Insights
Graph machine learning with missing node features
By
and
Thursday, 17 March 2022
Graphs are a core asset at Twitter, describing how users interact with each other through Follows, Tweets, Topics, and conversations. Graph Neural Networks (GNNs) are a powerful tool that allow learning on graphs by leveraging both the topological structure and the feature information for each node. However, GNNs typically run under the assumption of a full set of features available for all nodes. In real-world scenarios, features are often only partially available; for example, in social networks, age and gender can be known for a small subset of users only. This post aims to show that feature propagation is an efficient and scalable approach for handling missing features in graph machine learning applications and that it works surprisingly well despite its simplicity.
Graph Neural Network (GNN) models typically assume a full feature vector for each node. Take for example a 2-layer Graph Convolutional Network (GCN) model [1], which has the following form:
Z = A σ(AXW₁) W₂
The two inputs to this model are the (normalised) adjacency matrix A encoding the graph structure and the feature matrix X containing as rows the node feature vectors and outputs the node embeddings Z. Each layer of GCN performs node-wise feature transformation (parametrised by the learnable matrices W₁ and W₂) and then propagates the transformed feature vectors to the neighboring nodes. Importantly, GCN assumes that all the entries in X are observed.
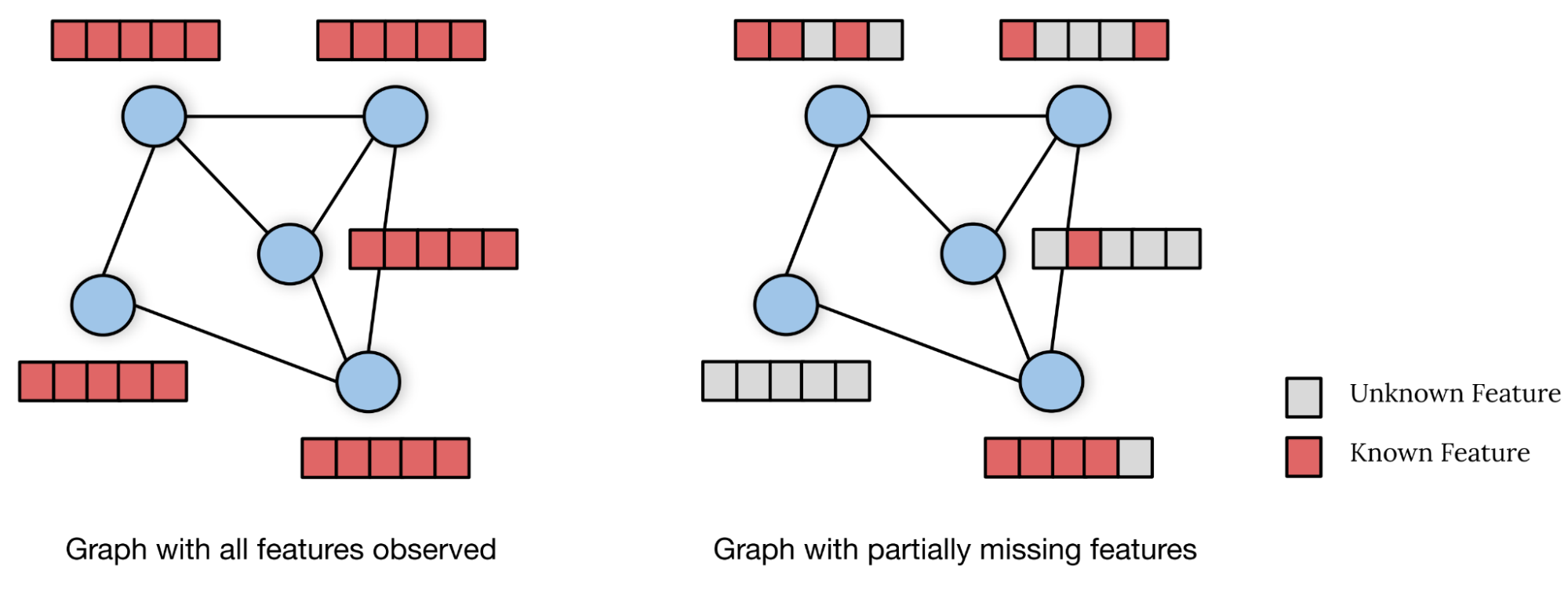
In real-world scenarios, we often see situations where some node features are missing (Fig 1). For example, demographic information such as age or sex can be available for a small subset of social network users, while features related to the content a user generates are generally only present for the most active users. In a co-purchase network, not all products may have a full description associated with them. This situation is becoming even more acute, as with the rising awareness around digital privacy, data is increasingly available only upon explicit user consent.
In all the above cases, the feature matrix has missing values, and most existing GNN models cannot be directly applied. Several recent works derived GNN models capable of dealing with missing features (see [2, 3]), which however suffer in regimes of high rates of missing features (>90%) and do not scale to graphs with more than a few million edges.
