Infrastructure
Building DistributedLog: High-performance replicated log service
By
Wednesday, 16 September 2015
At Twitter, we’ve used replicated logs to address a range of challenging problems in distributed systems. Today we’d like to tell you about DistributedLog, our high-performance replicated log service, and how we used it to address one of these problems.
Last year, we provided an in-depth look at Manhattan, Twitter’s distributed key-value database. Manhattan provides a flexible, eventually-consistent data model that allows users to trade consistency for latency in the read path. Writes are applied to all replicas of a dataset independently, and the system guarantees that eventually all replicas will end up with the same data. As a result, applications that query a recently updated dataset may for a brief period read different values from different replicas. Applying updates that depend on a current value can be tricky with an eventually consistent data model. For example, consider a simple operation like compare-and-set. To implement compare-and-set, we first need to query the current value, then check whether it equals some expected value, and if it does, write a new value. If replicas are in different states when this operation is applied, the results will be different and we’ll end up with inconsistent data.
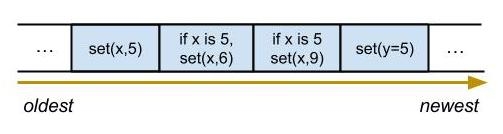
To prevent these inconsistencies, we must apply all updates in the same order at each replica. A simple way to sequence updates is to use a log‐a strictly-ordered, append-only sequence of records or operations [1]. If each compare-and-set operation is written once to a log data structure, and each replica is able to read the log (i.e. the log is replicated or accessible over the network), then we’ll be able to ensure that applying the compare-and-set operation at each replica will always produce the same result.
At Twitter, we’ve encountered applications like the example above with a need for some kind of log-service infrastructure. Logs are a building block of distributed systems and once you understand the basic pattern you start to see applications for them everywhere.
Requirements for a log service
Through our experience building distributed systems at Twitter, we’ve identified the following requirements for any replicated log service capable of underpinning our most critical infrastructure and applications:
To meet these needs we considered several options, including using a pub/sub system like Kafka, building a new service or library using a consensus algorithm like Paxos or Raft, or using a lower-level log service like Apache BookKeeper. At design time we had concerns about Kafka’s I/O model and its lack of strong durability guarantees‐a non-starter for an application like a distributed transaction log [3]. Raft and Paxos were appealing, but building a brand new system would have required a longer development cycle.
That leaves Apache BookKeeper, a service originally envisioned as a transaction log backend for HDFS. In the next section we’ll explore the key features of BookKeeper and explain why we chose to use it as the foundation for DistributedLog.
Why build on top of BookKeeper?
BookKeeper is a low-level log service in the sense that its sole concern is efficient storage and retrieval of log segments, called Ledgers. Unlike Kafka, BookKeeper is not concerned with some of the higher-level features typically found in a full-fledged pub/sub system, including partition ownership, stream-oriented abstractions, or naming and metadata. Its core strengths are flexible built-in replication, excellent performance for log workloads, and ease of operations.
Flexible built-in replication
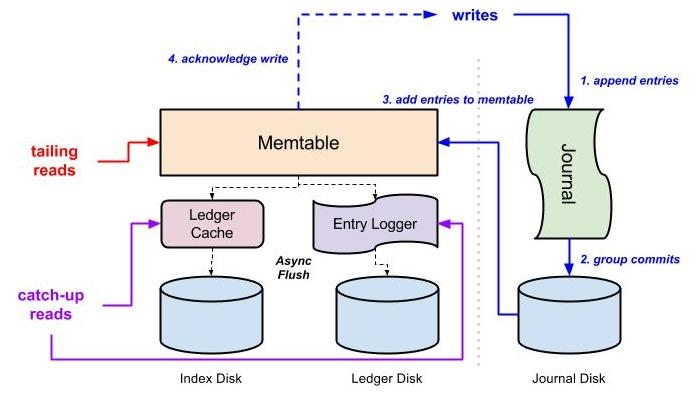
BookKeeper’s quorum-based replication mechanism is driven directly by the client, avoiding the added latency of a primary-secondary replication scheme. The quorum-based replication mechanism helps us mask issues with slow or failing servers when reading or writing data, allowing us to achieve predictable low latency. The replication settings are highly configurable and support pluggable replica placement policies (which enable things like geo-replication).
