Insights
A hybrid approach to personalize notification volume
By
and
Tuesday, 18 January 2022
It’s important that people can easily find and connect with the content and conversations they’re interested in when they come to Twitter. One of the ways we do that is by personalizing push notifications of recommended content to those who have opted in. In this blog, we’ll share how we use machine learning techniques to ensure people see the right amount of relevant and timely notifications.
The first step in using machine learning to personalize the number of notifications at the customer level is to choose which types of customer feedback we want to take into account. Two important actions taken by customers that are considered “positive” are logging on to the platform and choosing to receive notifications. Thus, to measure the effectiveness of our notifications system, two highly important metrics are daily active users (DAU) and reachability. Reachability measures how many people choose to receive notifications from Twitter.
Increasing the number of notifications may increase DAU in the short term, as we have more opportunities to engage customers in the content from Twitter. However, some customers prefer limited or fewer notifications and might choose to express that by opting out of notifications. This reduces reachability by limiting the number of people we can connect with through notifications. Previously, we set the number of maximum daily push notifications, a.k.a the push-cap, to be the same for all customers by trying to find a global balance between DAU and reachability, at a global scale. The time spacing between two subsequent notifications was also set this way. However, after testing, learning, and talking it over, we realized that the right push-cap is not the same for each customer, and so we decided to personalize our approach to notifications using machine learning.
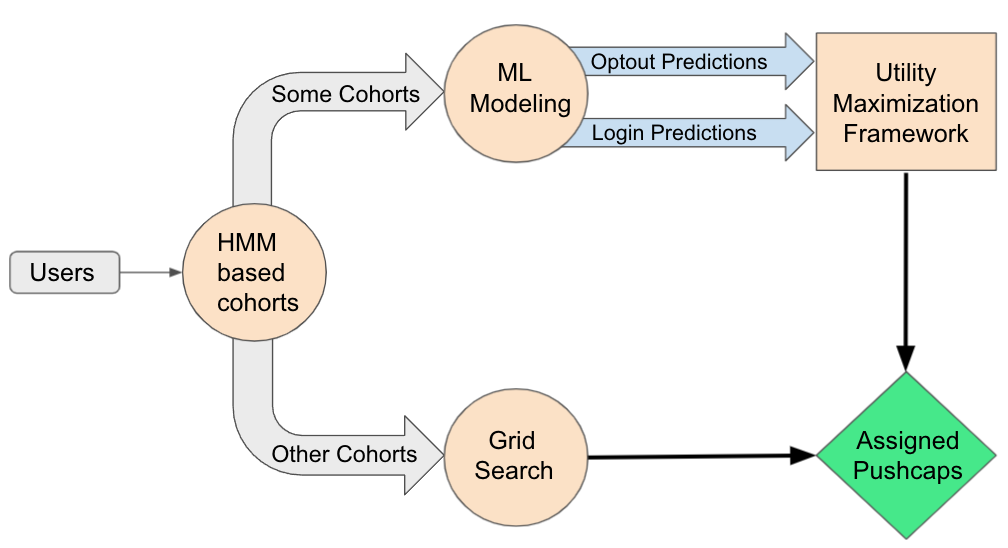
One way of personalizing push-caps is to group customers into cohorts (customer groups with similar properties) based on their behavior then learn and find the best push-cap for each cohort through experimentation. We created customer cohorts derived from a hidden Markov model (HMM) that considered customer login and notification open behavior and found that the grid search approach worked well for certain cohorts.
Customer cohorts provide a lightweight, straightforward way of personalizing push-caps for some customers. However, to further improve the customer experience, we model customer login and reachability behavior in a multilayer perceptron model (MLP). We use these MLPs as input to a utility maximization framework to find a personalized push-cap for a given customer. This approach improves upon the grid searched push-caps for some cohorts. However, for other customer cohorts, especially those with customers who rarely interact with the product, and hence have sparse signals, the lightweight grid search approach performs best. In production, a hybrid approach is used, combining the push-cap from the two models.
The push-cap is closely related to the logic controlling the interval between recent pushes. We refer to these intervals as fatigue. For the multilayer perceptron model (MLP), we personalize the fatigue jointly with the push-cap in our model and, in the hidden Markov model (HMM), the fatigue is simply set to 24 divided by push-cap.
