
Twitterスケールでの弾力的な広告配信
木曜日, 2016年4月7日木曜日
今回はTwitterの技術面のお話です。Twitterの広告サービスの裏にあるシステムをご紹介します。
人気のイベントやニュース速報、そのほか世界のどこかで事件が起こると、何億もの人々が Twitter を訪れ、大量のトラッフィクが発生します。ほとんどの場合これは予測不可能です。広告主の方々は、それぞれがターゲットとする利用者の方々にリーチするために、このような機会に迅速に反応します。その結果として、Twitter の広告の需要が急増します。このように変動する環境の中で収益を生む Twitter の広告配信システムは、広告のマッチング、スコア付け、そして配信を、巨大な規模で実現しています。私たちの広告配信システムの目標は、負荷が急上昇した時にも Twitter スケールのクエリをスムーズに処理し、すべてのクエリに対して最適な広告を見つけ出し、コンピューティングリソース使用量を常に最適なレベルに保つことです。
この目標を達成するために私たちが行っている手法のひとつをご紹介します。
広告配信パイプラインの簡単な説明
技術的な詳しい説明をする前に、広告配信パイプラインについて簡単に説明します。パイプラインは次の図のように、いくつかのフェーズからなる漏斗のような作りで成り立っています。
セレクション / Selection
「セレクション」フェーズでは、各クエリに対して広告候補の全体をふるいにかけ、クエリを送ったユーザーを対象とする広告の集合を見つけます。セレクションの結果、数十の広告に絞られることもあれば、数千の広告が選択されることもあります。選択された広告候補すべてが、この後のフェーズに送られます。特定のクエリに対していくつの広告候補が選ばれるかは、ユーザー属性とすべての広告のターゲティング情報との比較によって決まります。すべてのユーザーがすべての広告の対象となるわけではありません。
エンゲージメント率の予測 / Engagement rate prediction
例えば、クリック、フォロー、リツイートなど、各広告ツイートに対する反応を「エンゲージメント」と呼びます。それを広告ツイートの合計表示数で割った値が「エンゲージメント率」です。エンゲージメント率は、広告とユーザーとの関連性を決める上でとても重要です。たとえば「ユーザー U が広告 A にエンゲージする可能性はあるか?」という質問に答えることができます。この値はリアルタイムに変化し、ユーザーの特性と広告主の特性とを基とした機械学習モデルによって評価されます。
エンゲージメント率の評価は、広告配信パイプラインの中で計算負荷が最も高いフェーズです。そのため、Twitter のシステムでは予測プロセスを複数回実行し、広告を徐々に絞り込み、最終的にオークションにかける広告を決定します。まず、セレクションフェーズで選ばれた広告候補全体に、軽量な予測プロセスを適用します。そして、この結果の上位 k 個(数百)のみが、重い予測プロセスとオークションの候補になります。真に最適な広告を見つけるには、セレクションフェーズで選ばれた広告すべてをオークションにかける必要があります。したがって、k を小さくすることでオークションの CPU 負荷とレイテンシーを下げることはできますが、同時に品質がわずかに低い広告を配信することになります。このように、k を変更することで、レイテンシーと広告の品質とを交換することができます。
オークション / Auction
すべてのリクエストに対して、インプレッションごとのコストの期待値(入札額とエンゲージメント率をかけたもの)を基にしたセカンドプライスオークションを実行します。なお Mopub marketplace でのオークションでは、幾つかのルール・ロジックがオークション前に適用されます。
アドサーバーのレイテンシーと成功率
アドサーバーに送られる各クエリの「価値」は同じではありません。あるクエリは他のクエリより収益を生みやすいことがあります。そのため、処理に失敗した時のコストはクエリによって異なります。また、マッチする広告候補の数に応じて計算負荷も異なります。データを分析することで、以下の強い相関関係があることがわかりました。
