Insights
Provably expressive graph neural networks
By
and
Tuesday, 1 June 2021
In previous posts, we have discussed graph neural networks that can handle temporal graphs or that can scale to graphs with a large number of nodes and edges. In this post, we describe how to design local and computationally efficient provably powerful graph neural networks that are not based on the Weisfeiler-Lehman tests hierarchy. Different from standard architectures, these networks can easily be biased to capture structural information specific to the application domain. In social networks, triangles and cliques may reveal the presence of strong(er) social ties or “tightly knit” communities. Accessing this kind of information can improve predictions at the level of single users or groups of users.
Background
Recent papers¹𝄒² established the connection between graph neural networks and the graph isomorphism tests. In particular, the papers draw a parallel between the message passing mechanism and the color refinement steps of the Weisfeiler-Lehman (WL) test³. The WL test is a general name for a hierarchy of polynomial-time algorithms for determining graph isomorphism. The k-WL test iteratively recolors k-tuples of vertices of a graph at each step according to some neighborhood aggregation rules and stops upon reaching a stable coloring. If the histograms of colors for two graphs are not the same, the graphs are deemed non-isomorphic. If the histograms are the same, the graphs are possibly (but not necessarily) isomorphic.
Message passing neural networks have been shown to be at most as powerful as the 1-WL test¹, which only refines colors locally and at the level of single nodes. They therefore inherit the intrinsic limitations of this algorithm, for example, they are unable to count simple substructures such as triangles⁴. Triangles play an important role in social networks because they are associated with the clustering coefficient. This coefficient is indicative of how “tightly knit” users are⁵. It is possible to design more expressive graph neural networks that replicate the increasingly more powerful k-WL tests²𝄒⁶. However, such architectures result in high complexity, a large number of parameters, and, most importantly, typically require non-local operations that make them impractical⁷.
Thus, provably expressive graph neural networks based on the WL hierarchy are either not very powerful but practical, or powerful but impractical. We argue that there is a different and simple way to design efficient and provably powerful graph neural networks, which we proposed in a new paper with Giorgos Bouritsas⁸.
The idea behind our proposed architecture is conceptually similar to that of positional encoding. The architecture employs a message passing mechanism which is aware of the local graph structure, allowing the computation of messages in a way that depends on the topological relationship between the endpoint nodes. This is done by passing additional structural descriptors, which are associated with each node, to message passing functions⁹. These descriptors are constructed by subgraph isomorphism counting. In this way, we can partition the nodes of the graph into different equivalence classes that reflect topological characteristics that are shared both between nodes in each graph individually and across different graphs.
We call this architecture Graph Substructure Network (GSN). It has the same algorithmic design, memory, and computational complexity as standard message passing neural networks, with an additional, initial precomputation step in which the structural descriptors are constructed by counting substructures. The choice of which substructures to count is crucial both to the expressive power of GSNs and the computational complexity of the precomputation step.
The worst-case complexity of counting substructures of size k in a graph with n nodes is 𝒪(nᵏ). Thus, it is similar to high-order graph neural network models described by Morris² and Maron⁶. However, GSNs have several advantages over these methods. First, for some types of substructures, such as paths and cycles, the counting can be done with significantly lower complexity. Secondly, the computationally expensive step is done only once as preprocessing. Thus, this step does not affect network training and inference, which both remain linear, the same way as in message passing neural networks. The memory complexity in training and inference is linear as well. Thirdly, and most importantly, the expressive power of GSNs is different from k-WL tests and in some cases is stronger.