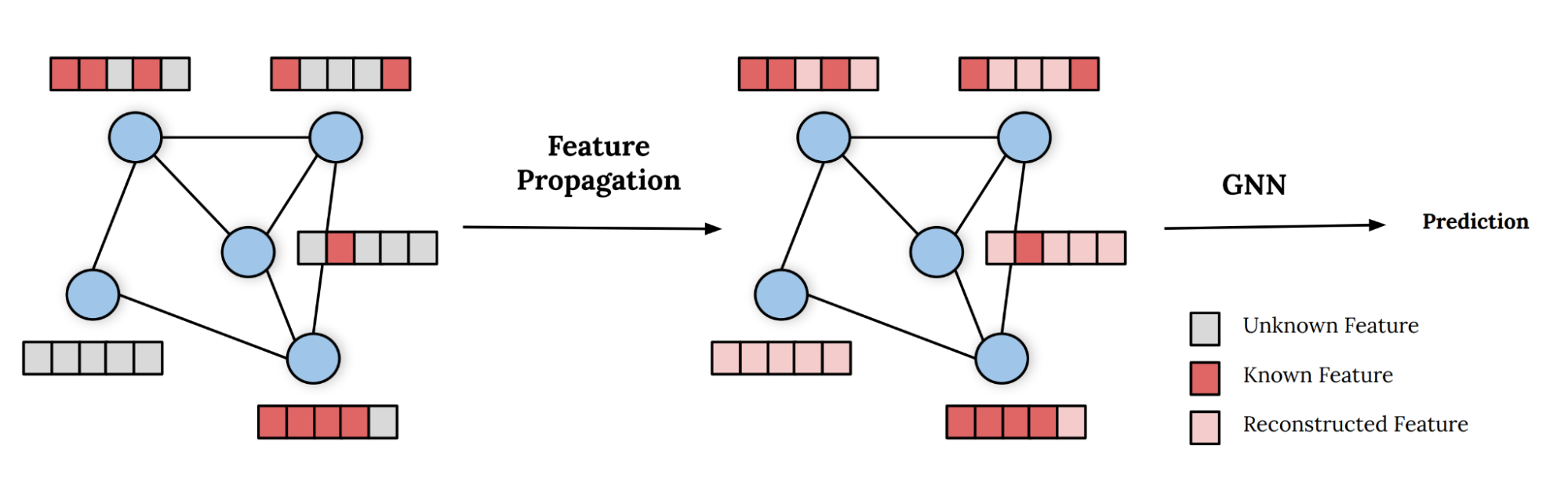
In a new paper [4] co-authored with Ben Chamberlain and Michael Bronstein (Twitter), Henry Kenlay and Xiaowen Dong (Oxford), we propose Feature Propagation (FP) as a simple but surprisingly efficient and effective solution to this problem. In a nutshell, FP reconstructs the missing features by propagating the known features on the graph. The reconstructed features can then be fed into any GNN to solve