処理に時間がかかるクエリは、システムの成功率に影響すると同時に、収益に大きく貢献します。例えば、レイテンシーでソートすると、重い方から 1% のクエリは1% 以上の収益を生むことがわかっています。つまり、ひとつのクエリに対して計算を多くすればするほど、より多くの収益を生むことになります。逆に、処理に時間がかかるクエリがタイムアウトすると、収益に大きなマイナスの影響があると言えます。この分析結果から、システムの成功率を高く保つことは非常に重要であると結論付けることができます。
変数 k を使ってアドサーバーをスケールする
上で書いたように、k を用いると CPU 使用率とレイテンシーをコントロールできます。このことから、各クエリに対して適切に k を決定できれば、k を使ってアドサーバーのクエリ処理能力を拡大・縮小できる、という興味深いアイデアに至りました。
ひとつの方法として、各クエリ処理時の状況(サーバ全体の処理量、使用できる CPU、現在の成功率、ユーザーの特徴)に基づいて、このクエリに適用すべき k の値を予測する、という方針が考えられます。この方法はおもしろそうですが、適切に予測できるモデルを作ることは計算負荷が高く、難しそうです。k を予測するには、外部要因(クエリの急激な増加など)に素早く適応するために複雑なモデルになるでしょうし、そのようなモデル自体の計算負荷は非常に高くなるでしょう。
別の方法として、システムに k を継続的に学習させることが考えられます。このためには、システムの性能を本質的に表し、かつ k を通じて直接的に変更できる測定量を見つける必要があります。この測定量を観測することで、アドサーバーを適切な状態に保つことができます。k がレイテンシーに影響することはわかっているので、成功率(レイテンシーが閾値より小さければ、そのクエリは成功と定義します)を観測して k を適応させる学習システムを構築できると考えました。
このような、成功率に適応する学習プロセスをアドサーバーに実装しました。これは、k の適切な値を学習する制御装置だと言えます。参考までに、基本的な制御装置は、フィードバックループを通じて対象システムの出力と事前に設定した期待値との差分を継続的に計算し、この差分が最小になるように制御変数を変更することで、対象システムが期待値からずれないように制御します(次の図を参照してください)。この考え方を適用してアドサーバーを適切な k で稼働させるために、期待値として目標の成功率(例えば 99.9%)を設定し、この期待値に近づくように k を調整するコントローラを実装しました。
QF: adaptive quality factor(適応型品質係数)
私たちが実装したコントローラは、Quality Factor (品質係数, q)と呼ばれる変数を出力します。この q は、アドサーバーの成功率を期待値に近づけるように作用し、q 自体は次のような簡単なルールに従って変化します。クエリの処理に失敗(タイムアウト)したら、q はある値 δ だけ減少し、成功したら f(δ) だけ増加します。例えば、成功率の期待値が 99.9% だとすると、各クエリの失敗に応じて q を δ だけ減らし、各クエリの成功に応じて q を δ/999 だけ増やします。こうすることで、もしシステムの実際の成功率が期待値 99.9% と等しい状態であれば、1000 件のクエリを通して見たときに、q の変動は無視できるほど小さくなります。δ と f の値は、q がどのくらい素早く適応するかを決定し、適切なチューニングを経て設定されます。
レイテンシーと成功率とは逆相関の関係があるので、成功率の目標をどのように設定しても、それをレイテンシーの目標に変換できます。もし、成功率のある目標値がレイテンシーの目標値 T に変換されたとしたら、システムのレイテンシーが T である限り、q は一定の値になると言えます。レイテンシーが T 以下であれば q は増加し、レイテンシーが T 以上であれば q は減少します。アドサーバーの起動時には q はある初期値に設定され、その後、現在の負荷やレイテンシーの状況に釣り合うように、上記のルールに従って適応します。
Quality Factor を何に使うのか?

