Such architectures might be more interepretable than the typical ones, owing to the fact that the diffusion PDE we consider can be seen as the gradient flow [9] of some associated energy.
At the same time, while the GRAND model offers continuous time in the place of layers in traditional GNNs, the spatial part of the equation is still discrete and relies on the input graph. Importantly, in this diffusion model, the domain (graph) is fixed and some property defined on it (features) evolves.
A different concept commonly used in differential geometry is that of geometric flows, evolving the properties of the domain itself [10]. This idea was adopted in the 1990s in the field of image processing [11] for modeling images as manifolds embedded in a joint positional and color space and evolved them by a PDE minimizing the harmonic energy of the embedding [12]. Such a PDE, named Beltrami flow, has the form of isotropic non-euclidean diffusion and produces edge-preserving image denoising.
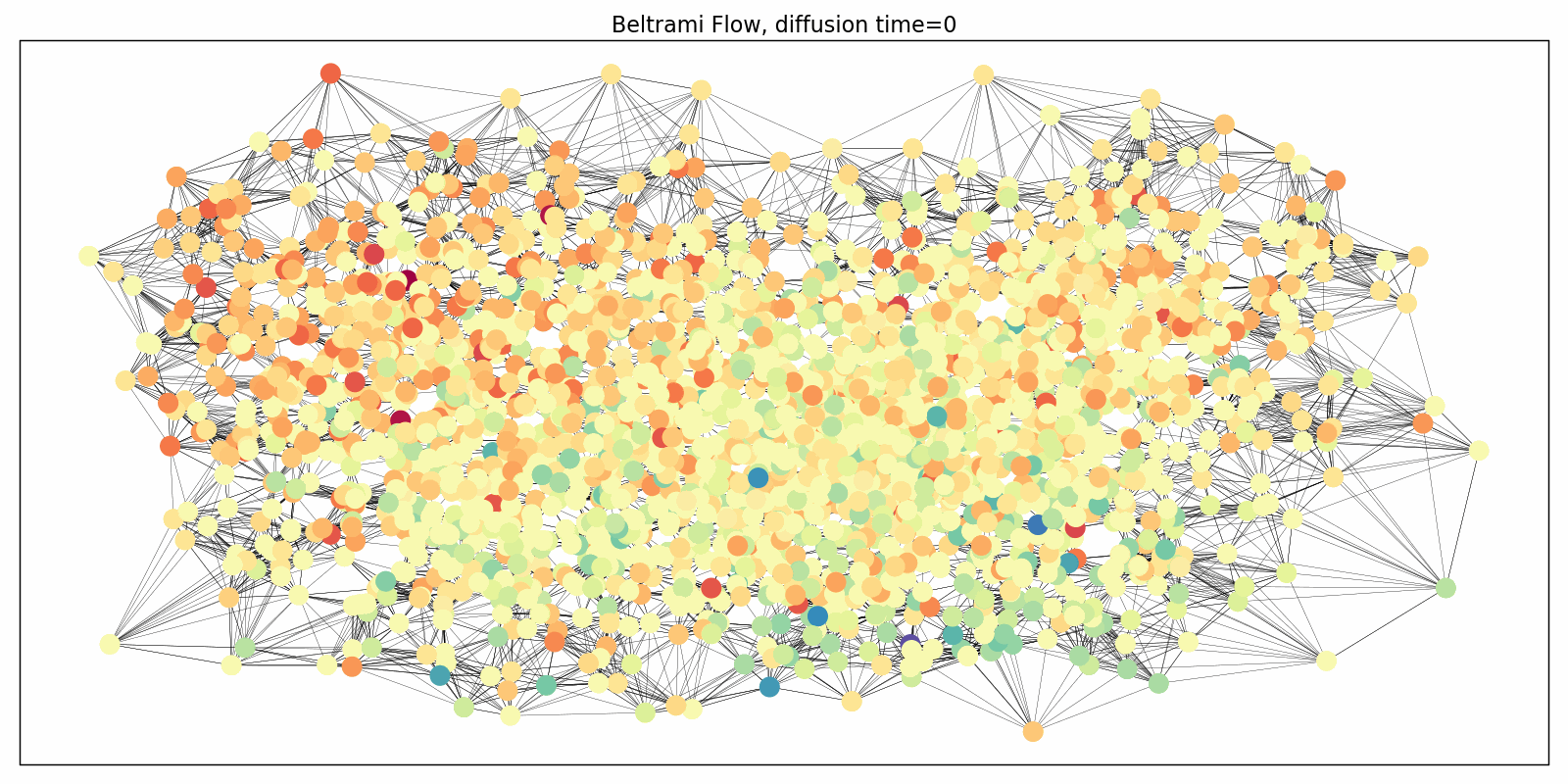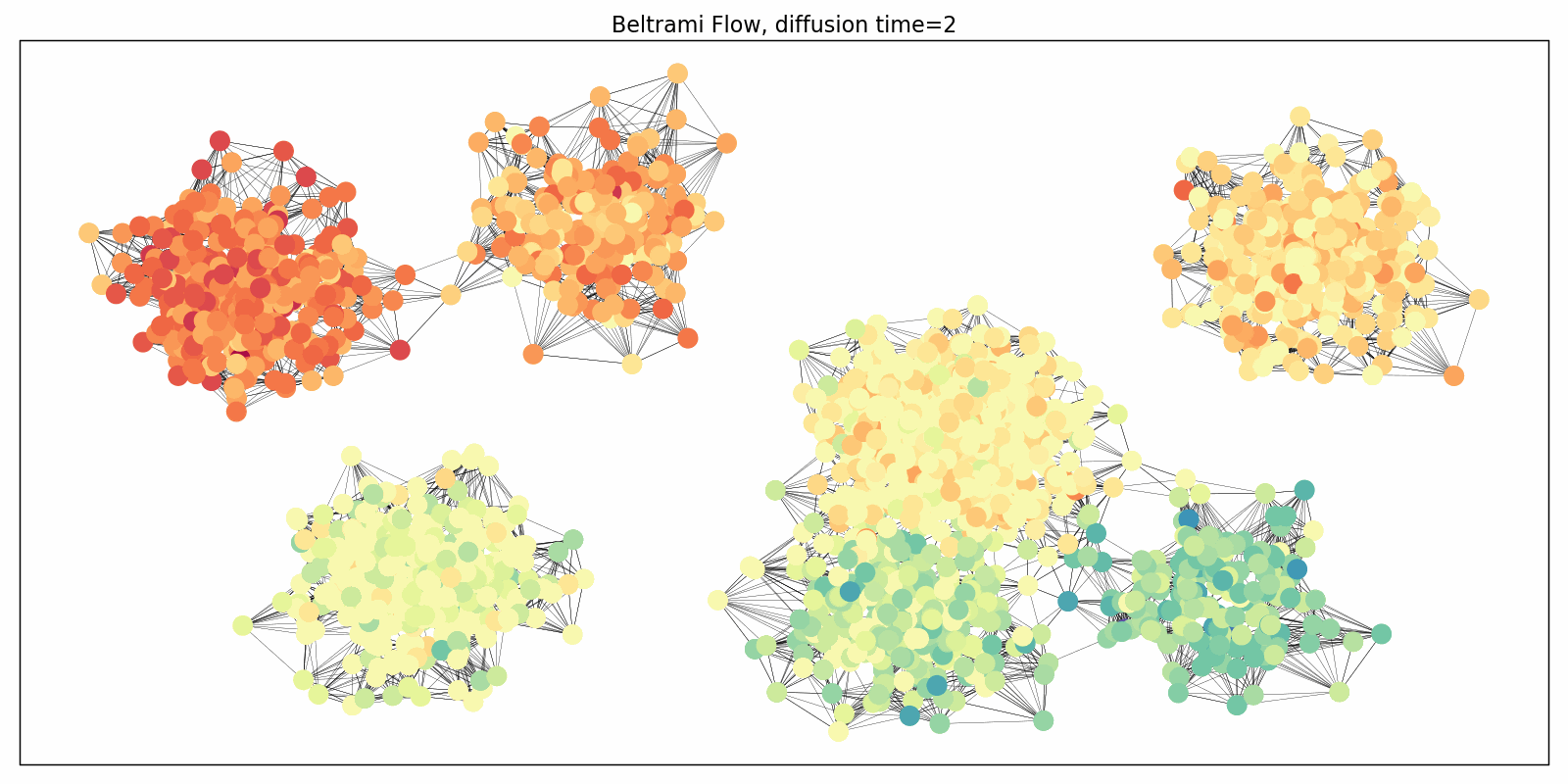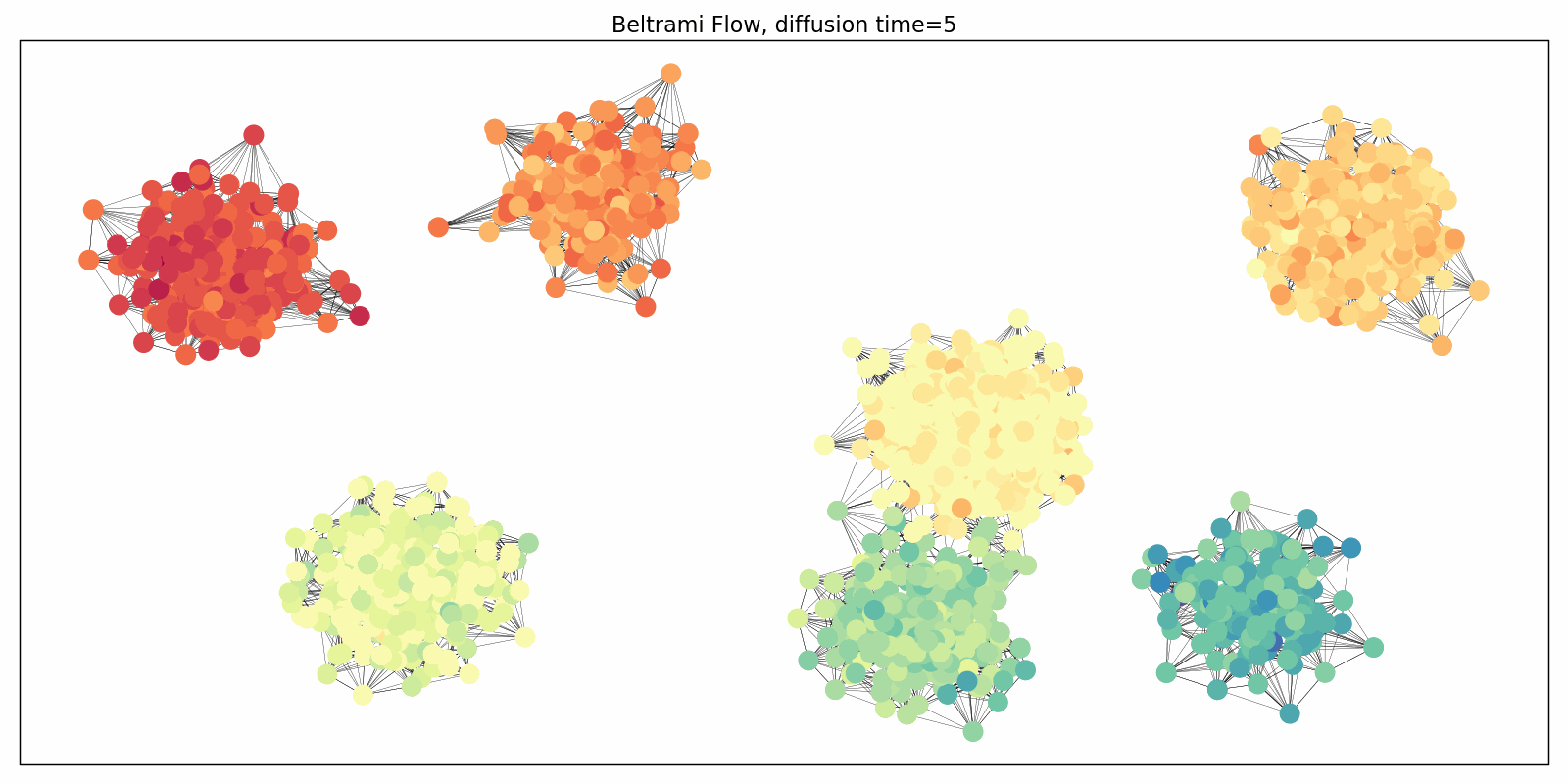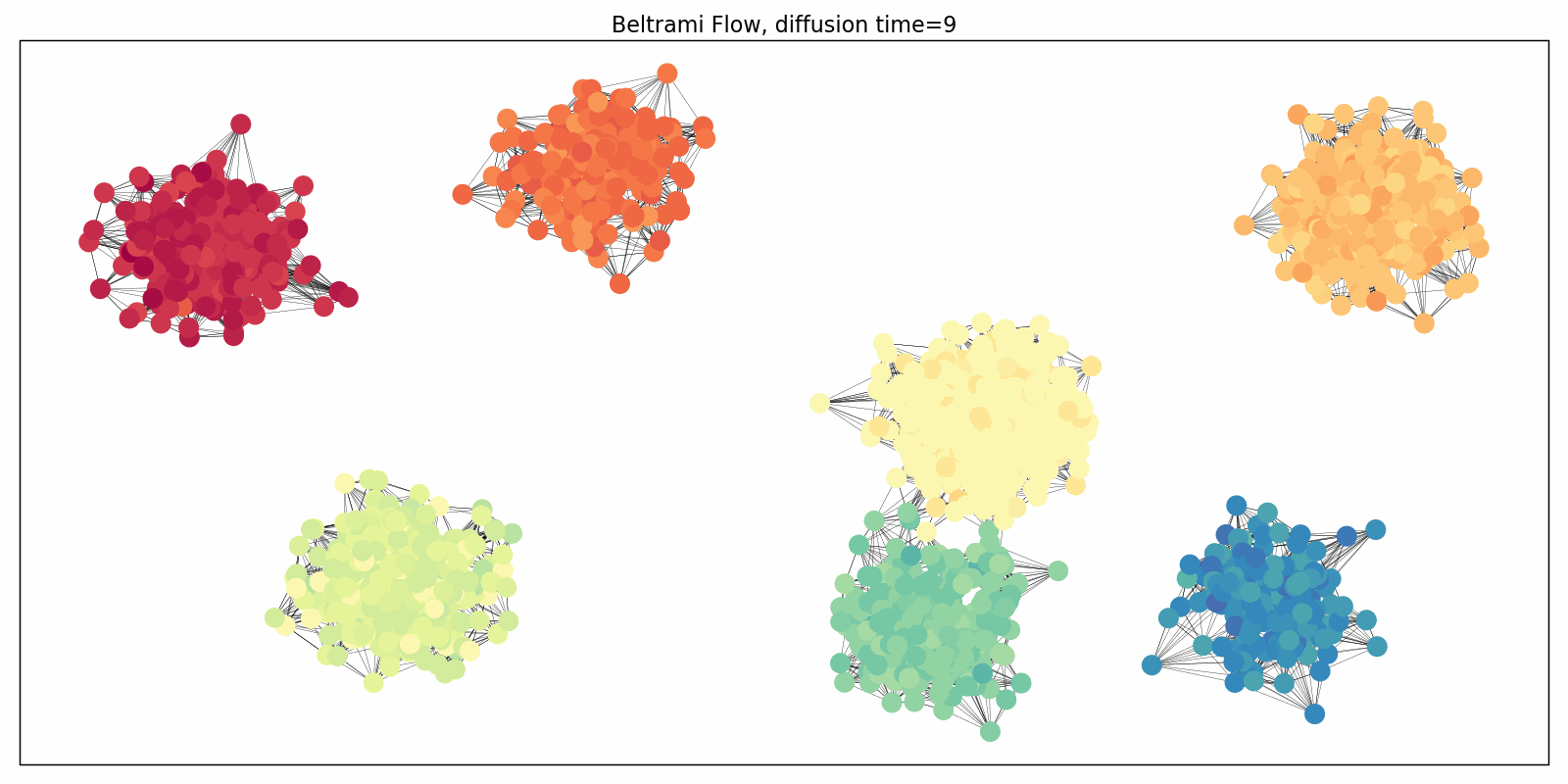