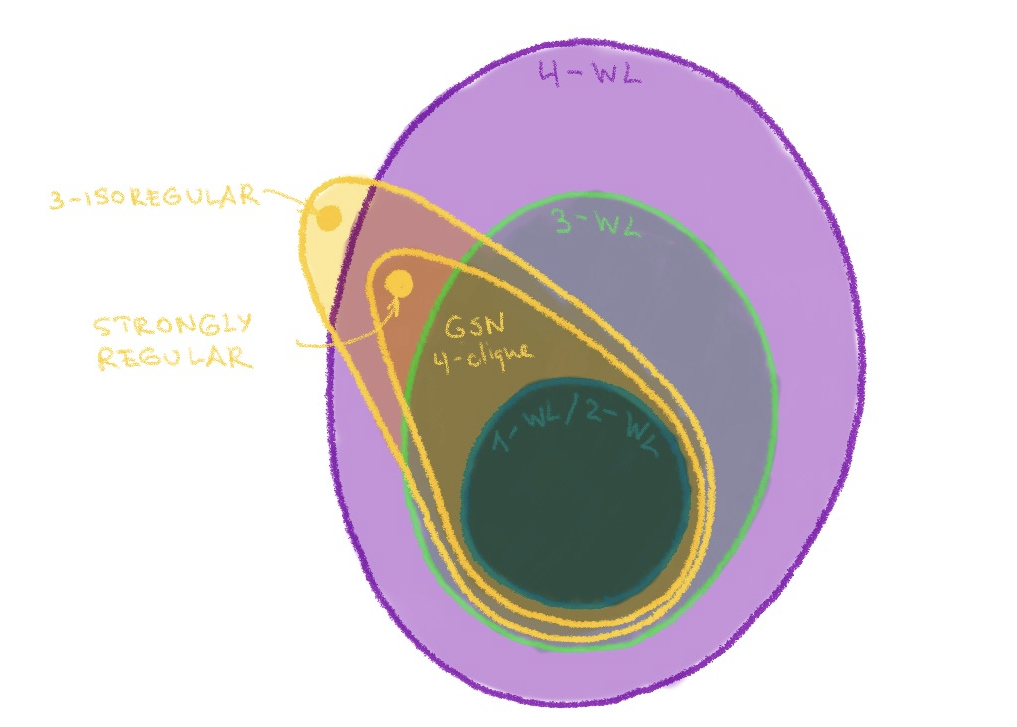
The substructure counting provides GSNs with more expressive power than standard message passing neural networks. However, the expressive power of GSNs depends on the graph substructures that are used. Similar to the hierarchy of k-WL tests, we might have different variants of GSNs based on the number and class of structures we are counting. By using structures more complex than star graphs, GSNs can be made strictly more powerful than 1-WL tests or the equivalent 2-WL test. Thus, GSNs are also more powerful than standard message passing architectures. With 4-cliques, GSNs are at least no less powerful than the 3-WL test. The following example shows GSN succeeding on a pair of strongly regular graphs where the 3-WL test fails:
The image above represents an example of strongly regular graphs in family SR(16,6,2,2): they have 16 vertices, node degree 6, every two adjacent vertices have 2 mutual neighbors, and every two non-adjacent vertices also have 2 mutual neighbors. The graph on the right has maximum cliques of size 3 (triangles, yellow), while in the one on the left each node participates in exactly one 4-clique (red).
The 3-WL test fails to distinguish between the above pair of strongly regular graphs, while GSN with 4-clique substructures can. In the graph on the left, known as the Rook’s graph, each node participates in exactly one 4-clique. The graph on the right, the Shrikhande graph, has maximum cliques of size 3 (triangles)⁷.
More generally speaking, for various substructures of 𝒪(1) size, as long as they cannot be counted by 3-WL, there exist graphs where GSN succeeds and 3-WL fails¹⁰. While we could not find examples to the contrary, they might in principle exist. This holds for larger k as well; k-isoregular graphs, a generalization of the strongly regular graphs in the above example, are examples where the (k+1)-WL test fails¹¹. These graphs can also be distinguished by GSN with appropriate structures. The expressive power of GSNs can thus be captured by the following figure:
How powerful can GSN be in principle? This is still an open question. The Graph Reconstruction Conjecture¹² states the possibility of recovering a graph from all its node-deleted substructures. Thus, if the Reconstruction Conjecture is correct, a GSN with substructures of size n-1 would be able to correctly test the isomorphism of any graphs. However, the Reconstruction Conjecture is currently proven only for graphs of size¹³ n ≤ 11 and such large structures would be impractical to use.
