
TSAR, a TimeSeries AggregatoR
Friday, 27 June 2014
Twitter is a global real-time communications platform that processes many billions of events every day. Aggregating these events in real time presents a massive challenge of scale. Classic time-series applications include site traffic, service health, and user engagement monitoring; these are increasingly complemented by a range of analytics products and features such as Tweet activity, Followers, and Twitter Cards that surface aggregated time-series data directly to end users, publishers, and advertisers. Services that power such features need to be resilient enough to ensure a consistent user experience, flexible enough to accommodate a rapidly changing product roadmap, and able to scale to keep up with Twitter’s ever growing user base.
Our experience demonstrates that truly robust real-time aggregation services are hard to build; that scaling and evolving them gracefully is even harder; and moreover, that many time-series applications call for essentially the same architecture, with only slight variations in the data model. Solving this broad class of problems at Twitter has been a multi-year effort. A previous post introduced Summingbird, a high-level abstraction library for generalized distributed computation, which provides an elegant descriptive framework for complex aggregation problems.
In this post, we’ll describe how we built a flexible, reusable, end-to-end service architecture on top of Summingbird, called TSAR (the TimeSeries AggregatoR). We’ll explore the motivations and design choices behind TSAR and illustrate how it solves a particular time-series problem: counting Tweet impressions.
The Tweet impressions problem in TSAR
Let’s suppose we want to annotate every Tweet with an impression count - that is, a count representing the total number of views of that Tweet, updated in real time. This innocent little feature conceals a massive problem of scale. Although “just” 500 million Tweets are created each day, these Tweets are then viewed tens of billions of times. Counting so many events in real time is already a nontrivial problem, but to harden our service into one that’s fit for production we need to answer questions like:
Most important:
TSAR addresses these problems by following these essential design principles:
Let’s write some code!
Production requirements continually change at Twitter, based on user feedback, experimentation, and customer surveys. Our experience has shown us that keeping up with them is often a demanding process that involves changes at many levels of the stack. Let us walk through a lifecycle of the impression counts product to illustrate the power of the TSAR framework in seamlessly evolving with the product.
Here is a minimal example of a TSAR service that counts Tweet impressions and persists the computed aggregates in Manhattan (Twitter’s in-house key-value storage system):
aggregate {
onKeys(
(TweetId)
) produce (
Count
) sinkTo (Manhattan)
} fromProducer {
ClientEventSource(“client_events”)
.filter { event => isImpressionEvent(event) }
.map { event =>
val impr = ImpressionAttributes(event.tweetId)
(event.timestamp, impr)
}
}
The TSAR job is broken into several code sections:
Seamless schema evolution
We now wish to change our product to break down impressions by the client application (e.g., Twitter for iPhone, Android, etc.) that was used to view the Tweet. This requires us to evolve our job logic to aggregate along an additional dimension. TSAR simplifies this schema evolution:
aggregate {
onKeys(
(TweetId)
(TweetId, ClientApplicationId) // new aggregation dimension
) produce (
Count
) sinkTo (Manhattan)
}
Backfill tooling
Going forward, the impression counts product will now break down data by client application as well. However, data generated by prior iterations of the job does not reflect our new aggregation dimension. TSAR makes backfilling old data as simple as running one backfill command:
$ tsar backfill --start=<start> --end=<end>
The backfill then runs in parallel to the production job. Backfills are useful to repair bugs in the aggregated data between a certain time range, or simply to fill in old data in parallel to a production job that is computing present data.
Simplify aggregating data on different time granularities
Our impression counts TSAR job has been computing daily aggregates so far, but now we wish to compute all-time aggregates. TSAR uses a custom configuration file format, where you can add or remove aggregation granularities with a single line change:
Output(sink = Sink.Manhattan, width = 1 * Day) Output(sink = Sink.Manhattan, width = Alltime) // new aggregation granularity
The user specifies whether he/she wants minutely, hourly, daily or alltime aggregates and TSAR handles the rest. The computational boilerplate of event aggregation (copying each event into various time buckets) is abstracted away.
Automatic metric computation
For the next version of the product, we can even compute the number of distinct users who have viewed each Tweet, in addition to the total impression count - that is, we can compute a new metric. Normally, this would require changing the job’s aggregation logic. However, TSAR abstracts away the details of metric computation from the user:
aggregate {
onKeys(
(TweetId),
(TweetId, ClientApplicationId)
) produce (
Count,
Unique(UserId) // new metric
) sinkTo (Manhattan)
}
TSAR provides a built-in set of core metrics that the user can specify via configuration options (such as count, sum, unique count, standard deviation, ranking, variance, max, min). However, if a user wishes to aggregate using a new metric (say exponential backoff) that TSAR does not support as yet, the user can can easily add it.
Automatic support for multiple sinks
Additionally, we can export aggregated data to new output sinks like MySQL to allow for easy exploration. This is also a one-line configuration change:
Output(sink = Sink.Manhattan, width = 1 * Day) Output(sink = Sink.Manhattan, width = Alltime) Output(sink = Sink.MySQL, width = Alltime) // new sink
TSAR infers and defines the key-value pair data models and relational database schema descriptions automatically via a job-specific configuration file. TSAR automates Twitter best practices using a general-purpose reusable aggregation framework. Note that TSAR is not tied to any specific sink. Sinks can easily be added to TSAR by the user, and TSAR will transparently begin persisting aggregated data to these sinks.