a downstream task such as node classification or link prediction. The diagram below illustrates this process.
The propagation step is very simple. At first, the unknown features are initialised with arbitrary values [5]. The features are propagated by applying the (normalised) adjacency matrix, followed by resetting the known features to their ground truth value. We repeat these two operations until convergence of the feature vectors [6]. The algorithm is illustrated in the following pseudo-code:
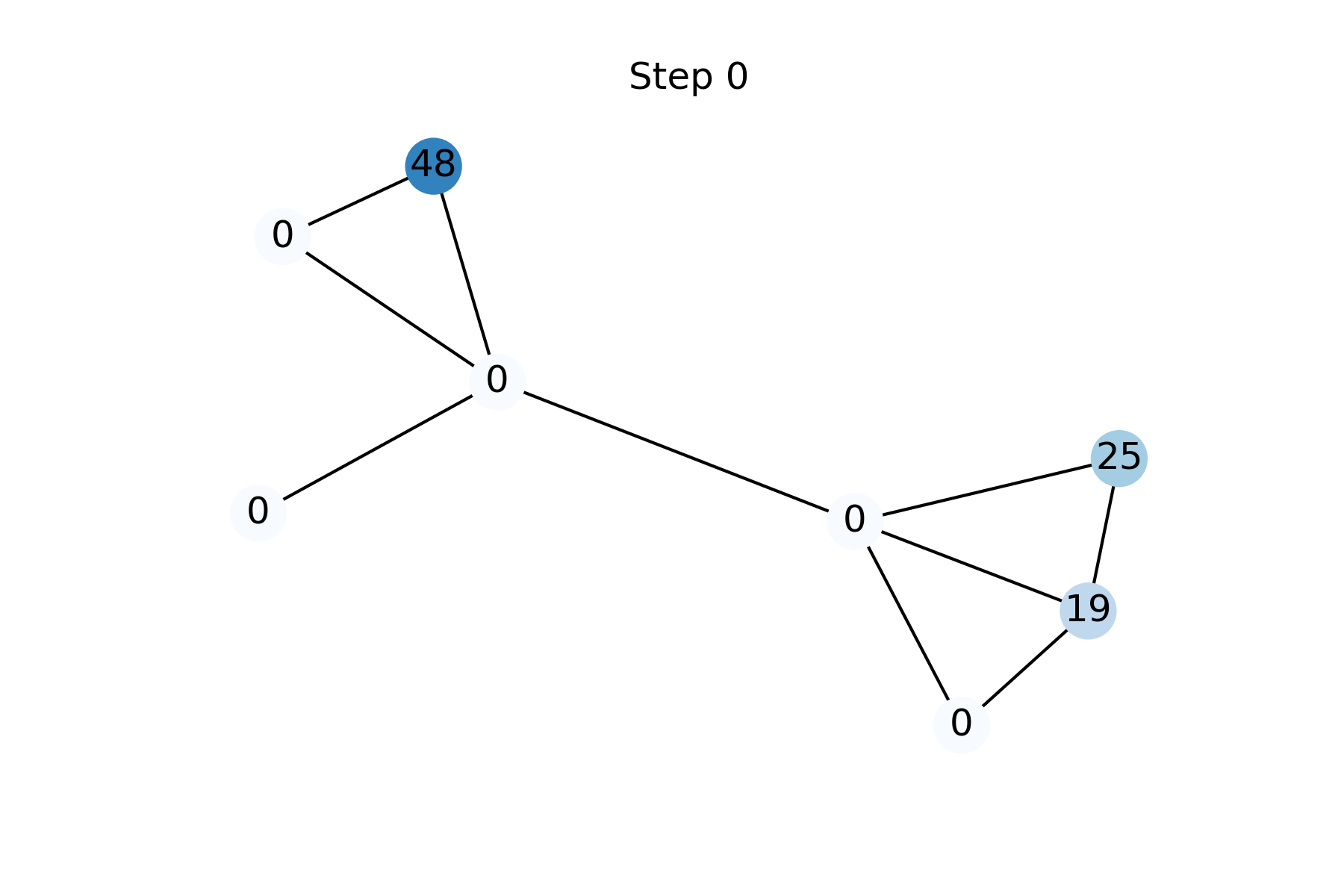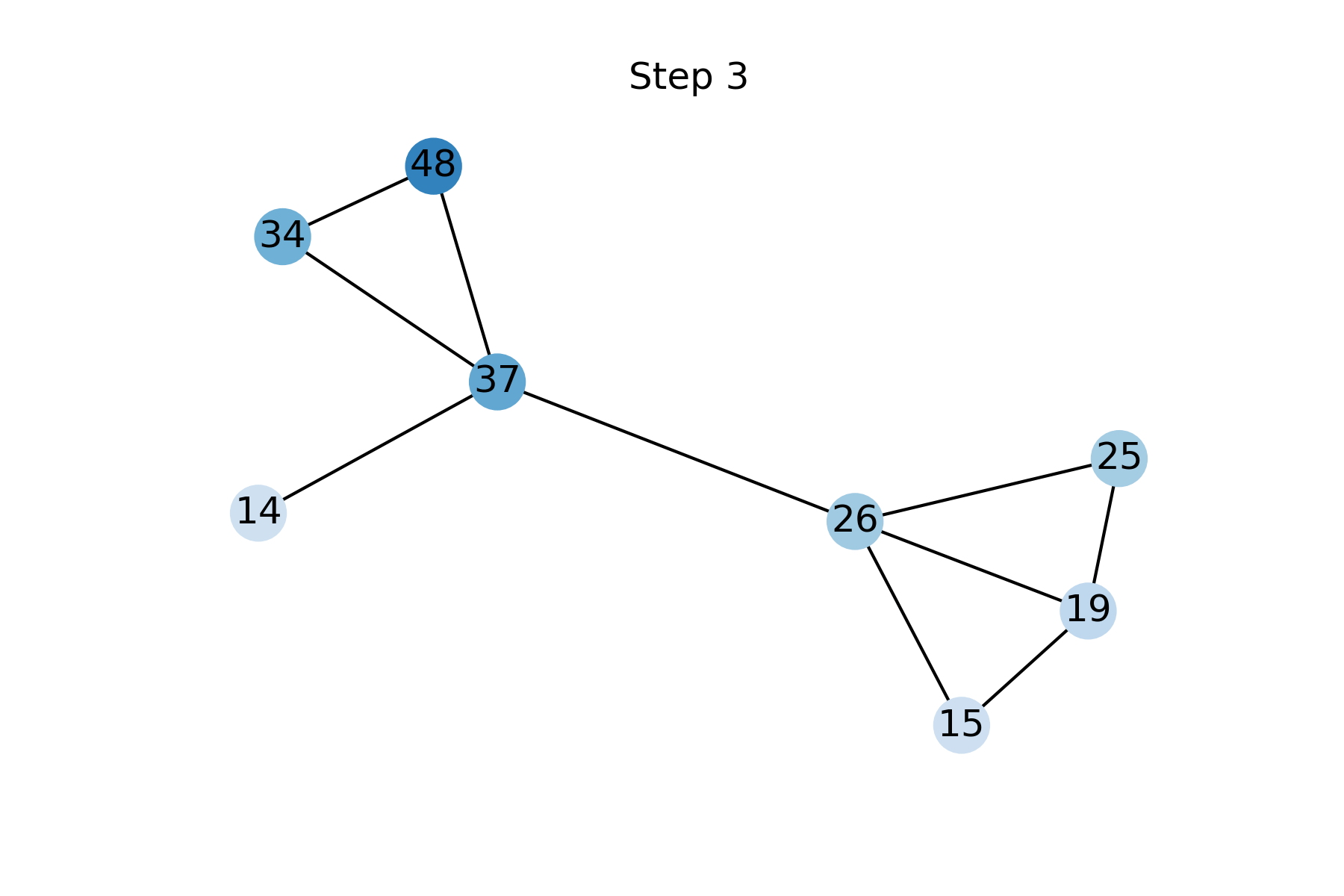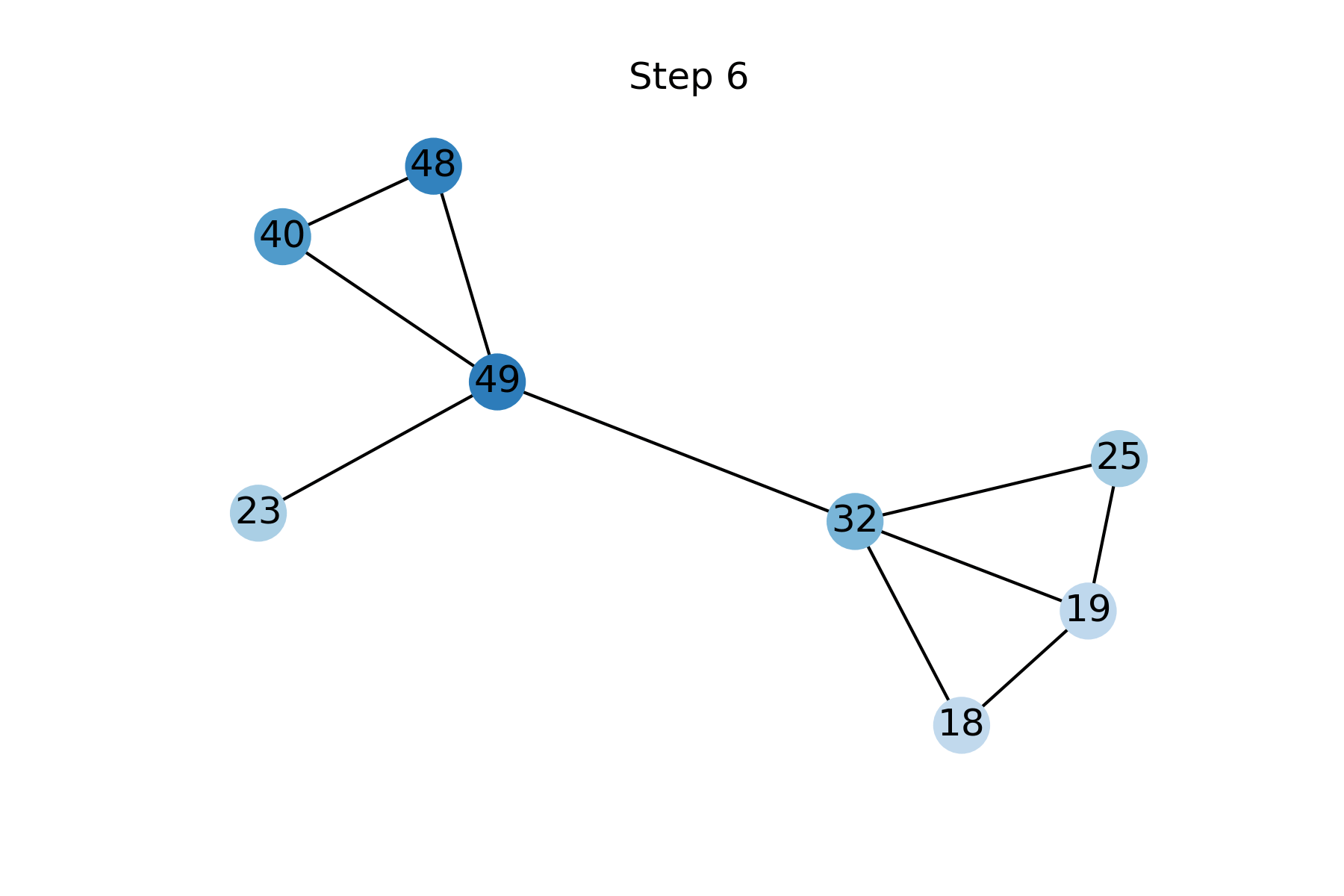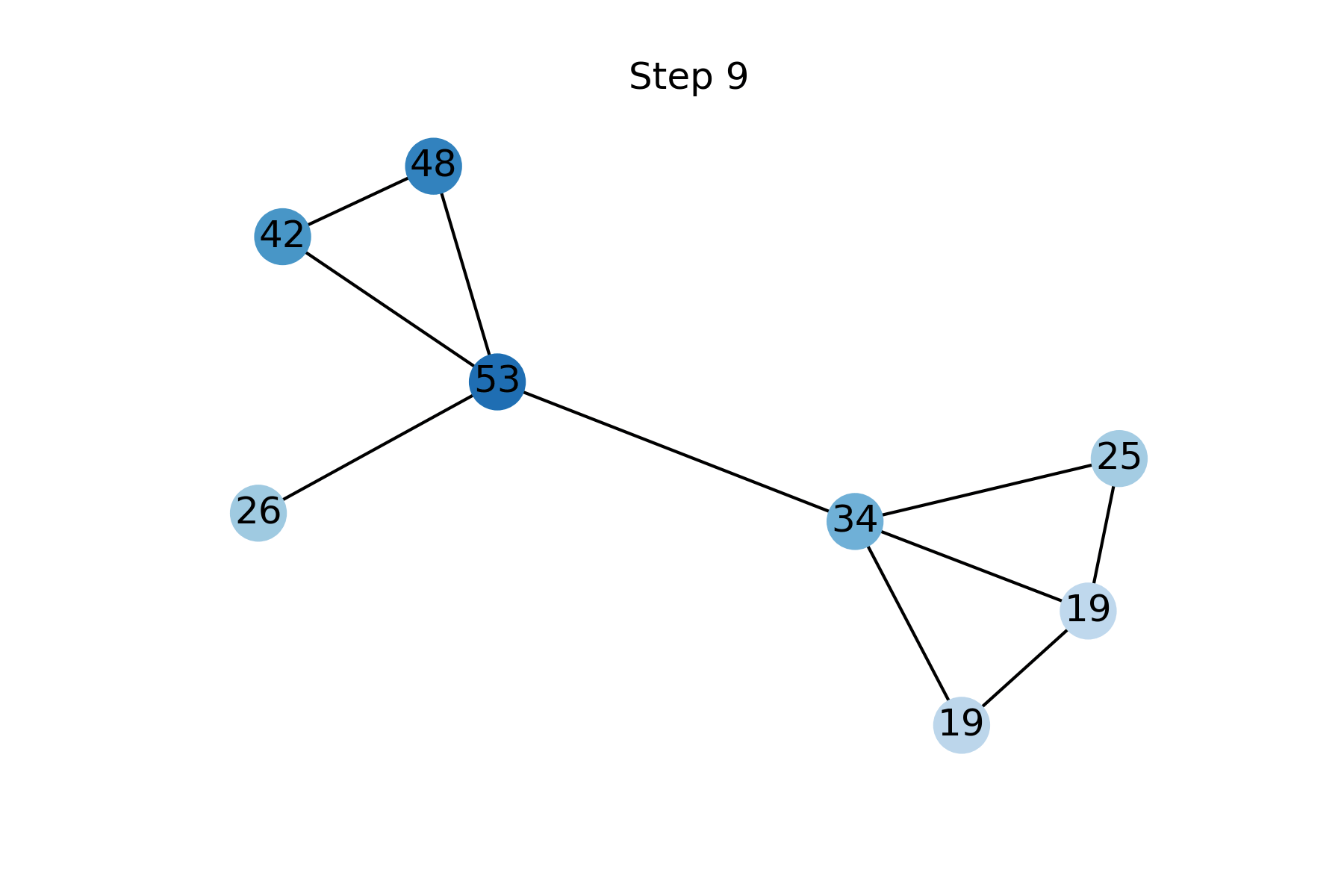
FP can be derived from the assumption of data homophily (`smoothness’), that is that neighbors tend to have similar feature vectors. The level of homophily can be quantified using the Dirichlet energy, a quadratic form measuring the squared difference between the feature of a node and the average of its neighbors. The gradient flow of the Dirichlet energy [7] is the graph heat diffusion equation, with the known features used as boundary conditions. FP is obtained as the discretisation of this diffusion equation using explicit forward Euler scheme with a unit step size [8]. Fig 3 shows the reconstruction of missing features by Feature Propagation at different steps.