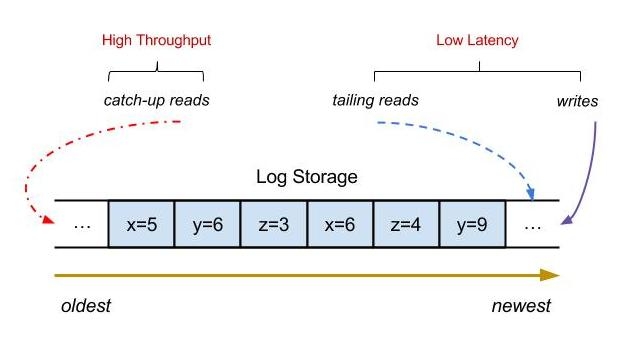
I/O performance
BookKeeper nodes deliver excellent I/O performance by leveraging different I/O components to handle each of the core log storage workloads discussed above:
With good I/O isolation BookKeeper nodes achieve predictable low latency under high throughput trafficand guarantee durability.
From BookKeeper to a distributed log service
BookKeeper is a great choice for log storage. So that’s it, we’re done, right? We can hook up our distributed systems at Twitter to BookKeeper and call it a day? Not quite. BookKeeper satisfies several of the most critical requirements outlined above but leaves us with a few important gaps, including things like higher-level abstractions, log ownership, and other features to aid usability, reuse, and reliability.
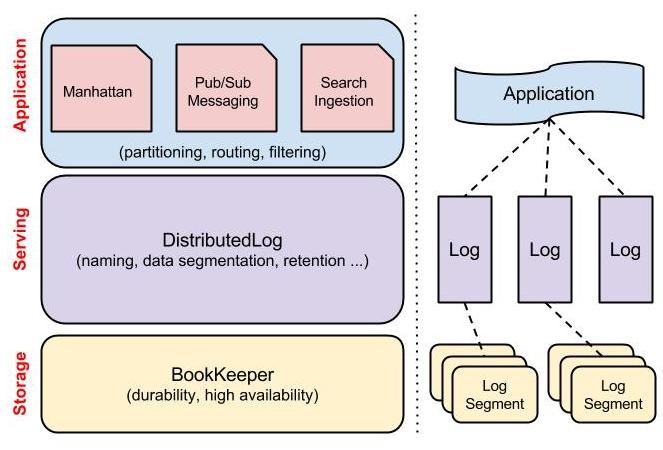
In this section we describe DistributedLog, a serving layer that we built on top of BookKeeper to provide an end-to-end log service satisfying the requirements above. The complete DistributedLog stack is illustrated in Figure 4. BookKeeper is responsible for durable, highly-available log-segment storage. Above BookKeeper, DistributedLog is the serving layer, providing simple abstractions over log-segments such as naming, data segmentation, and retention policies. Above DistributedLog, the application is responsible for higher-level features such as partitioning, routing, and offset-management.
Key features of DistributedLog
What does DistributedLog offer on top of BookKeeper? Let’s begin with a list of the most critical features:
Stream-oriented abstractions
DistributedLog exposes just a few simple entities, illustrated in Figure 4 above. For the most part, users only have to worry about appending to a named stream object (“Log” in the DistributedLog API)‐the details of BookKeeper Ledger management are completely hidden.
Naming and metadata
BookKeeper exposes numbered ledgers, but to be useful in a large organization as a reusable service, we need to provide a simple addressing and naming scheme for Logs. DistributedLog provides a persistent naming and metadata scheme so that users can think in terms of named logs or topics instead of sets of numbered ledgers.
Log ownership scheme
Fundamentally a log is an ordered sequence of records, and in any log service a single writer must eventually be responsible for sequencing writes to a log, a role sometimes referred to as mastership. BookKeeper does not enforce a particular mastership scheme so DistributedLog implements a ZooKeeper-based scheme of its own.
Data management policies
Some applications may wish to age out data after a certain period, and some must retain careful control over exactly how data is truncated (in the Manhattan transaction log use case for example). DistributedLog provides knobs for tuning data retention for a wide variety of use cases. DistributedLog also provides control over how Logs are broken up into segments which helps balance data distribution across storage nodes.