上述のように定義した q を用いて、軽量の予測プロセスのあと、k 個の候補ではなく q*k 個の候補を選びます。q はレイテンシーが T になるように収束するので、QPS (query per second 1 秒間のクエリ数)が高いときやフェイルオーバー時などは、q が自動的に適応して減少します。そして、オークションに参加する広告候補が減り、計算負荷が大きいステップが軽くなります(ただし、このとき広告の品質が下がります)。 結果として、レイテンシーが減少し、アドサーバーのクライアントへの成功率は、目標値に一致するように上昇します。重要な点として、通常時には q が 1.0 より高い状態でアドサーバーを運用できることが挙げられます。(DR compliant となるようにプロビジョニングしているので、通常時には必要以上のコンピューティングリソースがあるためです)
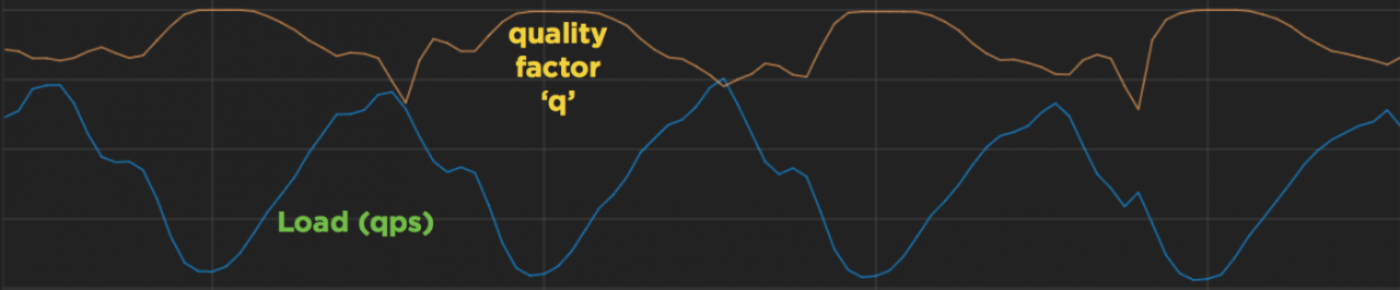
下図は、q が負荷の変動に適応する様子を表したものです(相互作用をわかりやすくするために、2つの曲線ともに適切にスケールしています)。QPS が低いときには q が上昇し、1 クエリあたりの処理量が増えます。QPS のピーク時には、q が下降し、クエリあたり処理量が減少します。この仕組みによって、私たちは CPU を常に最大限活用できるようになりました。
このデザインに関してもう一つの興味深い点は、アドサーバーのインスタンスそれぞれが、最適な q の値を管理していることです。システムの弾力性を各インスタンスが局所的に実現するため、中央集権的な調整は必要ありません。
実際のアドサーバーには、システムの様々なステージの性能を調整可能な複数のパラメターが存在します。これまでに説明した k (軽量予測プロセス後の広告候補の数)はそのひとつに過ぎません。私たちは q を使ってこれらのパラメターを調整し、アドサーバー全体の効率を担保しています。
この記事の最初に、私たちの目標は CPU を効率的に使用することだと述べましたが、Quality Factor を使った手法では、レイテンシーをコントロールすることでこの目標を達成しようとしています。この手法で CPU 使用率を上げるには、まずアドサーバーが CPU バウンドであって、レイテンシーバウンドではないことを保証しなくてはなりません。このため、すべてのオペレーションを非同期に実装したり、ロック競合を減らしたりして、システムを改善しました。
Quality Factor はプロビジョニングにどのように役立つのか?