Feature propagation bears similarity to label propagation (LP) [9]. However, the key difference is that LP is a feature-agnostic method and directly predicts a class for each node by propagating the known labels in the graph. On the other hand, FP is used to first reconstruct the missing node features, which are then fed into a downstream GNN. This allows FP to leverage the observed features and to outperform LP on all benchmarks we experimented with. Furthermore, it often happens in practice that the sets of nodes with labels and those with features are not necessarily fully overlapping, so the two approaches are not always directly comparable.
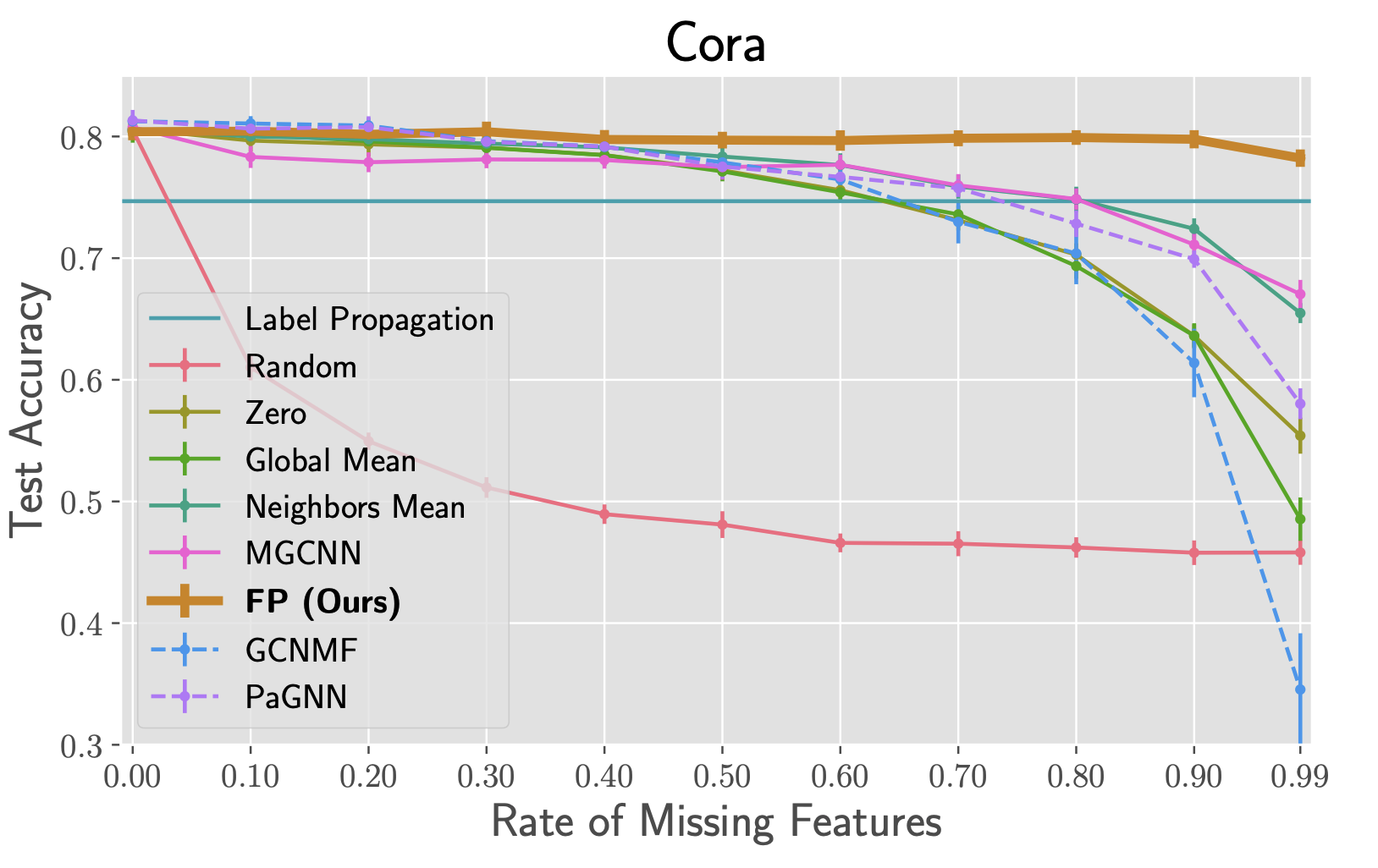
We conducted an extensive experimental validation of FP using seven standard node-classification benchmarks, in which we randomly removed a variable fraction of node features (independently for every channel). FP followed by a 2-layer GCN on the reconstructed features significantly outperformed both simple baselines as well as most recent state-of-the-art methods [2-3]. Fig 4 shows the plot for the Cora dataset (the plots for all other datasets can be found in our paper [4]).
FP particularly shone in regimes of high rates of missing features (>90%), where all other methods tend to suffer. For example, even with 99% of features missing, FP only loses around 4% of relative accuracy on average compared to the same model when all features are present.
