Insights
Harnessing second order optimizers from deep learning frameworks
By
Monday, 5 April 2021
Introducing the dict-minimize package
GitHub | Read the Docs | PyPI
Have you ever wanted to use a second order optimizer on code written in TensorFlow or PyTorch? What about optimizing a dictionary of tensors using SciPy minimize? If so, a lot of troublesome glue code was probably needed. For another way, look no further than the dict-minimize package, which takes care of everything and lets users easily optimize objectives implemented in TensorFlow, PyTorch, or JAX.
Modern deep learning frameworks, and their built-in optimization tools, are designed around the assumption that the user wants to do optimization using stochastic gradient descent (SGD) or its variants, for example ADAM. Many deep learning practitioners may not even be aware of the large literature in the optimization community of more general methods that were dominant before the rise of deep learning.
In particular, methods like L-BFGS and conjugate gradient (CG) were the go-to methods in the pre-deep learning era (some might remember using minimize.m). So what changed? In deep learning, we work with huge data sets. Therefore, getting the exact gradients for training the network requires an entire epoch of data, which is computationally infeasible. So, we switched to doing data subsampling to get stochastic (unbiased) estimates of the training loss gradients and used SGD. The miracle of deep learning is that for training the weights of deep neural networks using stochastic gradients actually works better than batch optimization. This is because of implicit regularization among other reasons.
However, we must remember that optimization is bigger than just training the weights of a deep neural network. For many problems, where exact gradients are cheaply available, traditional optimization methods like L-BFGS work better. They also work well with default hyper-parameters. By contrast, in most applications of SGD, some tuning of hyper-parameters must be done to obtain good performance. When applicable, it is very useful to have methods like L-BFGS as an option for optimization.
Traditional exact-gradient optimization methods have been available in scipy-minimize for years. However, these SciPy optimization routines are inconvenient for modern users for two main reasons. First, the SciPy API for these routines assumes the user has coded up an objective function in NumPy and manually coded its gradients. Modern users implement their objectives in frameworks such as TensorFlow, PyTorch, or JAX so they can get their gradients using automatic differentiation, which our package allows for. Second, the SciPy API assumes the user wants to optimize a 1-D NumPy vector. Modern users want to optimize a collection of several tensor parameters simultaneously. This is why we implemented our package, dict-minimize, as a dictionary of tensors.
At Twitter, we have used dict-minimize to train the parameters of out-of-sample classification calibrators, which have smaller training sets. Since deep networks are known to give poorly calibrated probabilities in prediction, a small amount of hold-out data, for example 1%, can be used to train a beta calibration phase. In this case, exact gradients are cheap since the data set size used to train the calibrator is much smaller. The smaller calibration network also makes the back-propagation faster. In this case, we can be more confident in the convergence, without hyper-parameter tuning, than we would be SGD.
We support TensorFlow, PyTorch, JAX, and NumPy interchangeably in the dict-minimize package. Regardless of your preference in a deep learning framework, you can use dict-minimize for optimization. We also support NumPy since users that want to optimize dictionaries of NumPy arrays also cannot simply use SciPy directly.
In this example, we show how to optimize a Rosenbrock function from a PyTorch implementation. For demonstration purposes, the values are split across two parameters.
import torch
from dict_minimize.torch_api import minimize
def rosen_obj(params, shift):
"""Based on augmented Rosenbrock from botorch."""
X, Y = params["x_half_a"], params["x_half_b"]
X = X - shift
Y = Y - shift
obj = 100 * (X[1] - X[0] ** 2) ** 2 + 100 * (Y[1] - Y[0] ** 2) ** 2
return obj
def d_rosen_obj(params, shift):
obj = rosen_obj(params, shift=shift)
da, db = torch.autograd.grad(obj, [params["x_half_a"], params["x_half_b"]])
d_obj = OrderedDict([("x_half_a", da), ("x_half_b", db)])
return obj, d_obj
torch.manual_seed(123)
n_a = 2
n_b = 2
shift = -1.0
params = OrderedDict([("x_half_a", torch.randn((n_a,))), ("x_half_b", torch.randn((n_b,)))])
params = minimize(d_rosen_obj, params, args=(shift,), method="L-BFGS-B", options={"disp": True})In the above code block, we simply imported:
from dict_minimize.torch_api import minimizeinstead of:
from scipy.optimize import minimizeThe interface is essentially the same as the original scipy-minimize. However, here we use a dictionary of tensors instead of a simple NumPy vector. Likewise, the objective function routines are dictionaries of gradient tensors instead of a simple NumPy vector. This is a more natural framework for most modern real-world problems, where there are many different parameters that need to be optimized simultaneously.