プロビジョニングの典型的な手法として、負荷の一時的なスパイクを余裕を持って処理できる規模のリソースを割りあて、フェイルオーバー時にも事業を継続する(Disaster Recovery)、という考え方があります。
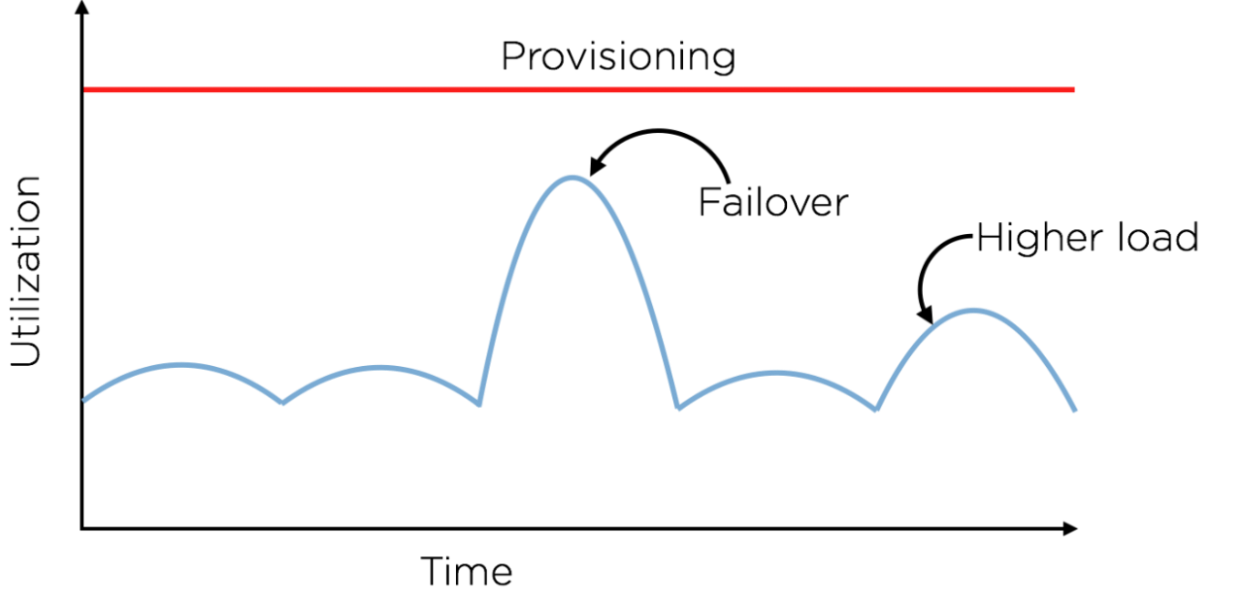
この手法では、通常の運用時にリソースを十分に活用できないため、無駄が多いことは明らかです。リソース使用量を使用可能なリソース量に常に近づけ、かつ負荷のスパイクを吸収できるというのが理想です。(下図の緑色の曲線が、理想的なリソース使用量を表しています)
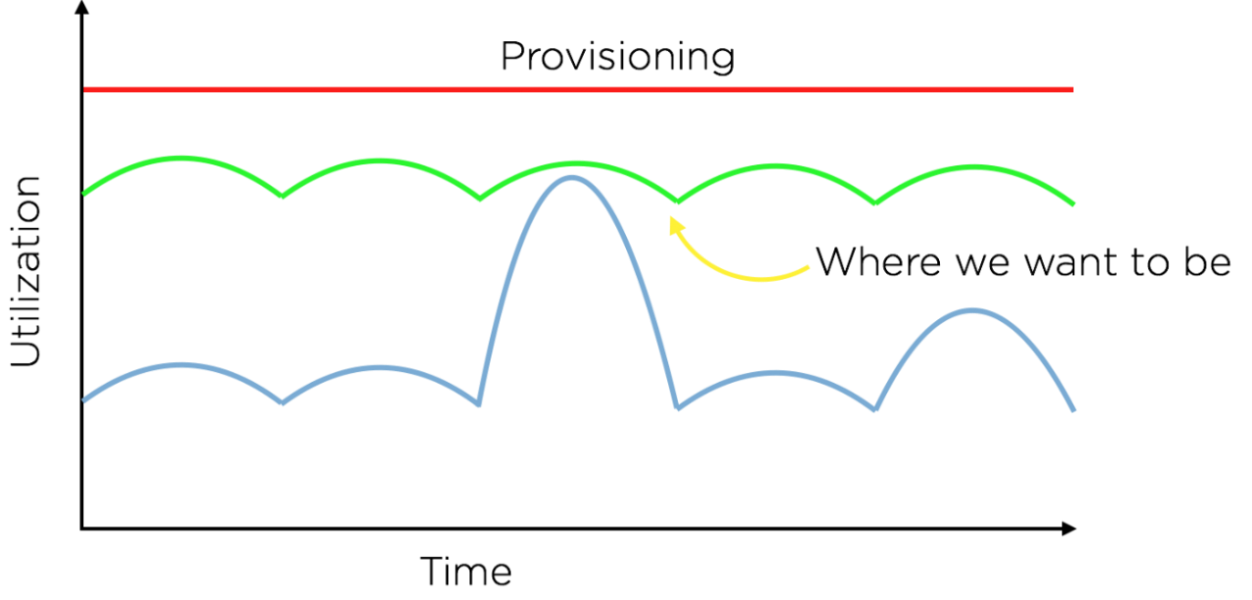
Quality Factor は最適なプロビジョニングを実現するのに役立っています。私たちは、実験を通じて、q の変動が、RPMq* などの主要なパフォーマンスインジケータや、下流のサービスにどのように影響するかを計測しました。(アドサーバーは、クエリを処理する際に、ユーザーデータサービスやその他の key-value store を含むいくつものサービスを呼び出します。従って、アドサーバーのプロビジョニングを変更するときには、これらのサービスへの影響を考慮しなくてはなりません)こうして、望ましいオペレーティングポイントに合わせて、コンピュータリソース量を増減することができます。Quality Factor は、リソース使用量をコントロールするので、どのようなプロビジョニングであっても、システムはリソースを最適に使用することができます。