Tuneable read and write pipelines
DistributedLog provides a highly-tuneable batching mechanism in the write path. Applications can trade latency for throughput by flushing periodically, immediately, or once the write buffer reaches a certain size. In the read path, we provide a tuneable read-ahead mechanism which ensures data is always available when needed, using an efficient long-poll mechanism which we added to the BookKeeper API.
Service layer for efficient fan-in and fan-out
DistributedLog introduces a service layer optimized for running in a multi-tenant datacenter environment such as Twitter’s Mesos-based cluster runtime. The DistributedLog service layer allows us to support applications which don’t care about log ownership by aggregating writes from many sources. The service tier also helps us optimize the read path by caching log data in cases where hundreds or thousands of readers are consuming the same stream.
Geo-replicated logs
Using the the log ownership scheme described above, and building on BookKeeper’s flexible replication model, DistributedLog additionally supports geo-replicated logs. Geo-replicated logs guarantee availability across multiple datacenters, even in the event of total datacenter failure. This feature is used extensively by Manhattan’s consistent write mechanism to support globally consistent writes across DCs.
DistributedLog at Twitter
The feature set above has evolved through the successful deployment of DistributedLog to solve a number of challenging distributed systems problems at Twitter in the last two years. In this section we circle back to the problem of implementing compare-and-set in Manhattan, and explain how we successfully deployed DistributedLog to implement a low-latency, highly-available transaction log.
Compare-and-set in Manhattan
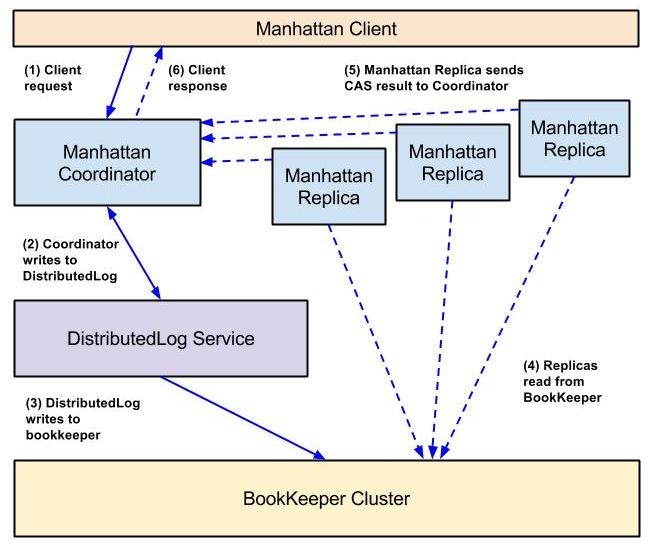
Recall from the introduction that to support compare-and-set in Manhattan we decided to use DistributedLog to order updates to all replicas of a dataset. By first writing all updates to a log, and then having each replica read and apply those updates in order, we are able to ensure that a compare-and-set operation will leave all replicas in the same state. Execution of a compare-and-set operation proceeds according to the following steps.
Performance and results
Using the various tuning mechanisms discussed above, the DistributedLog-based consistent write path has proven to be highly reliable and offers impressive performance. Introducing DistributedLog to the Manhattan write path adds just 10ms to write latency on average, with the 99.9th percentile at 20ms.
What’s next?
We would like to collaborate and share our experiences with the BookKeeper community as well as other messaging communities in order to further develop these ideas. Our first step towards doing this will be to host a Messaging User Group meetup on Sept. 21 at Twitter HQ. At this event, we’ll share more details about our motivations for designing DistributedLog, the system’s features and performance, and how we’re using it at Twitter.
Acknowledgements
This post was co-authored by Sijie Guo. DistributedLog would not have been possible without the hard work of Robin Dhamankar, Sijie Guo, Leigh Stewart, Aniruddha Laud, Franck Cuny, Mike Lindsey, David Helder, Vishnu Challam, Amit Shukla, and Rob Benson.
We would also like to thank the BookKeeper community for teaching us numerous lessons and for moving the state of distributed logging forward.
References
[1] For a great post on the role of logs in modern distributed systems architecture, see Jay Kreps’ The Log: What every software engineer should know about real-time data’s unifying abstraction
[2] For an example of using Paxos to build a distributed database see Spanner; for Raft see CockroachDB.
[3] Kafka addressed these durability concerns in version 0.8
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.