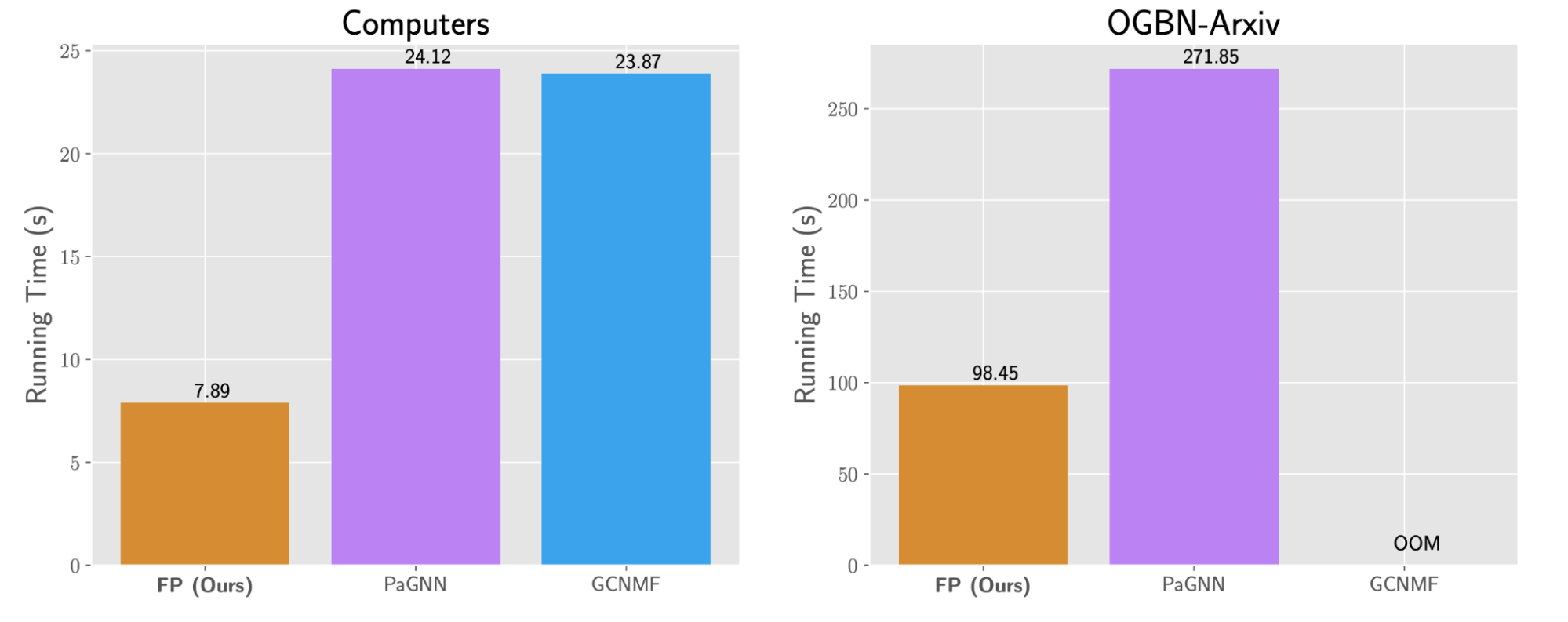
Another key feature of FP is its scalability. While competing methods fail to scale beyond graphs with a few million edges, FP can scale to billion edge graphs.
It took us less than one hour to run it on an internal Twitter graph with around 1 billion nodes and 10 billion edges using a single machine. In Fig 5 we also compare the run-time of training FP with a downstream GCN, compared to PaGNN and GCNMF.
