Open source
Simplify Service Dependencies with Nodes
By
Friday, 11 November 2016
RPC services can be messy to implement. It can be even messier if you go with microservices. Rather than writing a monolithic piece of software that’s simple to deploy but hard to maintain, you write many small services each dedicated to a specific functionality, with a clean scope of features. They can be running in different environments, written at different times, and managed by different teams. They can be as far as a remote service across the continent, or as close as a logical component living in your own server process providing its work through an interface, synchronous or asynchronous. All said, you want to put together the work of many smaller components to process your request.
This was exactly the problem that Blender, one of the major components of the Twitter Search backend, was facing. As one of the most complicated services in Twitter, it makes more than 30 calls to different services with complex interdependencies for a typical search request, eventually reaching hundreds of machines in the data center darkness. Since its deployment in 2011, it has gone through several generations of refactoring regarding its dependency handling.
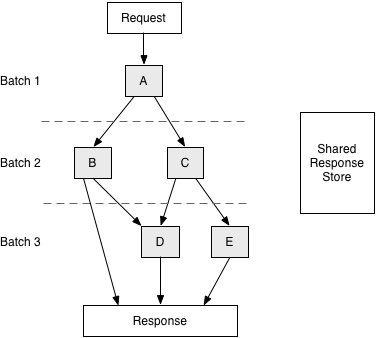
At the beginning, it was simple. We had to call several backend services and put together a search response with the data collected. It’s easy to notice the dependencies between them: you need to get something from service A if you want to create a request for service B and C, whose responses will be used to create something to query service D with, and so on. We can draw a Directed Acyclic Graph (DAG) for dependencies between services in the workflow that processes the request, like this one:
Figure 1
Obviously there’s some parallelism we can exploit: service B and C can be executed at the same time, as can D and E, as they don’t depend on each other. Our first solution for the execution was to run a topological sort on the graph and break it into batches. All services in the same batch can be run at the same time. Batches were implemented using Netty pipeline and there is effectively a barrier at the end of each batch, so the workflow will only proceed to the next batch when all service calls in the current one have finished. The responses from all services are put into a shared store, a monolithic function pulls necessary responses from it to create new requests for services in the next batch.
This design works for simple workflows, but there are some problems. First, its execution is not efficient. Clearly service E can start as soon as C is done and doesn’t have to wait on B, as it doesn’t depend on it. However, they are in different batches, so it has to wait. What if B takes a long time? This introduces a false dependency and reduces parallelism. Second, and more importantly, there’s no enforcement of the data dependency because of the shared response store. The graph above only defines the execution order. When you create the request for service D, there’s nothing preventing you from fetching things other than responses from B or C, like E’s response. You can try to get responses from services not executed yet, and it needed a lot of programmer’s discretion to get things right.
Another problem is that we only allowed one instance of each service in the graph, so it was not easy to call the same service multiple times within a single request. It was also hard to write code that made dynamic decisions regarding the execution of the graph based on the execution state, e.g. skipping a section of graph. Everything was fixed in advance.
What if you want to reuse a part or all of a graph? It’s hard. Each workflow is conceptually a graph, merging multiple graphs should just get you a bigger graph, not something totally different. We were not properly exploiting the recursive nature of graphs to simplify our code. The lack of modularity in the code also made testing hard, as there was no straightforward way to pull out a piece of workflow and test it.
We used to have separate workflows (each being a graph) for different types of search, like search for Tweets, search for accounts, etc. The frontend had to make multiple calls to the backend to get results together and display them. We wanted to create a composite search result page with all kinds of results processed together, so that we have a better chance of organizing them nicer in a stream. This was our “Universal Search” project back in 2012. Merging many existing graphs (workflows) into a new one was pretty much a handicraft: you had to resolve conflicts, watch out for duplicate service calls, and even manually adjust graph edges to work around the batching to get optimized execution, not wasting much parallelism. Adding a tiny edge in the graph could throw off your batching and accidentally increase the latency. This was definitely not the right thing to keep in the long run. Our complexity had outgrown the design, and we needed to have something new.
Around mid-2011, Twitter released Finagle, a Scala library to implement protocol-agnostic RPC systems. It introduced a nice paradigm for concurrent programming with Futures. A Future represents an asynchronous data object whose value will become available some time in the, well, future. It supports a set of operations for transforming them, merging them, and dealing with their failure and exceptions with callbacks. Logically, this is bridging the barrier of synchronous and asynchronous programming. Your logic is still function-like, taking inputs and producing an output, except that inputs could be asynchronous and not ready when the function call is made (or attached), so it has to wait. The concept of Future decouples the computation logic from the execution of the dependency graph, allowing programmers to better focus on the application logic, rather than gathering and synchronizing the things produced in various threads.
