Open source
Dropping cache didn’t drop cache
By
Friday, 7 May 2021
The article requires some prerequisite knowledge about Linux kernel memory management subsystem.
Recently, while investigating an OOM (out-of-memory) problem, Twitter engineers found that the slab cache was increasing consistently, but the page cache was decreasing consistently. A closer look showed that the highest consumption of the slab cache was the dentry cache, and the dentry caches were charged to one memory control group (cgroup). It seems that the Linux kernel’s memory reclaimer only reclaimed the page cache, but didn’t reclaim the dentry cache at all.
We tried to drop the slab cache by running:
# echo 2 > /proc/sys/vm/drop_cachesbut surprisingly it didn’t drop the cache.
By debugging the problem, we found that there was a rare race condition in the shrinker code.
To fully understand what prevented the slab cache from being dropped, we need to take a closer look at the Linux kernel internals, particularly the following memory management subsystem:
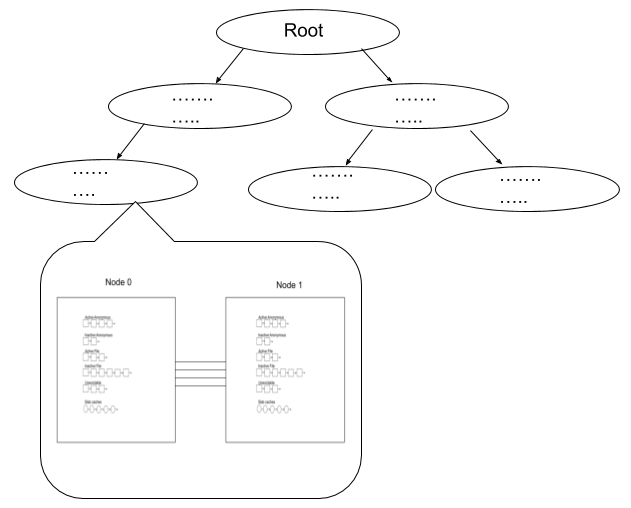
The memory resource for a machine is not infinite.There might be more demand than supply for memory resources if we run multiple programs simultaneously or run a very big program. Once available memory is low, the memory reclaimer (aka kswapd or direct reclaim) tries to evict “old” memory to free enough space to satisfy the allocators. The reclaimer scans lists (most of which are least-recently-used lists, aka LRU) to evict the not-recently-used memory. The lists include anonymous memory lists, file memory lists, and slab caches (Figure 1).
The reclaimer scans all the above lists, except the unevictable list. However, sometimes the reclaimer only scans a few of them. For example, the reclaimer does not scan the anonymous memory list if the swap partition is not available.
When the reclaimer is trying to reclaim slab caches, it needs to call shrinkers. Slab caches are memory objects with different sizes managed by different subsystems. For example, this includes the inode cache and dentry cache. Some slab caches are reclaimable. Since these caches hold the data for specific subsystems and have specific states, they can be reclaimed by dedicated shrinkers that understand how the caches are managed.
Filesystem metadata caches have a dedicated shrinker for each segment of metadata. The reclaimable filesystem metadata caches are in memory cgroup-aware and non-uniform memory access (NUMA) aware LRU lists. The shrinker scans these lists to reclaim some of the caches when memory pressure is hit.
For modern data centers, cgroups are usually used to manage resources and to achieve better resource isolation. The memory cgroup is used to manage memory resources.
Before the memory cgroup is present the aforementioned LRU lists are attached to NUMA nodes.
When the memory cgroup is present, the LRU lists are at per-memory-cgroup and per-node level. Each memory cgroup has its own dedicated LRU lists for the memory reclaimer Figure 3.
When reclaiming memory, the memory reclaimer traverses all memory cgroups to scan the LRU lists.
For a typical production deployment, there may be around 40 shrinkers, including filesystem metadata shrinkers for each super block.
When there are many memory cgroups and many shrinkers, serious scalability problems may occur if all the shrinkers are called for all the memory cgroups. These problems happen even though there is not a reclaimable object for some shrinkers.
The upstream kernel introduced an optimization, called shrinker_maps. It is a bitmap that indicates which shrinkers have reclaimable objects so that they are called. The bitmap is set when a new object is added to the LRU, and is cleared when the LRU is empty. The optimization made the aforementioned scalability issue gone. When one memory cgroup is offlined (for example, when the directory is removed) its LRUs are spliced to its parent memory cgroup and the parent memory cgroup’s bitmap is set accordingly.
The following command traverses all LRU lists, from all memory cgroups, to shrink all reclaimable objects.
# echo 2 > /proc/sys/vm/drop_cachesBy checking memory related statistics (for example, /proc/meminfo and /proc/slabinfo) exported by the kernel and checking slab usage using slabtop, it seems that dentry caches consume around 2GB memory under one memory cgroup. This means there should be around 10 million dentry objects since typically the dentry object size is 192 bytes. The dropping cache should be able to shrink most of them.
However, there might be a couple of reasons that the dropping cache doesn’t drop slab caches. For example, the LRU list might be short or the objects might be referencing or locked when scanning and therefore temporarily unreclaimable.The next step is to get some insight about what is going on with the shrinkers.
The Linux kernel provides plenty of ways to observe how the kernel runs. The built-in tracepoints are one of the most used ones. There are two tracepoints about shrinker:
There are a couple of different tools to enable tracepoints and get tracing logs. For example, directly manipulating the files under debugfs, perf, or trace-cmd. We personally prefer trace-cmd, which is a package that supports plenty of commands for kernel tracing. The package is also supported by almost all distros. For the usage of trace-cmd, please refer to the manpage.