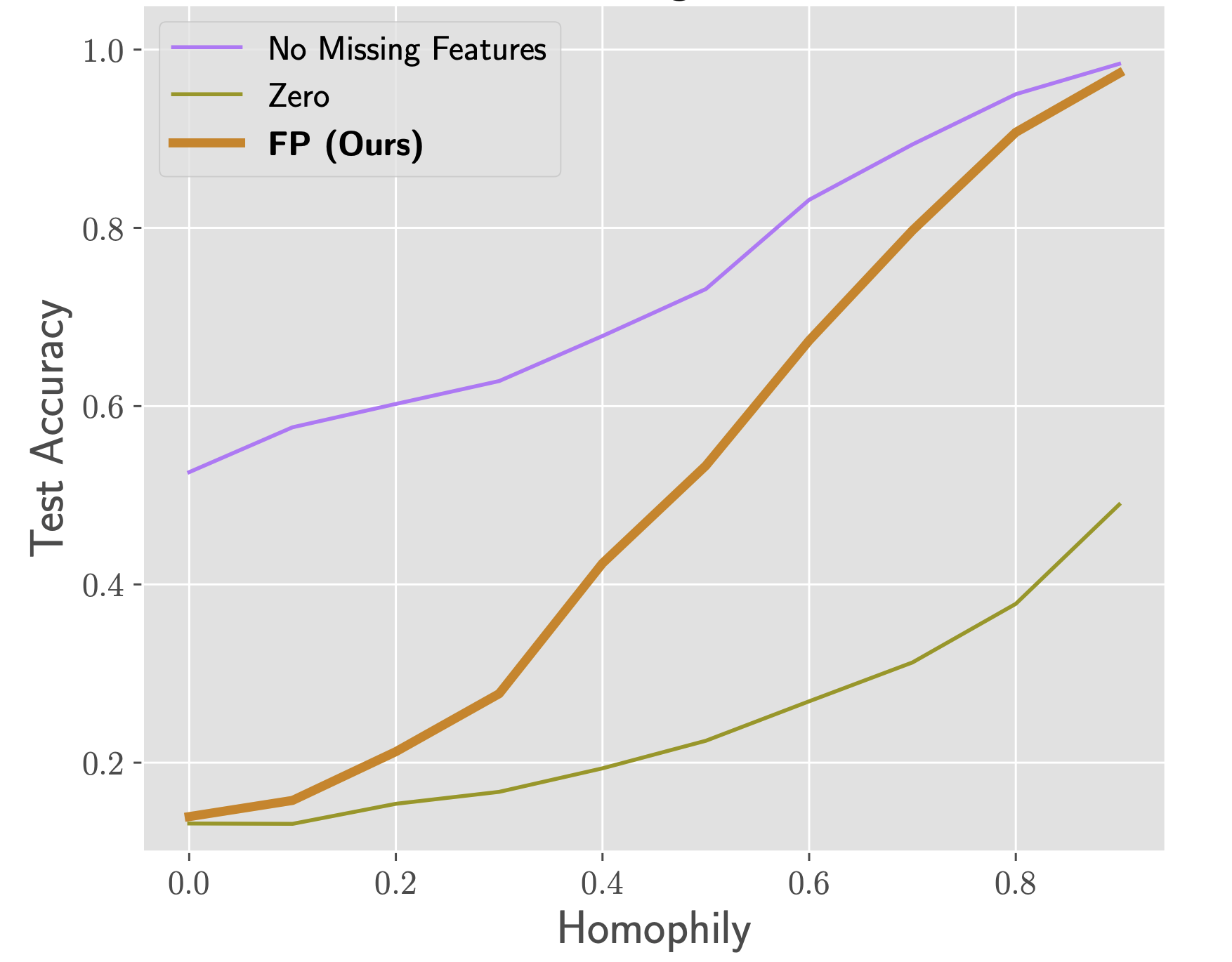
Among the current limitations of FP is that it does not work well on heterophilic graphs, that is, graphs where neighbors tend to have different features (Fig 6). While in the highly-homophilic setting FP performs almost as well as with having the full features, in low-homophily settings the gap between the two is significant, and the performance of FP deteriorates to that of a simple baseline where missing features are replaced with zeros. This is not surprising as FP is derived from a homophily assumption by virtue of the minimisation of the Dirichlet energy through the diffusion equation. Furthermore, FP assumes the different feature channels to be uncorrelated, which is rarely the case in real life. Accommodating both of these limitations is possible with alternative more complex diffusion mechanisms.
In conclusion, learning on graphs with missing node features is an almost unexplored research area, despite its ubiquitousness in real-world applications. We believe that our Feature Propagation model is an important step towards advancing the ability to learn on graphs with missing node features. It also raises deep questions on the theoretical capability to learn in this setting as a function of assumptions about the signal and the structure of the graph. The simplicity and scalability of FP, together with astonishingly good results compared to more complex methods, even in extreme missing features regimes, make it a good candidate for use in large-scale industrial applications.
[1] T. Kipf and M. Welling, Semi-Supervised Classification with Graph Convolutional Networks (2017), ICLR.
[2] H. Taguchi et al., Graph Convolutional Networks for Graphs Containing Missing Features (2020), Future Generation Computer Systems.
[3] X. Chen et al., Learning on Attribute-Missing Graphs (2020), arXiv:2011.01623
[4] E. Rossi et al., On the Unreasonable Effectiveness of Feature propagation in Learning on Graphs with Missing Node Features (2021), arXiv:2111.12128
[5] We prove that the algorithm converges to the same solution, regardless of the initialisation of the unknown values. However, a different initialisation may lead to a different number of iterations necessary to converge. In our experiments we initialise the unknown values to zero.
[6] We found ~40 iterations to be sufficient for convergence on all datasets we experimented with.
[7] A gradient flow can be seen as a continuous analogy of gradient descent in variational problems. It arises from the optimality conditions (known in the calculus of variations as Euler-Lagrange equations) of a functional.
[8] B. Chamberlain et al., GRAND: Graph Neural Diffusion (2021), ICML. See also the accompanying blog post.
[9] X. Zhu and Z. Ghahramani, Learning from Labeled and Unlabeled Data with Label Propagation (2002), Technical Report.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.