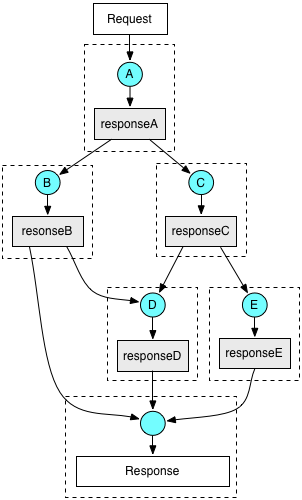
Finagle was a natural fit for Blender as it solved a big problem we had on the service batch design: the dependencies are actually between the data, not between the computation processes themselves that generate the data. From the perspective of a computation process, where its inputs are produced is irrelevant, it can flow in from anywhere. With this idea, we can redraw our dependency graph:
Figure 2
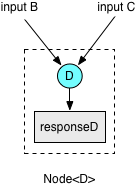
In the diagram, we have separated the data (gray boxes) and the computation processes (blue dots). Each process takes one or more pieces of data as inputs, and produces a single output. The process can start as soon as its input are ready, and not subject to any arbitrary batching. You can easily write every process as a function (in Java), e.g. for process D:
Internally, there could be one of the following mirror functions that provides the real logic, depending on whether the actually process to produce D’s response is synchronous or asynchronous.
Notice that they have all input arguments “de-futured”, that is, they are only called when the values for B and C are ready and resolved into their original types, which is guaranteed by the scheduling/execution framework. The framework we used is Finagle, or its Futures programming paradigm to be more specific. This function duality between process() and syncProcess/asyncProcess() is just an artifact of the fact that asynchronous processing is not a primitive action in our programming language (Java). Finagle fills this gap with its Future operations. Now you can write code like:
or, if the value of D cannot be directly computed, but has to be acquired through a remote service:
The application logic is only in syncProcess() or asyncProcess(), but there’s a lot of boilerplate code to just connect the worlds of Futures and non-Futures. When it comes to multiple inputs and complex dependency chains, it can again become a bit messy. You can de-future your Futures at any place and end up having some methods with partly Future and partly non-Future arguments. Sometimes you want to have control flow logic on Futures, like “if Future<A> has value X then we compute Future<B> this way, or we call process X and produce it another way.” You end up with a lot of callbacks and risk running out of indentations had you not properly organized your calls. The dual functions are also not very elegant, resulting in boilerplate and repetitive code. Java should take part of the blame (it looks better in Scala, and also in Java 8 with lambdas), but it’s also because the asynchronous processing here is still not transparent enough. The Future programming paradigm provides good primitives, but the computation logic lives in the cracks of these primitives – it’s the glue putting them together that ruins the readability.
Nonetheless, Finagle still solved a huge problem for us as we now have real data dependencies and a more efficient execution engine. We gradually converted the Blender workflow code from batch style to Future style in 2013. It ran faster, the code became less error-prone but the readability was still not perfect. It was hard to follow, a pain to debug, tricky to test, and there were lots of duplicate function names.
Then we introduced Nodes.
Let’s look at the modified dependency graph again.
Figure 3
The process D takes input B and C, and produces a value of type D. Rather than passing them around as Future<B>, Future<C> and Future<D>, we come up with a new concept of Node, a Future-like object which combines the computation logic and the data being produced, and abstracts away the “de-futuring” code that had to coexist with the computation logic before. Unlike Futures, Nodes can have dependencies declared in it, and you can construct a Node with all its dependencies. However, a node can also have no dependency at all, wrapping directly around a computation process or even a literal value. Nodes and Futures are compatible and mutually convertible, so we could migrate our original code piece by piece.
You can consider Node as an asynchronous processing unit: it can be instantiated as many times as you wish, each time taking the same or different inputs. Depending on how many inputs you have, we provide several styles for you to specify them, either through a simple mapping with Java 8 lambdas, or from enum-based named dependencies handled in a separate class if the logic is more complex. It doesn’t matter if your computation is big or small, remote or local, synchronous or asynchronous. The Nodes library makes all these transparent to the programmer assembling the graph. It doesn’t say how each Future is to be fulfilled, this matters only to the Nodes that actually does asynchronous computations. The scheduling of these computations could be completely blocking, or based on thread pools implemented by yourself, or provided by other frameworks, like Finagle.