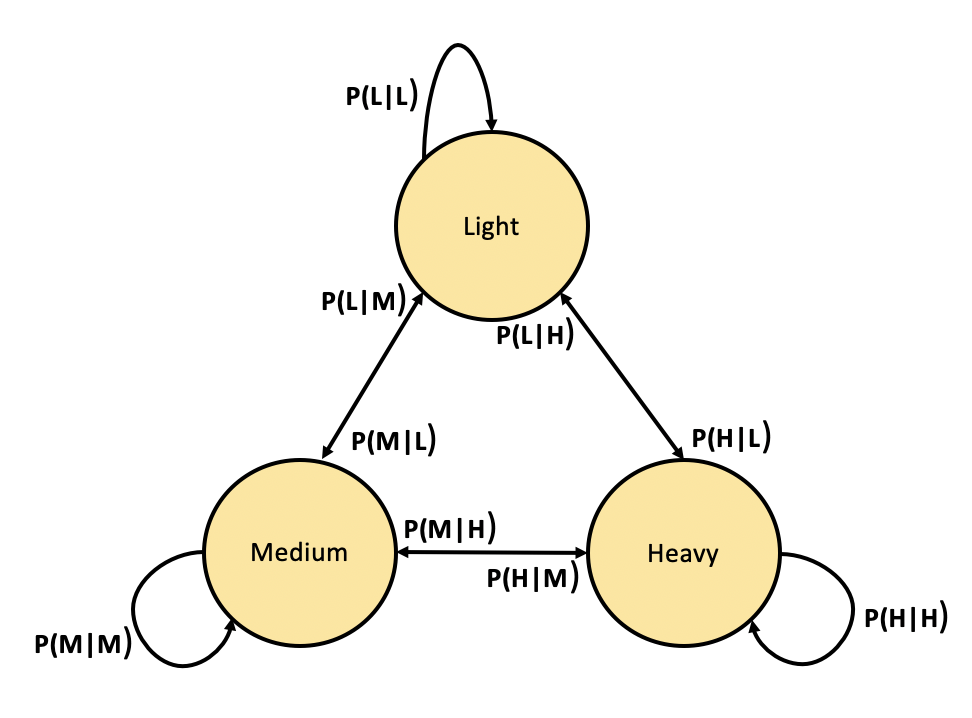
A cohort is a group of similar customers based on shared customer behaviors. Using cohorts makes it easier to learn optimal push-caps at the aggregate level than at the customer level since we have more data to learn from. We used a hidden Markov model to derive latent states of our customers (cohorts), which provided useful information about their behavior on push notifications. We trained the HMM model on long sequences of customers’ daily login and push open behaviour using the following three actions:
Doesn’t login: A customer does not login to the app on a particular day.
Logs in but doesn’t open: A customer logs in to the app without opening a push notification on a particular day.
Opens: A customer opens a push notification on a particular day. This includes “open and log in."
To tune the number of states, we trained multiple HMM models with different numbers of states and chose a number that gave us both a stable system (high self-transition probability), as well as good predictive performance of logins and opens. The following figure describes a hypothetical three-state Markov model.
To determine an optimal push-cap for each customer state, we performed a grid search in an online A/B test framework where we experimented with a range of push-caps for each of the customer states. We selected a push-cap that performs well for both login and reachability metrics. For lighter customer states, the customer state-based push-cap performs better than the per-customer personalized push-cap. This system is easy to maintain and updates a customer’s push-cap whenever the underlying HMM predicts that they have transitioned to a new customer state.
While the cohort-based push-caps provide superior performance to a fixed push-cap, we can improve this by taking advantage of heterogeneity in response to push-caps across other customer features. However, building a state-based model with more complex features can quickly become unwieldy. Instead, we built counterfactual models of customer login and reachability behavior that can take advantage of a greater range of customer features, predicting how any given customer will respond to any given push-cap.
These predictions are taken over a substantial period to capture as much long-term customer behavior as possible, instead of short-term responses that fade with time. For example, a customer may respond to a high push-cap by logging in often and opening notifications, but eventually become desensitized to notifications, resulting in a drop-off in login rate. The window of time is still short enough that we needed to model reachability behavior as a long-term leading indicator of login behavior. We used a two-month period of time to generate labels for these models.
Once these models are trained, we input them into a utility maximization framework that factors in both types of customer feedback. While we can observe a login each day, reachability is more permanent, and we only consider whether the customer is reachable at the end of our time window.
Parameter ɑ is introduced to control the relative importance of each objective. For a customer with features 𝑥 and push-cap 𝑐, we have utility 𝑈_𝑥(𝑐) defined as = 𝐄[# logins | 𝑥,𝑐] + ɑ* 𝑝(reachability | 𝑥,𝑐).
We then assign a customer whichever push-cap maximizes the estimate of this utility (CATE estimation [1]). For example, for a customer with features 𝑥, we assign the push-cap argmax 𝑈_𝑥(𝑐), where the maximum is taken over the candidate push-caps. When ɑ = 0, we assign the push-cap with the highest login prediction, but as ɑ increases, we choose push-caps that favors and protects reachability.
For some customers, model-based push-cap assignment works great. But for other customers who do not use the platform as often, the push-cap model has few signals to learn from. For such customers, grid searched push-caps have better performance, while being easier to maintain, so in practice we only use the model-based assignments for a subset of customer cohorts.
With our push-cap assignment system, we observe +0.62% DAUs and insignificant reachability loss for iOS customers and +0.39% DAUs and insignificant reachability loss for Android customers.
Customers have different preferences toward push notifications volume. By leveraging machine learning to personalize the push-cap experience, we can keep customers informed with the optimal amount of notifications for their needs. However, machine learning is not a one-size-fits-all solution for all customer cohorts. Tuning the push-cap, based on a HMM-based customer state model, we can achieve better metrics for certain customer cohorts with a hybrid approach.
Push-cap Personalization was developed by Stephen Ragain, Prakhar Biyani, Jay Baxter, Jesse Kolb, Manish Vidyasagar, Lilong Jiang, Shaodan Zhai and Bowen Liu. Thanks to Quannan Li, Tom Hauburger, Sayan Sanyal, Jeremy Browning, Frank Portman, Lohith Vuddemarri for the project and this blog post. A special shout-out goes to leadership - Foad Dabiri, Rani Nelken - for supporting this project.
---
[1] Metalearners for estimating heterogeneous treatment effects using machine learning. Sören R. Künzel, Jasjeet S. Sekhon, Peter J. Bickel, and Bin Yu.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.