We adapted this paradigm to graphs in the “Beltrami Neural Diffusion” (BLEND) framework, presented last week at NeurIPS [13]. The nodes of the graph are now characterized by positional and feature coordinates, both of which are evolved and both of which determine the diffusivity properties. In this mindset, the graph itself passes into an auxiliary role: it can be generated from the positional coordinates (e.g. as a k-nearest neighbor graph) and rewired throughout the evolution. The following Figure illustrates this simultaneous evolution process:
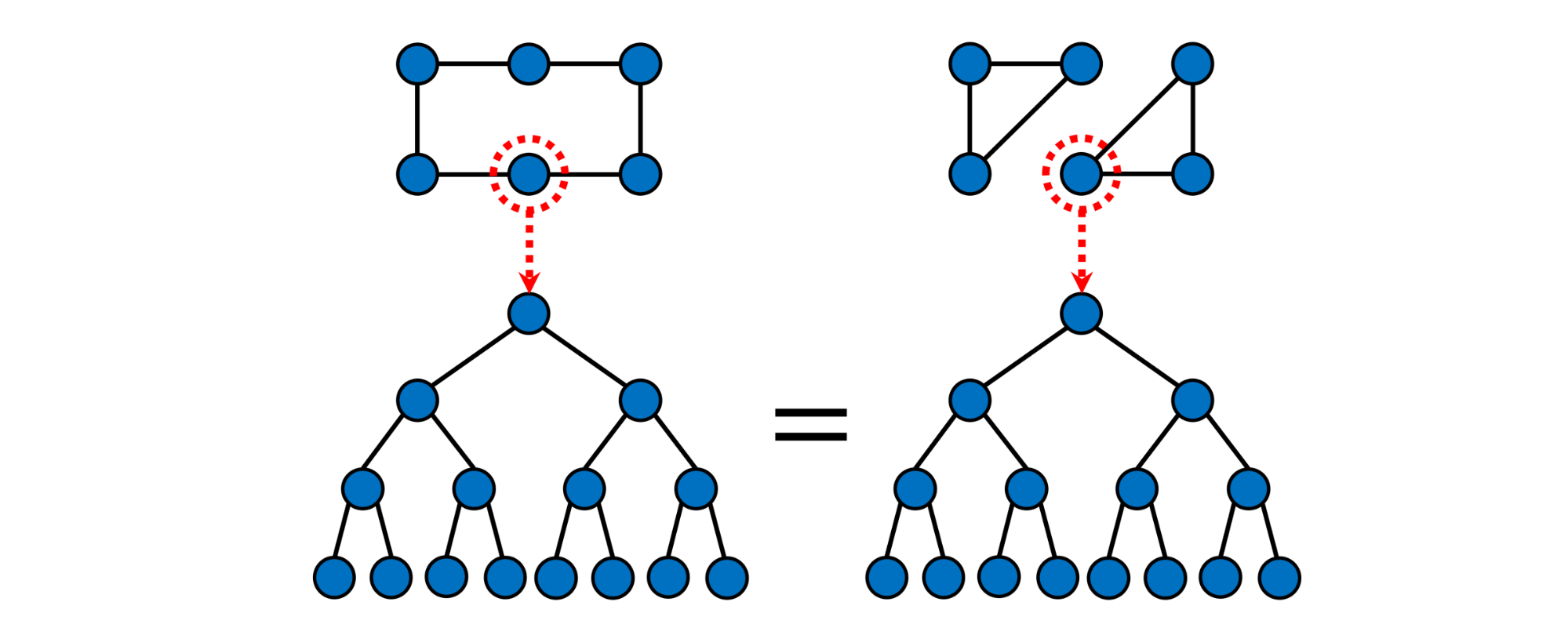
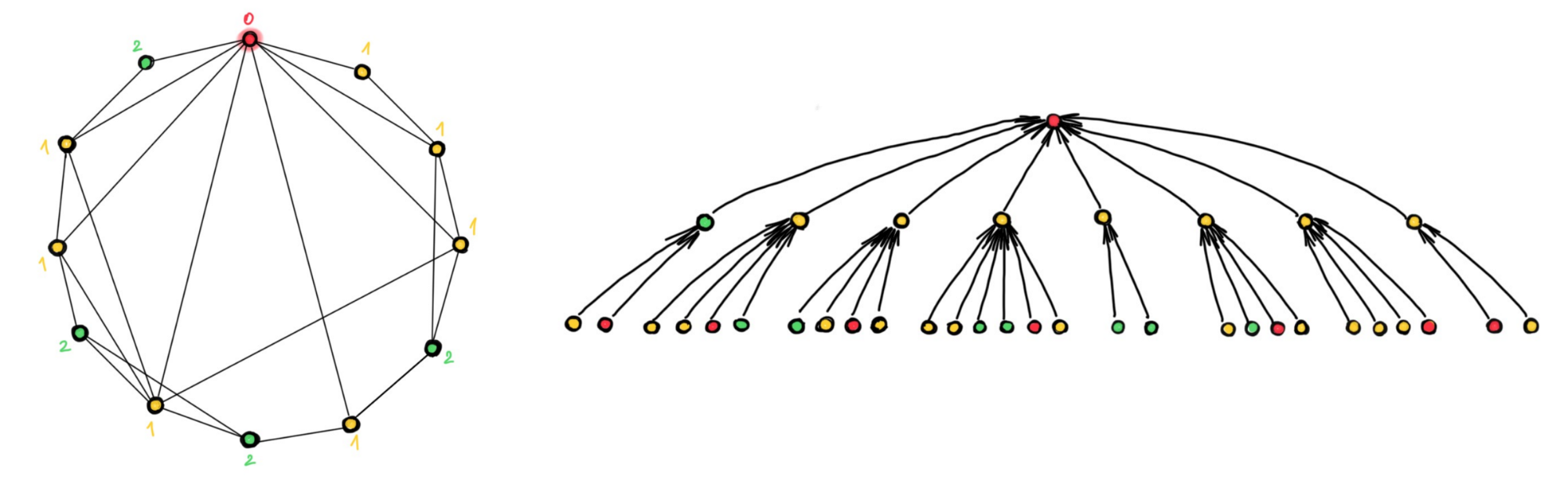
Significant attention has been devoted in recent works to the expressive power of Graph Neural Networks. Message-passing GNNs are equivalent to the Weisfeiler-Lehman graph isomorphism test [14–16], a classical method attempting to determine whether two graphs are structurally equivalent (“isomorphic”) by means of iterative color refinement. This test is a necessary but insufficient condition: in fact, some non-isomorphic graphs might be deemed equivalent by Weisfeler-Lehman. The following Figure illustrates what message passing GNNs “see”: the two highlighted nodes appear indistinguishable, though the graphs clearly have a different structure:
Positional Encoding. A common remedy to this problem is to “color” the nodes by assigning to them some additional features representing the role or “position” of the node in the graph. Popularized in Transformers [17] (which are a special case of attentional GNNs operating on a complete graph [4]), positional encoding methods have become a common way of increasing the expressive power of Graph Neural Networks.