To implement the dependency graph in Figure 1 above, your code may look like:
Here it lists several possible ways to wrap and create Nodes, though not exhaustively. With Nodes, all dependencies are explicit, and a computation process in the Node would only have access to the data it explicitly depends on. Dependencies can be defined as required or optional. A Node’s failure (say, an exception is thrown during its execution) won’t affect the downstream Node optionally depending on it.
A Node will not automatically execute once it’s created, this only sets up the dependency graph. You need to call .apply() on the node you want response for. This will in turn trigger the execution of all its dependencies, and recursively their dependencies. A Node will execute only once and cache its result.
We provide a lot of convenient utilities on top of Nodes to make writing asynchronous code even easier:
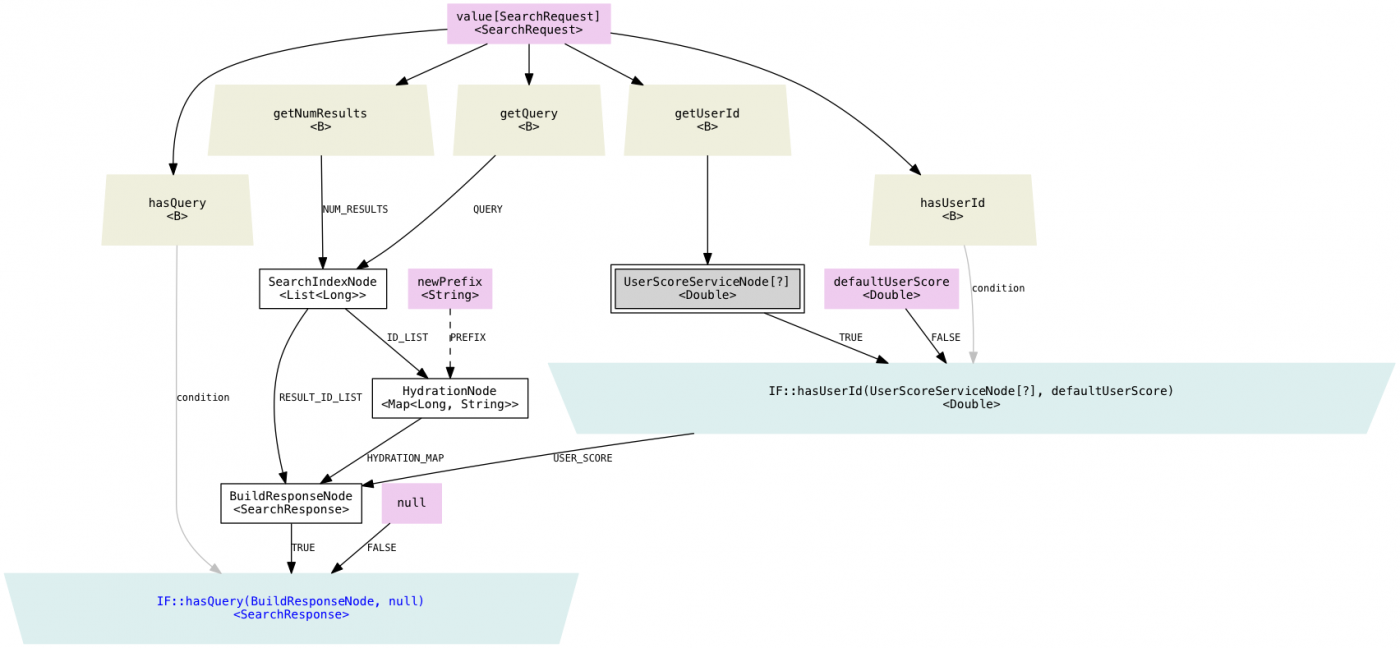
Here is an example of the graph generated from our example code on Github:
Figure 4
We have created a set of guidelines and best practices for writing Nodes code available with our tutorials on Github.
After using this compact library for two years in our production search backend and serving billions of requests, we believe it’s mature enough to release to the open source community. We have saved thousands of lines of code, improved our test coverage and ended up with code that’s more readable and friendly for newcomers. We believe this can help other engineers writing concurrent applications or services, especially making it much easier to implement complex dependency graphs.
The application of Node can be taken farther than merely writing RPC services. It doesn’t have to be for short-lived executions like processing server requests. What if a Future can take days to fulfill? What if you can serialize and checkpoint the state of a graph and even resume it? We have experimented with some of these idea and are looking forward to seeing other novel applications of the Nodes framework.
You can download Nodes from https://github.com/twitter/nodes and read our tutorials and example code.
Many people have contributed to this library, they are: Brian Guarraci, Tian Wang, Yatharth Saraf, Lisa Huang, Juan Manuel Caicedo, Andy Schlaikjer.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.