
Trend detection in social data
Thursday, 16 July 2015
The @Gnip data science team recently drafted a new white paper on trend detection in social data. Trend detection is as equally popular as it is difficult. Technical, analytical and operational hurdles arise that can derail success when working to uncover and understand trends in a way that meets a business or organization’s specific objectives. This new white paper will help you identify, discuss and guide your way through these difficulties.
Trend detection is important to many people and organizations. It makes sense that we would want to know more about what is suddenly increasing in popularity. Knowing what is suddenly increasing in popularity is incredibly important to news organizations, retailers, first responders, government entities and more. At a more specific level, knowledge of trending topics tells us about what people are attracted to, what people think is noteworthy or important and what people make the effort to pass on or share. Armed with that knowledge, businesses can begin to make very effective real-time decisions.
The spread of information through a network of people or other interconnected actors acts like the branching effect of cracks in ice. At each node in the network, the probability of transmission and the number of connections to other nodes determines how fast and how far the information spreads. Despite having mathematical models that describe this process very accurately, it’s still very difficult to identify a trend without prior knowledge of the information content.
The most common way of quantifying a trend (on Twitter, for example) is to look at counts of keywords, mentions or other engagements over a period of time. This is called a time series. Atypical changes in the series can indicate the presence of a trend, but a general definition of “atypical” is hard to develop:
…and how did we know to look at the time series in the first place? After all, there are over a billion Tweets every two days, and a good trend detection algorithm needs to sift through all those activities to identify exactly which time series is of interest.
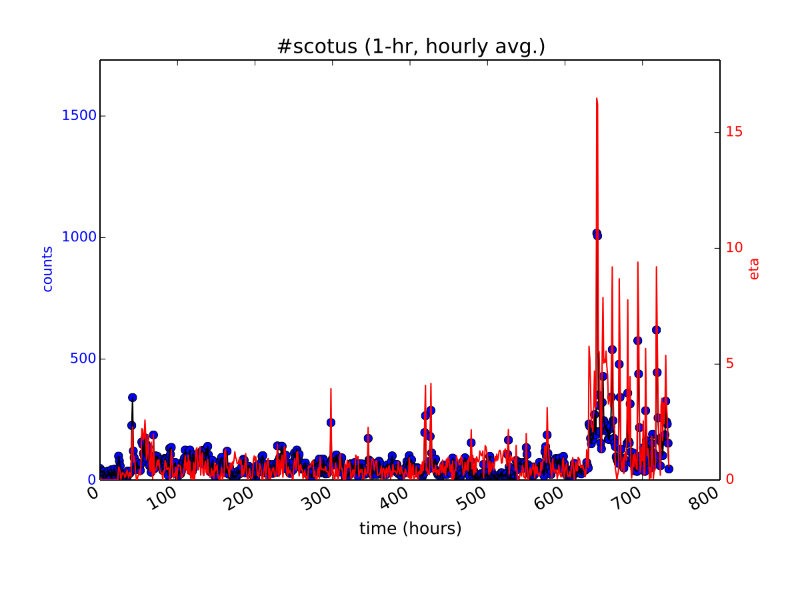 Sample trend figure: Counts of “#scotus” mentions in one-hour time buckets
Sample trend figure: Counts of “#scotus” mentions in one-hour time buckets
A variety of trend detection algorithms have been developed to provide well-motivated mathematical definitions of “atypical” counts. For example, on a point-by-point basis, we know how much variation to expect from nothing more than statistical randomness. We can quantify the deviation of a particular count beyond the expected variability, and we can create a threshold above which we call the count (or series of counts) a “trend.”
We can do even better by incorporating information from the recent time series history into the expected count. This provides a better estimate of the random variability, and it allows us to account for changes in counts that are real but expected — such as changes due to time-of-day or time-of-week. When we maintain a continuous history of counts, we can use a different technique in which we ask how much the time series looks like historical trends or like normal, non-trending data.
To describe the performance of a trend-detection algorithm, we can use metrics like precision and recall as defined in the white paper. These indicate how many fake trends were identified and how many real trends were missed. We are also interested in time-to-detection, or how quickly after its start a real trend was identified. We can vary the performance of the detection system by changing the parameters of the particular algorithm.
It’s important to remember that there is no single, best trend-detection algorithm. All algorithms present tradeoffs, including simplicity vs. robustness, precision, recall and time-to-detection. A good choice of algorithm and performance goals is always driven by your specific product needs, business values and organizational constraints. For example, a marketing team looking for popular words used around their products may be content to sift through many fake trends so long as they’re very likely to uncover a real trend, should it occur. In contrast, a business needing to make fast supply-chain management decisions might prioritize short time-to-detection and high precision trend alerting.
For even more details, download this white paper. We’ve also included sample code in the GitHub repository that implements some of the algorithms discussed in the paper to help you get started with trend detection today.
If you’re interested in learning how one of our Twitter Official Partners uses trend detection, check out how Networked Insights (@NetInsights) deploys trend detection in their product. You can also see the type of events that DataMinr (@DataMinr) can detect using trend detection.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.