The following command starts tracing for the shrinker tracing points:
# trace-cmd start -e vmscan:mm_shrink_slab_start -e vmscan:mm_shrink_slab_endThen, this command shows the tracing log:
# trace-cmd showThe tracing result looks like, for example, the following:
kswapd1-474 [066] .... 508610.111172: mm_shrink_slab_start: super_cac
he_scan+0x0/0x1a0 000000000043230d: nid: 1 objects to shrink 0 gfp_flags GFP_KERNEL cache items 38084993 delta 18596 total_scan 18596 priority 12
kswapd1-474 [066] .... 508610.139951: mm_shrink_slab_end: super_cache
_scan+0x0/0x1a0 000000000043230d: nid: 1 unused scan count 0 new scan count 164 total_scan 164 last shrinker return val 18432
By analyzing the tracing log, it seems that the dentry caches under some cgroups which consume the most dentry caches were not scanned at all. This means that the shrinker was even not called. It definitely looks odd!
As aforementioned, the only way that the shrinkers can be prevented from being called is if the shrinker_map bitmap is cleared. But the LRU list must be empty. Is it possible that the shrinker bitmap is cleared, even though there are still objects on the LRU list? We need to inspect shrinker-related kernel data structures to find out what was going on.
We could inspect kernel data structures by a couple of tools, for example, the well-known crash-utility. Here we used drgn. Drgn supports programming with Python and live debugging.
With the Python script below, we can easily inspect the length of the LRU list and shrinker_map bitmap for a specific memory cgroup:
for user in css_for_each_child(prog['root_mem_cgroup'].css):
if (user.cgroup.kn.name.string_().decode() == "user.slice"):
break
memcg = container_of(user, 'struct mem_cgroup', 'css')
nr_items=0
for sb in list_for_each_entry('struct super_block', prog['super_blocks'].address_of_(), 's_list'):
nr_items += sb.s_dentry_lru.node.memcg_lrus.lru[9].nr_items
bitmap = memcg.nodeinfo[0].shrinker_map.map[0]The nr_items shows the length of the dentry LRU lists and bitmap shows the shrinker_map bitmap.
The result shows that there were around 10 million dentry cache objects on the LRU list, and that most of them were reclaimable. So, the LRU list is definitely not empty. But the shrinker_map bitmap shows the corresponding bit was cleared.
It really seems weird that the bit was cleared even though there were abundant reclaimable caches. It smells like a kernel bug.
By reading the kernel code, it seems that the kernel clears the bitmap if and only if the corresponding LRU list is empty. The kernel sets the bit when:
Since our use case creates and removes memory cgroups very frequently, reparenting happens very often. It seems like there might be some problems with reparenting.
Further code inspection leads to the below possible race condition:
| CPU A | CPU B |
| reparent | |
| dst->nr_items == 0 | |
| shrinker: | |
| total_objects == 0 | |
| add src->nr_items to dst | |
| set_bit | |
| return SHRINK_EMPTY | |
| clear_bit | |
| child memcg offline | |
| replace child's kmemcg_id with | |
| parent's (in memcg_offline_kmem()) | |
| list_lru_del() between shrinker runs | |
| see parent's kmemcg_id | |
| dec dst->nr_items | |
| reparent again | |
| dst->nr_items may go negative | |
| due to concurrent list_lru_del() | |
| The second run of shrinker: | |
| read nr_items without any synchronization, so it may | |
| see intermediate negative nr_items then total_objects | |
| may return 0 coincidently | |
| keep the bit cleared | |
| dst->nr_items != 0 | |
| skip set_bit | |
| add scr->nr_item to dst | |
| After this point dst->nr_item may never go zero, so | |
| reparenting will not set shrinker_map bit anymore. |
Once the race condition is located, the fix seems easy. It actually just has a couple of lines:
diff --git a/mm/list_lru.c b/mm/list_lru.c
index 8de5e37..1e61161 100644
--- a/mm/list_lru.c
+++ b/mm/list_lru.c
@@ -534,7 +534,6 @@ static void memcg_drain_list_lru_node(struct list_lru *lru, int nid,
struct list_lru_node *nlru = &lru->node[nid];
int dst_idx = dst_memcg->kmemcg_id;
struct list_lru_one *src, *dst;
- bool set;
/*
* Since list_lru_{add,del} may be called under an IRQ-safe lock,
@@ -546,11 +545,12 @@ static void memcg_drain_list_lru_node(struct list_lru *lru, int nid,
dst = list_lru_from_memcg_idx(nlru, dst_idx);
list_splice_init(&src->list, &dst->list);
- set = (!dst->nr_items && src->nr_items);
- dst->nr_items += src->nr_items;
- if (set)
+
+ if (src->nr_items) {
+ dst->nr_items += src->nr_items;
memcg_set_shrinker_bit(dst_memcg, nid, lru_shrinker_id(lru));
- src->nr_items = 0;
+ src->nr_items = 0;
+ }
spin_unlock_irq(&nlru->lock);
}
We contributed the patch to the upstream kernel and it has been merged into the mainline kernel tree. See commit on git.kernel.org.
To investigate the issue, we used the drill-down analysis method and USE method (Utilization, Saturation and Error). Our process was the following:,
We also identified a couple of contributing factors with this approach and these tools.
The various kinds of tools we used were:
Memory reclamation is one of the most complicated parts of the Linux kernel. It is full of heuristic algorithms, complex corner cases, complicated data structures, and convoluted interaction with other subsystems. Memory reclamation is the core part of the Linux kernel and is relied upon by other subsystems. However, the bugs or suboptimal behaviors of memory reclamation may take a long time to get discovered. The fixes may be quite subtle and the validation may take substantial efforts to guarantee no regressions.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.