The more interesting question is whether a similar result exists for “small” structures. That is structures of 𝒪(1) size, independent of the number of nodes n. Our empirical results show that GSN with small substructures, such as cycles, paths, and cliques, works for strongly regular graphs, which are known to be a “tough nut” for WL tests.
As previously mentioned, the choice of the structures counted for the construction of the structural descriptors is crucial. It is likely that practical applications of GSNs will be guided by the tradeoff between the required expressive power, the size of the structures that can guarantee it, and the complexity of computing them. In our experiments, we observed that different problems and datasets benefit from different substructures, so it is likely that this choice is problem-specific. Fortunately, we often know what substructures matter in some applications. For example, in social networks, triangles and higher-order cliques are common and have a clear “sociological” interpretation. In chemistry, cycles are a very frequent pattern, such as 5- and 6-membered aromatic rings that appear in a plethora of organic molecules.
In Figure 4, we experimentally show how these domain-relevant substructures allowed GSN to generalize particularly well on the ZINC dataset¹⁴ compared to trees and paths. Although trees and paths allow better fitting of the training set, they do not perform as well on the hold-out test set. The ZINC database is used by pharmaceutical companies for virtual screening of drug candidates. Such cyclic structures are abundant in organic molecules and allow better generalization than other substructures such as paths and trees.
GSNs are simple models which overcome the limitations of standard message passing schemes by including structural encodings. GSNs are provably more expressive than standard graph neural networks and they allow you to easily include domain knowledge by choosing the substructures to count. Most importantly, GSNs retain locality and linear complexity, contrary to other provably expressive approaches which require impractical non-local operations. In the future it would be interesting to explore the ability of GSNs to compose substructures and to investigate approaches to infer prominent substructures directly from the data. For now, we invite the reader to take a deeper look at our paper.
¹ K. Xu et al. How powerful are graph neural networks? (2019). Proc. ICLR.
² C. Morris et al. Weisfeiler and Leman go neural: Higher-order graph neural networks (2019). Proc. AAAI.
³ B. Weisfeiler, A. Lehman, The reduction of a graph to canonical form and the algebra which appears therein, 1968 (English translation)
⁴ Consequently, two graphs with a different number of triangles would be considered possibly isomorphic by the 1-WL test, or equivalently, will have an identical embedding constructed by a message passing neural network.
⁵ R. Milo et al. Network motifs: simple building blocks of complex networks (2002). Science 298 (5594):824–827.
⁶ H. Maron et al. Provably powerful graph neural networks (2019). Proc. NeurIPS.
⁷ The 3-WL-equivalent graph neural network architecture of Morris has 𝒪(n³) space- and 𝒪(n⁴) time complexity. The architecture of Maron has a slightly better 𝒪(n²) space- and 𝒪(n³) time complexity. For a modestly-sized graph with 1 million nodes this still translates into enormous 1 TB of memory and an exaflop of computation.
⁸ G. Bouritsas et al. Improving graph neural network expressivity via subgraph isomorphism counting (2020). arXiv:2006.09252.
⁹ We show the same mechanism for edges as well.
¹⁰ 3-WL appears to be rather weak in terms of substructure counting. For example, it can count motif cycles of up to 7 nodes, but fails to count induced 4-cycles or paths of length 4. It is currently not clear what substructure counting capabilities are obtained by going up in the WL-hierarchy.
¹¹ B. L. Douglas, The Weisfeiler-Lehman method and graph isomorphism testing (2011). arXiv:1101.5211. Note that there is some level of confusion between what different references call “k-WL”. Douglas uses the term k-WL for what others call (k-1)-FWL (“folklore” WL). In our terminology, k-WL fails on (k-1)-isoregular graphs. Strongly regular graphs are 2-isoregular.
¹² P.J. Kelly, A congruence theorem for trees (1957). Pacific J. Math. 7:961–968.
¹³ B. D. McKay, Small graphs are reconstructible (1997). Australasian J. Combinatorics 15:123–126.
¹⁴ J. J. Irwin et al. ZINC: A free tool to discover chemistry for biology (2012). Journal of chemical information and modeling, 52 (7):1757–1768.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.