Insights
Sharing learnings about our image cropping algorithm
By
Wednesday, 19 May 2021
In October 2020, we heard feedback from people on Twitter that our image cropping algorithm didn’t serve all people equitably. As part of our commitment to address this issue, we also shared that we'd analyze our model again for bias. Over the last several months, our teams have accelerated improvements for how we assess algorithms for potential bias and improve our understanding of whether ML is always the best solution to the problem at hand. Today, we’re sharing the outcomes of our bias assessment and a link for those interested in reading and reproducing our analysis in more technical detail.
The analysis of our image cropping algorithm was a collaborative effort together with Kyra Yee and Tao Tantipongpipat from our ML Ethics, Transparency, and Accountability (META) team and Shubhanshu Mishra from our Content Understanding Research team, which specializes in improving our ML models for various types of content in tweets. In our research, we tested our model for gender and race-based biases and considered whether our model aligned with our goal of enabling people to make their own choices on our platform.
How does a saliency algorithm work and where might harms arise?
Twitter started using a saliency algorithm in 2018 to crop images. We did this to improve consistency in the size of photos in your timeline and to allow you to see more Tweets at a glance. The saliency algorithm works by estimating what a person might want to see first within a picture so that our system could determine how to crop an image to an easily-viewable size. Saliency models are trained on how the human eye looks at a picture as a method of prioritizing what's likely to be most important to the most people. The algorithm, trained on human eye-tracking data, predicts a saliency score on all regions in the image and chooses the point with the highest score as the center of the crop.
In our most recent analysis of this model, we considered three places where harms could arise:
How did we test it and what did we find?
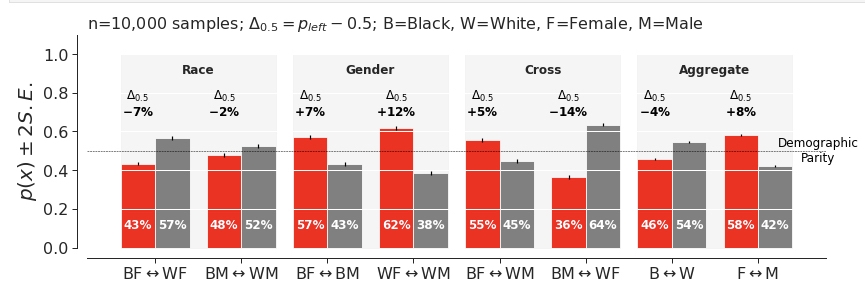
To quantitatively test the potential gender and race-based biases of this saliency algorithm, we created an experiment of randomly linked images of individuals of different races and genders. (Note: In our paper, we share more details around the tradeoffs between using identity terms and skin tone annotations in our analysis.) If the model is demographically equal, we'd see no difference in how many times each image was chosen by the saliency algorithm. In other words, demographic parity means each image has a 50% chance of being salient.
Here’s what we found:
We also tested for the “male gaze” by randomly selecting 100 male- and female-presenting images that had more than one area in the image identified by the algorithm as salient and observing how our model chose to crop the image. We didn't find evidence of objectification bias — in other words, our algorithm did not crop images of men or women on areas other than their faces at a significant rate. Here’s what we found:
We qualitatively considered the saliency algorithm within the fairness in ML literature, including those on technological harms to society. Even if the saliency algorithm were adjusted to reflect perfect equality across race and gender subgroups, we’re concerned by the representational harm of the automated algorithm when people aren't allowed to represent themselves as they wish on the platform. Saliency also holds other potential harms beyond the scope of this analysis, including insensitivities to cultural nuances.
What actions are we taking?
We considered the tradeoffs between the speed and consistency of automated cropping with the potential risks we saw in this research. One of our conclusions is that not everything on Twitter is a good candidate for an algorithm, and in this case, how to crop an image is a decision best made by people.
In March, we began testing a new way to display standard aspect ratio photos in full on iOS and Android — meaning without the saliency algorithm crop. The goal of this was to give people more control over how their images appear while also improving the experience of people seeing the images in their timeline. After getting positive feedback on this experience, we launched this feature to everyone. This update also includes a true preview of the image in the Tweet composer field, so Tweet authors know how their Tweets will look before they publish. This release reduces our dependency on ML for a function that we agree is best performed by people using our products. We’re working on further improvements to media on Twitter that builds on this initial effort, and we hope to roll it out to everyone soon.
Public accountability
We want to thank you for sharing your open feedback and criticism of this algorithm with us. As we discussed in our recent blog post about our Responsible ML initiatives, Twitter is committed to providing more transparency around the ways we’re investigating and investing in understanding the potential harms that result from the use of algorithmic decision systems like ML. You can look forward to more updates and published work like this in the future.
How can you be involved?
We know there's a lot of work to do and we appreciate your feedback in helping us identify how we can improve. Tweet us using the hashtag #AskTwitterMETA. You can also access our code and our full academic paper is available on arXiv here.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.