Perhaps the most straightforward approach is to endow each node with a random feature [18]; however, while being more expressive, such an approach would provide poor generalization (since it is impossible to reproduce random features across two graphs). The eigenvectors of the graph Laplacian operator [19] provide a neighborhood-preserving embedding of the graph and have been successfully used as positional encoding. Finally, we showed in our paper with Giorgos Bouritsas and Fabrizio Frasca [20] that graph substructure counting can be used as a form of positional or “structural” encoding that can be made provably more powerful than the basic Weisfeiler-Lehman test.
However, with a variety of choices for positional encoding, there is no clear recipe as to how to choose one, and no clear answer to the question of which method works better in which cases. I believe that geometric flows such as BLEND can be interpreted in the light of this question: by evolving the positional coordinates of the graph through non-euclidean diffusion, the positional encoding is adapted for the downstream task. The answer is, therefore, “it depends”: the best positional encoding is a function of the data and task at hand.
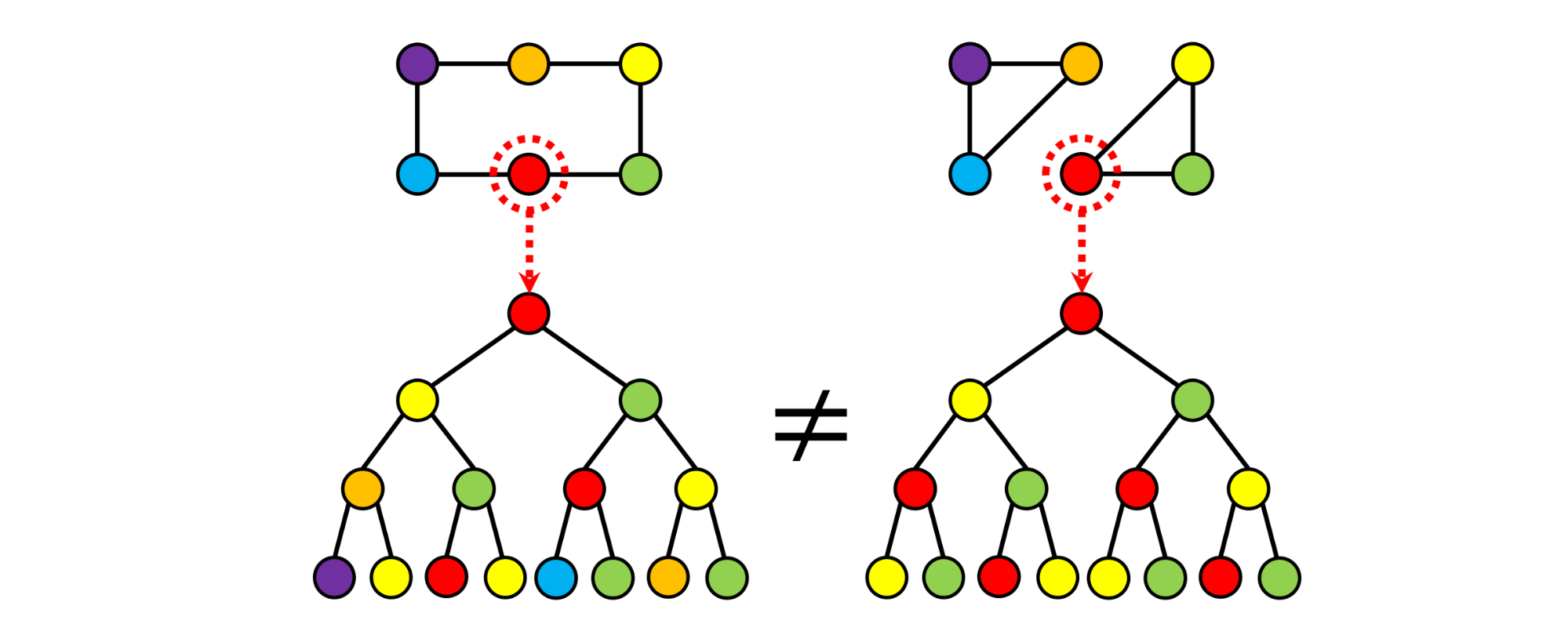
Higher-order Message Passing. An alternative take on expressivity is to stop thinking about graphs in terms of nodes and edges. Graphs are examples of objects called cell complexes, one of the main objects of study in the field of algebraic topology. In this terminology, nodes are 0-cells and edges are 1-cells. One does not have to stop there: we can construct 2-cells (faces) like shown in the following Figure, which make the two graphs from our previous example perfectly distinguishable:
In collaboration with colleagues from Cambridge, Oxford, and Max Planck Institute [21–22], we showed the possibility to construct a “lifting transformation” that augments the graph with such higher-order cells, on which one can perform a more complex form of hierarchical message passing. This scheme can be made provably more expressive than the Weisfeiler-Lehman test and has shown promising results e.g. in computational chemistry where many molecules exhibit structures better modeled as cell complexes rather than graphs.
