Infrastructure
The Infrastructure Behind Twitter: Scale
By
Thursday, 19 January 2017
Twitter came of age when hardware from physical enterprise vendors ruled the data center. Since then we’ve continually engineered and refreshed our fleet to take advantage of the latest open standards in technology and hardware efficiency in order to deliver the best possible experience.
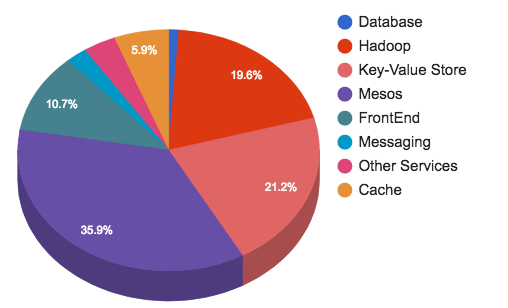
Our current distribution of hardware is shown below:
We started to migrate from third party hosting in early 2010, which meant we had to learn how to build and run our infrastructure internally, and with limited visibility into the core infrastructure needs, we began iterating through various network designs, hardware, and vendors.
By late 2010, we finalized our first network architecture which was designed to address the scale and service issues we encountered in the hosted colo. We had deep buffer ToRs to support bursty service traffic and carrier grade core switches with no oversubscription at that layer. This supported the early version of Twitter through some notable engineering achievements like the TPS record we hit during Castle in the Sky and World Cup 2014.
Fast forward a few years and we were running a network with POPs on five continents and data centers with hundreds of thousands of servers. In early 2015 we started experiencing some growing pains due to changing service architecture and increased capacity needs, ultimately reaching physical scalability limits in the data center when a full mesh topology would not support additional hardware needed to add new racks. Additionally, our existing data center IGP began to behave unexpectedly due to this increasing route scale and topology complexity.
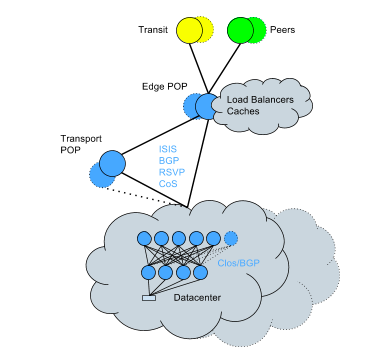
To address this, we started to convert existing data centers to a Clos topology + BGP – a conversion which had to be done on a live network, yet, despite the complexity, was completed with minimal impact to services in a relatively short time span. The network now looks like this:
Highlights of the new approach:
Let’s expand on our network infrastructure below.
Our first data center was built by modeling the capacity and traffic profiles from the known system in the colo. But just a few years later, our data centers are now 400% larger than the original design. And now, as our application stack has evolved and Twitter has become more distributed, traffic profiles have changed as well. The original assumptions that guided our early network designs no longer held true.
Our traffic grows faster than we can re-architect an entire datacenter so it’s important to build a highly scalable architecture that will allow adding capacity incrementally instead in forklift-esque migrations.
High fanout microservices demand a highly reliable network that can handle a variety of traffic. Our traffic ranges from long lived TCP connections to ad hoc mapreduce jobs to incredibly short microbursts. Our initial answer to these diverse traffic patterns was to deploy network devices that featured deep packet buffers but this came with its own set of problems: higher cost and higher hardware complexity. Later designs used more standard buffer sizes and cut-through switching features alongside a better-tuned TCP stack server-side to more gracefully handle microbursts.
Over the years and through these improvements, we’ve learned a few things worth calling out:
Our backbone traffic has grown dramatically year over year – and we still see bursts of 3-4X of normal traffic when moving traffic between datacenters. This creates unique challenges for historical protocols that were never designed to deal with this such as the MPLSRSVP protocol where it assumes some form of a gradual ramp-up, not sudden bursts. We have had to spend extensive time tuning these protocols in order to gain the fastest possible response times. Additionally, to deal with with traffic spikes (storage replication in particular) we have implemented prioritization. While we need to guarantee delivery of customer traffic at all times, we can afford to delay delivery of low-priority storage replication jobs that have a days long SLA. This way, our network uses all available capacity and makes the most possible efficient use of resources. Customer traffic is always more important than low-priority backend traffic. Further, to solve the bin-packing issues that come with RSVP auto-bandwidth, we have implemented TE++, which, as traffic increases, creates additional LSPs and removes them when traffic drops off. This allows us to efficiently manage traffic between links while reducing the CPU burden of maintaining large amounts of LSPs.