しかし、この手法にはデメリットもあります。先に触れたとおり、私たちは、リソースを常に最適に使用する能力を得るために、広告品質を代償にしています。簡単に言うと q は広告品質を表すので、サーバーの処理量が多いときには広告品質が一時的に低下します。現実的には、私たちはこのトレードオフは十分に価値があると考えています。
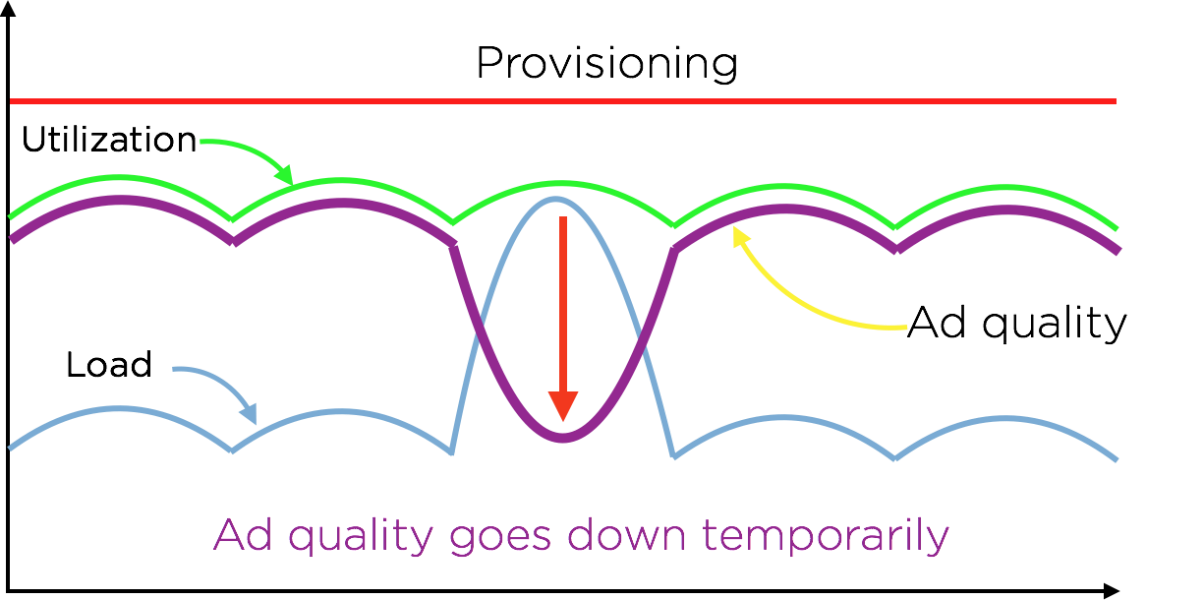
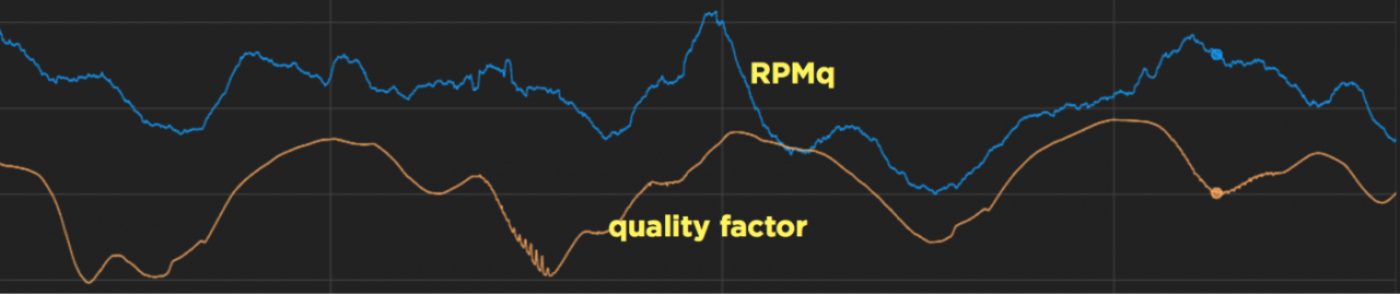
q は CPU 単位時間あたりの収益を表すので、q は収益(正確には RPMq)という観点での現在のパフォーマンスを知る簡単な指標としても活用されています。次のグラフは RPMq と q との強い相関を示しています。
まとめ
この記事では、制御理論のコンセプトを使って、Quality Factor と呼ばれる制御変数を実装したことについて説明しました。この Quality Factor を使って、私たちはアドサーバーの運用目標(弾力性、可用性、スケーラビリティ、リソース使用率、収益の最適化)を達成しています。Quality Factor はTwitter のアドサーバーに多くのメリットをもたらし、オークションにかかる広告候補数をはじめとした、幾つかのパラメターをチューニングするための重要な指標として使われています。また、コンピューティングリソースの追加コストと、それによる収益の増加とを表あする上でも役立っています。
Twitter の ads serving チームは、巨大なスケールがもたらす幾つもの問題に常に挑戦しています。ワールドクラスのシステムを作り上げることに興味があるエンジニアを募集しています!
謝辞
Ads Serving Team: Sridhar Iyer、Rohith Menon、Ken Kawamoto、Gopal Rajpurohit、Venu Kasturi、Pankaj Gupta、Roman Chen、Jun Erh、James Gao、Sandy Strong、Brian Weber
Parag Agrawal からも adaptive quality factor の構想・デザインにおいて助言を得ました。
*RPMq = 1000 クエリあたりの収益
誰か・・・Cookieって言いましたか?
XとそのパートナーはCookieを使用して、より高品質で安全かつ
迅速なサービスを提供しており、また、Cookieの使用は私たちのビジネスを支えています。Cookieの中には、Xのサービスをご利用いただくため、
サービス改善のため、そしてサービスが適切に動作することを確実にするために必要となるものがあります。ユーザーが選択できるオプションの詳細については
あなたの選択肢の詳細を見る。