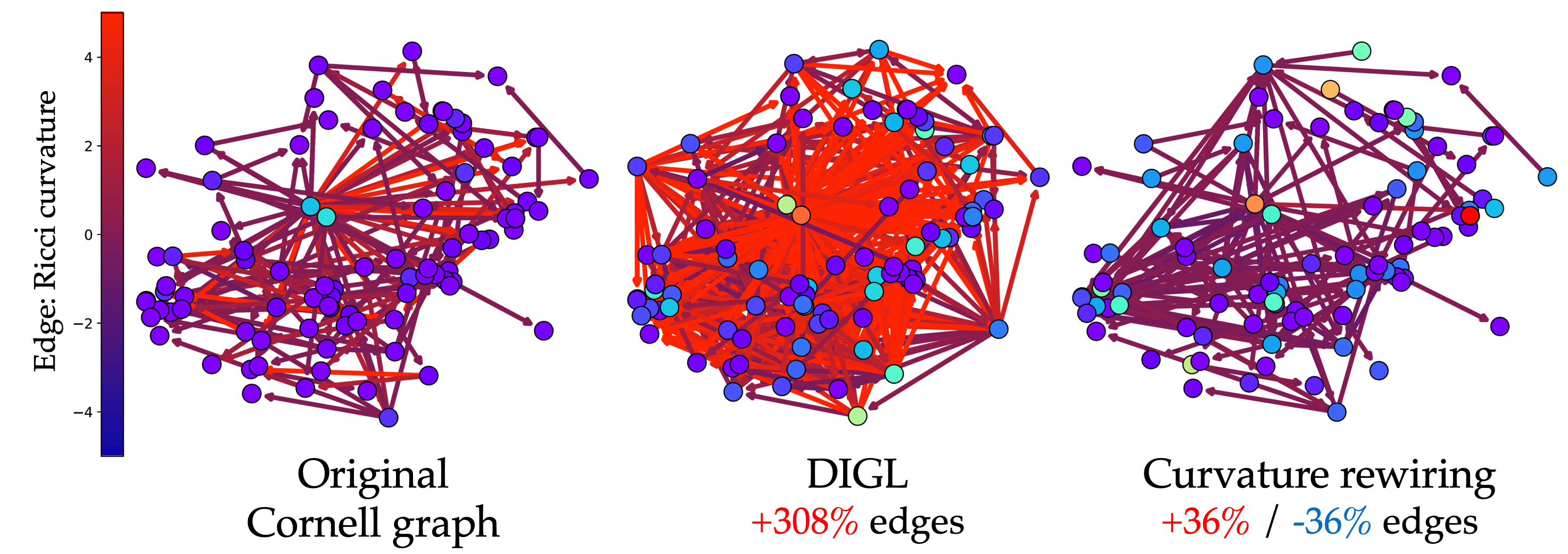
Over-squashing, Bottlenecks, and Graph Rewiring. Empirically, it was observed that decoupling the input graph from the computational graph and allowing passing messages on a different graph helps alleviate the problem; such techniques are generally referred to as “graph rewiring”.
It is fair to say that many popular GNN architectures implement some form of graph rewiring, which can take the form of neighborhood sampling (originally proposed in GraphSAGE to cope with scalability [25]) or multi-hop filters [26]. Topological message passing discussed above can also be seen as a form of rewiring, whereby information flow between distant nodes can be “shortcut” through higher-order cells. Alon and Yahav [23] showed that even as simplistic an approach as using a fully connected graph may help improve over-squashing in graph ML problems. Klicpera and coauthors enthusiastically proclaimed that “diffusion improves graph learning”, proposing a universal preprocessing step for GNNs (named “DIGL”) consisting in denoising the connectivity of the graph by means of a diffusion process [27]. Overall, despite the significant empirical study, the over-squashing phenomenon has been elusive and insufficiently understood.
In a recent collaboration with Oxford [28], we show that bottlenecks resulting in over-squashing can be attributed to the local geometric properties of the graph. Specifically, by defining a graph analogy of Ricci curvature, we can show that negatively-curved edges are the culprits. This interpretation leads to a graph rewiring procedure akin to “backward Ricci flow” that surgically removes problematic edges and produces a graph that is more message passing-friendly while being structurally similar to the input one.
These examples show that differential geometry and algebraic topology bring a new perspective to important and challenging problems in graph machine learning.