While originally the backbone lacked any form of traffic engineering, it’s been added to help us scale according to our growth. To aid this we’ve completed a separation of roles in order to have separate routers dedicated to core and edge routing respectively. This has also allowed us to scale in a cost effective manner as we haven’t had to buy routers with complicated edge functionality.
At the edge this means we have a core to connect everything through and are able to scale in a very horizontal manner (i.e. have many, many routers per site, rather than only a couple , as we have a core layer to interconnect everything through).
In order to scale the RIB in our routers, we’ve had to introduce route reflection to meet our scale demands, but in doing this, and moving to a hierarchical design, we made also made the route reflectors clients of their own route reflectors!
Over the last year we’ve migrated device configurations into templates and are now regularly auditing them.
Twitter’s worldwide network directly interconnects with over 3,000 unique networks in many datacenters worldwide. Direct traffic delivery is our first priority. We haul 60% of our traffic over our global network backbone to interconnection points and POPs where we have local front-end servers terminating client sessions, all in order to be as close as possible to the customer.
World events that are impossible to predict result in equally unpredictable burst traffic. These bursts during large events such as sports, elections, natural disasters, and other newsworthy events stress our network infrastructure (particularly photo and video) with little to no advance notice. We provision capacity for these events and plan for large utilization spikes - often 3-10x normal peaks when we have major events upcoming in a region. Because of our significant year over year traffic growth, keeping up with capacity can be a real challenge.
While we peer wherever possible with all of our customers networks, this doesn’t come without it’s challenges. Surprisingly often, networks or providers prefer to interconnect away from home markets, or, due to their routing policies, cause traffic to arrive in POPs that are out of markets. And while Twitter openly peers with all major eyeball (customers) networks we see traffic on, not all ISPs do. We spend a significant amount of time optimizing our routing policies to serve traffic as close to our users and as directly as possible.
Historically, when someone requested “www.twitter.com”, based on the location of their DNS server, we would pass them different regional IPs to map them to a specific cluster of servers. This methodology, “GeoDNS”, is partially inaccurate due to the fact that we cannot rely on users to map to the correct DNS servers, or on our ability to detect where DNS servers are physically located in the world. Additionally, the topology of the internet does not always match geography.
To solve this we have moved to a “BGP Anycast” model where we announce the same route from all locations and optimize our routing to take the best paths from customers to our POPs. By doing this we get the best possible performance within the constraints of the topology of the internet and don’t have to rely on unpredictable assumptions about DNS servers exist.
Hundreds of millions of Tweets are sent every day. They are processed, stored, cached, served and analyzed. With such massive content, we need a consequent infrastructure. Storage and messaging represents 45% of Twitter’s infrastructure footprint.
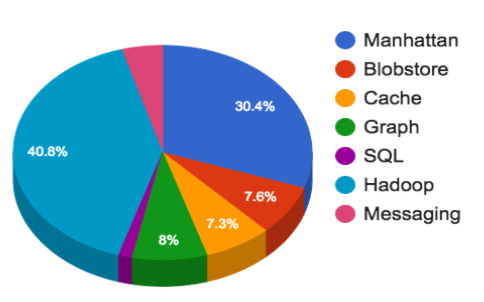
The storage and messaging teams provide the following services:
While there are a number of different challenges at this scale multi-tenancy is one of the more notable ones we’ve had to overcome. Often customers have corner cases that would impact existing tenants and force us to build dedicated clusters. More dedicated clusters increases the operational workload to keep things running.
There are no surprises in our infrastructure but some of the interesting bits are as follows:
Hadoop/HDFS is also the backend to our Scribe-based log pipeline, but in the final testing phases of the transition to Apache Flume as a replacement in order to address limitations like a lack of rate limiting/throttling of selective clients to aggregators, lack of delivery guarantee for categories, and to solve memory corruption issues. We handle over a trillion messages per day and all of these are processed into over 500 categories, consolidated and then and selectively copied across all our clusters.
Twitter was built on MySQL and originally all data was stored on it. We went from a small database instance to a large one, and eventually many large database clusters. Manually moving data across MySQL instances requires a lot of time consuming hands on work, so in April 2010 we introduced Gizzard – a framework for creating distributed datastores.
The ecosystem at the time was:
Following the release of Gizzard in May 2010, we introduced FlockDB, a graph storage solution on top of Gizzard and MySQL, and in June 2010, Snowflake our unique identifier service. 2010 was also when we invested in Hadoop. Originally intended to store MySQL backups, it now is heavily used for analytics.