Even within deep learning there are many examples of optimization where the exact gradient does not require evaluating a loss on a massive training set. These are the cases where dict-minimize can be used. Perhaps the most well known example is adversarial examples. In adversarial examples, the gradient is the output of a deep network trained on a single training example. In these cases, practitioners apply SGD out of habit rather than strict necessity.
In this blog post, we look at another example where exact gradients are possible: deep dream. The idea behind deep dream is to visualize the inputs to a deep neural network for vision, for example InceptionV3, that maximizes the response of a neuron of an internal layer in the neural network. It can be used as a tool for interpretability or even just for art. The work on deep dream shows how the first layers of a neural network have responses that are maximized by low level concepts like textures; while deep layers have responses maximized by higher level concepts such as objects that look like dogs.
Deep dream became so popular that it is a standard TensorFlow demo. Being implemented in TensorFlow, the authors simply used SGD (possibly due to the lack of alternatives to try). Here, we show how L-BFGS, without any hyper-parameter tuning, can be used to obtain faster convergence than the SGD from the demo.
Here, we optimize an image using L-BFGS. We replace the main loop of the SGD optimization from the original demo with:
from dict_minimize.tensorflow_api import minimize
lb = OrderedDict({"img": -tf.ones_like(img)})
ub = OrderedDict({"img": tf.ones_like(img)})
params0 = OrderedDict({"img": img})
params = minimize(
deepdream.obj_and_grad_dict,
params0,
lb_dict=lb,
ub_dict=ub,
method="L-BFGS-B",
options={"disp": True, "maxfun": 100},
)Note that we can more naturally express constraints, such as the image being bounded between white and black, using the bounds arguments. In SGD, one must periodically clip the tensor to ensure it stays within the bounds.
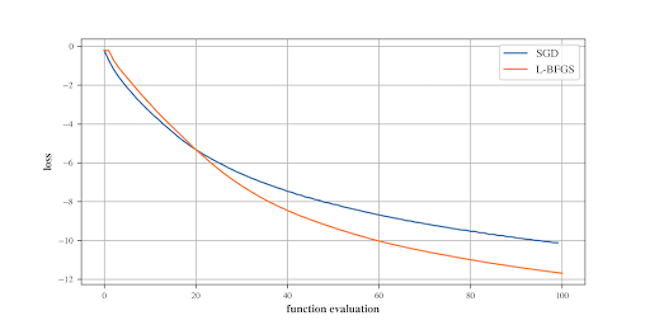
In this example, we optimized neuron 1 of the layer “mixed5” in InceptionV3, which was trained on the ImageNet dataset. This neuron responds to textures similar to crocodile leather.
Below we see that the default L-BFGS outperformed the SGD from the tuned demo in terms of convergence as a function of gradient evaluations:
The below video demonstrates the faster convergence of L-BFGS. Here, standard SGD (left) and L-BFGS (right) race to stylize a Labrador Retriever into crocodile leather using deep dream:
"SGD" on the left; "L-BFGS" on the right
The effect “kicks in” much faster on the right with L-BFGS.
The dict-minimize package offers convenient options to interface with modern deep learning frameworks where automatic differentiation is available. The options for fancier extensions are numerous. For example, in smaller search spaces, when combined with the Hessian capable JAX, full second-order methods like Newton optimization are also possible. The dict-minimize package provides a simple and convenient interface. Users should consider it when they have a new optimization problem where exact gradients are tractably available.
Get started with: pip install dict_minimize
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.