[1] H. Weyl, Symmetry (1952), Princeton University Press.
[2]F. Klein, Vergleichende Betrachtungen über neuere geometrische Forschungen (1872).
[3] J. Schwichtenberg, Physics from symmetry (2018), Springer.
[4] M. M. Bronstein, J. Bruna, T. Cohen, and P. Veličković, Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges (2021); see an accompanying post and the project website.
[5] In the above GDL proto-book, we call these the “5G” of Geometric Deep Learning.
[6] Geometric graphs naturally arise as discrete models of objects living in a continuous space. A prominent example is molecules, modeled as graphs where every node represents an atom with 3D spatial coordinates. On the other hand, it is possible to embed general graphs into a continuous space, thus (approximately) realising their connectivity using the metric structure of some space.
[7] B. Chamberlain, J. Rowbottom et al., GRAND: Graph Neural Diffusion (2021) ICML.
[8] P. Veličković et al., Graph Attention Networks (2018) ICLR.
[9] A gradient flow can be seen as a continuous analogy of gradient descent in variational problems. It arises from the optimality conditions (known in the calculus of variations as Euler-Lagrange equations) of a functional.
[10] Geometric flows are gradient flows of functionals defined on manifolds. Perhaps the most famous of them is the Ricci flow, used by Grigori Perelman in the proof of the century-old Poincaré conjecture. Ricci flow evolves the Riemannian metric of the manifold and is structurally similar to the diffusion equation (hence often, with gross simplification, presented as “diffusion of the metric”).
[11] N. Sochen et al., A general framework for low-level vision (1998) IEEE Trans. Image Processing 7(3):310–318 used a geometric flow minimising the embedding energy of a manifold as a model for image denoising. The resulting PDE is a linear non-euclidean diffusion equation ẋ = Δx (here Δ is the Laplace-Beltrami operator of the image represented as an embedded manifold), as opposed to the nonlinear diffusion ẋ = div(a(x)∇x) used earlier by P. Perona and J. Malik, Scale-space and edge detection using anisotropic diffusion (1990) PAMI 12(7):629–639.
[12] Beltrami flow minimizes a functional known in string theory as the Polyakov action. In the Euclidean case, it reduces to the classical Dirichlet energy.
[13] B. P. Chamberlain et al., Beltrami Flow and Neural Diffusion on Graphs (2021) NeurIPS.
[14] B. Weisfeiler, A. Lehman, The reduction of a graph to canonical form and the algebra which appears therein (1968) Nauchno-Technicheskaya Informatsia 2(9):12–16.
[15] K. Xu et al., How powerful are graph neural networks? (2019) ICLR.
[16] C. Morris et al., Weisfeiler and Leman go neural: Higher-order graph neural networks (2019) AAAI.
[17] A. Vaswani et al., Attention is all you need (2017) NIPS.
[18] R. Sato, A survey on the expressive power of graph neural networks (2020). arXiv: 2003.04078. Uses random features for positional encoding.
[19] V. P. Dwivedi et al. Benchmarking graph neural networks (2020). arXiv: 2003.00982. Uses Laplacian eigenvectors as positional encoding, though the idea of spectral graph embedding is way older and has been widely used in nonlinear dimensionality reduction such as the classical work of M. Belkin and P. Niyogi, Laplacian eigenmaps and spectral techniques for embedding and clustering (2001), NIPS.
[20] G. Bouritsas et al., Improving graph neural network expressivity via subgraph isomorphism counting (2020). arXiv:2006.09252. Uses graph substructure counts as positional encoding; see an accompanying post.
[21] C. Bodnar, F. Frasca, et al., Weisfeiler and Lehman go topological: Message Passing Simplicial Networks (2021) ICML.
[22] C. Bodnar, F. Frasca, et al., Weisfeiler and Lehman go cellular: CW Networks (2021) NeurIPS.
[23] U. Alon and E. Yahav, On the bottleneck of graph neural networks and its practical implications (2020). arXiv:2006.05205
[24] In such graphs, the size of neighbors up to k-hops away grows very fast with k, resulting in “too many neighbors” that have to send their updates to a node.
[25] W. Hamilton et al., Inductive representation learning on large graphs (2017) NIPS.
[26] Frasca et al., SIGN: Scalable Inception Graph Neural Networks (2020). ICML workshop on Graph Representation Learning and Beyond. Uses multihop filters; see an accompanying post.
[27] J. Klicpera et al., Diffusion improves graph learning (2019) NeurIPS. Rewires the graph by computing Personalized Page Rank (PPR) node embedding and then computing a k-NN graph in the embedding space.
[28] J. Topping, F. Di Giovanni et al., Understanding over-squashing and bottlenecks on graphs via curvature (2021) arXiv:2111.14522.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.