Operational simplicity
TSAR provides the user with an end-to-end service infrastructure that you can deploy with a single command:
$ tsar deploy
In addition to simply writing the business logic of the impression counts job, one has to build infrastructure to deploy the Hadoop and Storm jobs, build a query service that combines the results of the two pipelines, and deploy a process to load data into Manhattan and MySQL. A production pipeline requires monitoring and alerting around its various components along with checks for data quality.
In our experience, the operational burden of building an entire analytics pipeline from scratch and managing the data flow is quite cumbersome. These parts of the infrastructure look very similar from pipeline to pipeline. We noticed common patterns between the pipelines we built before TSAR and abstracted it all away from the user into a managed framework.
A bird’s eye view of the TSAR pipeline looks like:
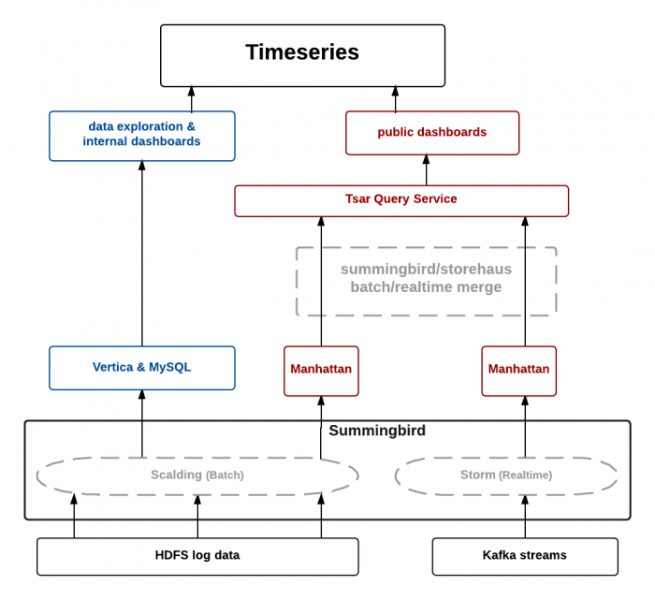
Now let’s bring the various components of our updated TSAR service together. You will see that the updated TSAR service looks almost exactly like the original. However, the data produced by this version of the TSAR service aggregates along additional event dimensions and along more time granularities and writes to an additional data store. The TSAR toolkit and service infrastructure simplify the operational aspects of this evolution as well. The final TSAR service fits into three small files:
ImpressionCounts: Thrift schema
enum Client
{
iPhone = 0,
Android = 1,
...
}
struct ImpressionAttributes
{
1: optional Client client,
2: optional i64 user_id,
3: optional i64 tweet_id
}
ImpressionCounts: TSAR service
object ImpressionJob extends TsarJob[ImpressionAttributes] {
aggregate {
onKeys(
(TweetId),
(TweetId, ClientApplicationId)
) produce (
Count,
Unique(UserId)
) sinkTo (Manhattan, MySQL)
} fromProducer {
ClientEventSource(“client_events”)
.filter { event => isImpressionEvent(event) }
.map { event =>
val impr = ImpressionAttributes(
event.client, event.userId, event.tweetId
)
(event.timestamp, impr)
}
}
}
ImpressionCounts: Configuration file
Config(
base = Base(
user = "platform-intelligence",
name = "impression-counts",
origin = "2014-01-01 00:00:00 UTC",
primaryReducers = 1024,
outputs = [
Output(sink = Sink.Hdfs, width = 1 * Day),
Output(sink = Sink.Manhattan, width = 1 * Day),
Output(sink = Sink.Manhattan, width = Alltime),
Output(sink = Sink.MySQL, width = Alltime)
],
storm = Storm(
topologyWorkers = 10,
ttlSeconds = 4.days,
),
),
)
The information contained in these three files (thrift, scala class, configuration) is all that the user needs to specify in order to deploy a fully functional service. TSAR fills in the blanks:
The end-to-end management of the data pipeline is TSAR’s key feature. The user concentrates on the business logic.
Looking ahead
While we have been running TSAR in production for more than a year, it is still a work in progress. The challenges are increasing and the number of features launching internally on TSAR is growing at rapid pace. Pushing ourselves harder to be better and smarter is what drives us on the Platform Intelligence team. We wish to grow our business in a way that makes us proud and do what we can to make Twitter better and our customers more successful.
Acknowledgments
Among the many people who have contributed to TSAR (far too many to list here), I especially want to thank Aaron Siegel, Reza Lotun, Ryan King, Dave Loftesness, Dmitriy Ryaboy, Andrew Nguyen, Jeff Sarnat, John Chee, Eric Conlon, Allen Chen, Gabriel Gonzalez, Ali Alzabarah, Zongheng Yang, Zhilan Zweiger, Kevin Lingerfelt, Justin Chen, Ian Chan, Jialie Hu, Max Hansmire, David Marwick, Oscar Boykin, Sam Ritchie, Ian O’Connell … And special thanks to Raffi Krikorian for conjuring the Platform Intelligence team into existence and believing that anything is possible.
If this sounds exciting to you and you’re interested in joining the Platform Intelligence team to work on Tsar, we’d love to hear from you!
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.