Around 2010, we also added Cassandra as a storage solution, and while it didn’t fully replace MySQL due to it’s lack of an auto-increment feature, it did gain adoption as a metrics store. As traffic was growing exponentially we needed to grow the cluster, and, in April 2014 we launched Manhattan: our real-time, multi-tenant distributed database. Since then Manhattan has become one of our most common storage layers and Cassandra has been deprecated.
In December 2012, Twitter released a feature to allow native photo uploads. Behind the scenes, this was made possible by a new storage solution Blobstore.
Over the years, as we’ve migrated data from MySQL to Manhattan to take advantage of better availability, lower latency, and easier development, we’ve also adopted additional storage engines (LSM, b+tree…) to better serve our traffic patterns. Additionally, we’ve learned from incidents and have started protecting our storage layers from abuse by sending a back pressure signal and enabling query filtering.
We continue to be focused on providing the right tool for the job, but this means legitimately understanding all possible use cases. A “one size fits all” solution rarely works — avoid building shortcuts for corner cases as there is nothing more permanent than a temporary solution. Lastly, don’t oversell a solution. Everything has pros and cons and needs to be adopted with a sense of realism.
While Cache is ~3% of our infrastructure, it is critical for Twitter. It protects our backing stores from heavy read traffic and allows for storing objects which have heavy hydration costs. We use a few cache technologies, like Redis and Twemcache, at enormous scale. More specifically, we have a mix of dedicated and multi-tenant Twitter memcached (twemcache) clusters as well as Nighthawk (sharded Redis) clusters. We have migrated nearly all of our main caching to Mesos from bare metal to lower operational cost.
Scale and performance are the primary challenges for Cache. We operate hundreds of clusters with an aggregate packet rate of 320M packets/s, delivering over 120GB/s to our clients, and we aim to deliver each response with latency constraints into the 99.9th and 99.99th percentiles even under event spikes.
To meet our high-throughput and low-latency service level objectives (SLOs) we need continually measure the performance of our systems and look for efficiency optimizations. To help us do this we wrote rpc-perf to get a better understanding of how our cache systems perform. This was crucial in capacity planning as we migrated from dedicated machines to our current Mesos infrastructure. As a result of these optimization efforts we’ve more than doubled our per-machine throughput with no change in latency. We still believe there are large optimization gains to be had.
Moving to Mesos was a huge operational win. We codified our configurations and can deploy slowly to preserve hit-rate and avoid causing pain for persistent stores as well as grow and scale this tier with higher confidence.
With thousands of connections per twemcache instance, any process restarts, network blips, and other issues could trigger a DDoS-esque connect attacks against the cache tier. As we’ve scaled, this has become more of an issue, and through benchmarking we’ve implemented uptakes rules to throttle connections to each cache individually when high reconnect rates would otherwise cause us to violate our SLOs.
We logically partition our caches by users, Tweets, timelines, etc. and in general, every cache cluster is tuned for a particular need. Based on the type of the cluster, they handle between 10M to 50M QPS, and run between hundreds to thousands of instances.
Allow us to introduce Haplo. It is the primary cache for Tweet timelines and is backed by a customized version of Redis (implementing the HybridList). Haplo is read-only from Timeline Service and written to by Timeline Service and Fanout Service. It is also one of our few cache services that we have not migrated to Mesos yet.
Yao Yue (@thinkingfish) has made several great talks and papers about cache over the years, including on our use of Redis, as well as our newer Pelikan codebase. Feel free to check out the videos and a recent blog post
We run a wide array of core infrastructure services such as Kerberos, Puppet, Postfix, Bastions, Repositories and Egress Proxies. We are focused on scaling, building tooling, managing these services, as well as supporting data center and point-of-presence (POP) expansion. Just this past year we significantly expanded our POP infrastructure to many new geo locations which required a complete re-architecture of how we plan, bootstrap, and launch new locations.
We use Puppet for all configuration management and post kickstart package installation of our systems. This section details some of the challenges we have overcome and where we are headed with our configuration management infrastructure.
In growing to meet the needs of our users, we quickly outgrew standard tools and practices. We have over 100 committers per month, over 500 modules, and over 1,000 roles.Ultimately, we have been able to reduce the number of roles, modules, and lines of code all while improving the quality of our codebase.
We have three branches which Puppet refers to as environments. These allow us to properly test, canary, and eventually push changes to our production environment. We do allow for custom branches too, for more isolated testing.
Moving changes from testing through to production currently requires a bit of manual handholding, but we are moving towards a more automated CI system with an automated integration/backout process.
Our Puppet repository contains greater than 1 million lines of code with just the Puppet code being more than 100,000 per branch. We have recently undergone a massive effort to cleanup our codebase reducing dead and duplicate code.
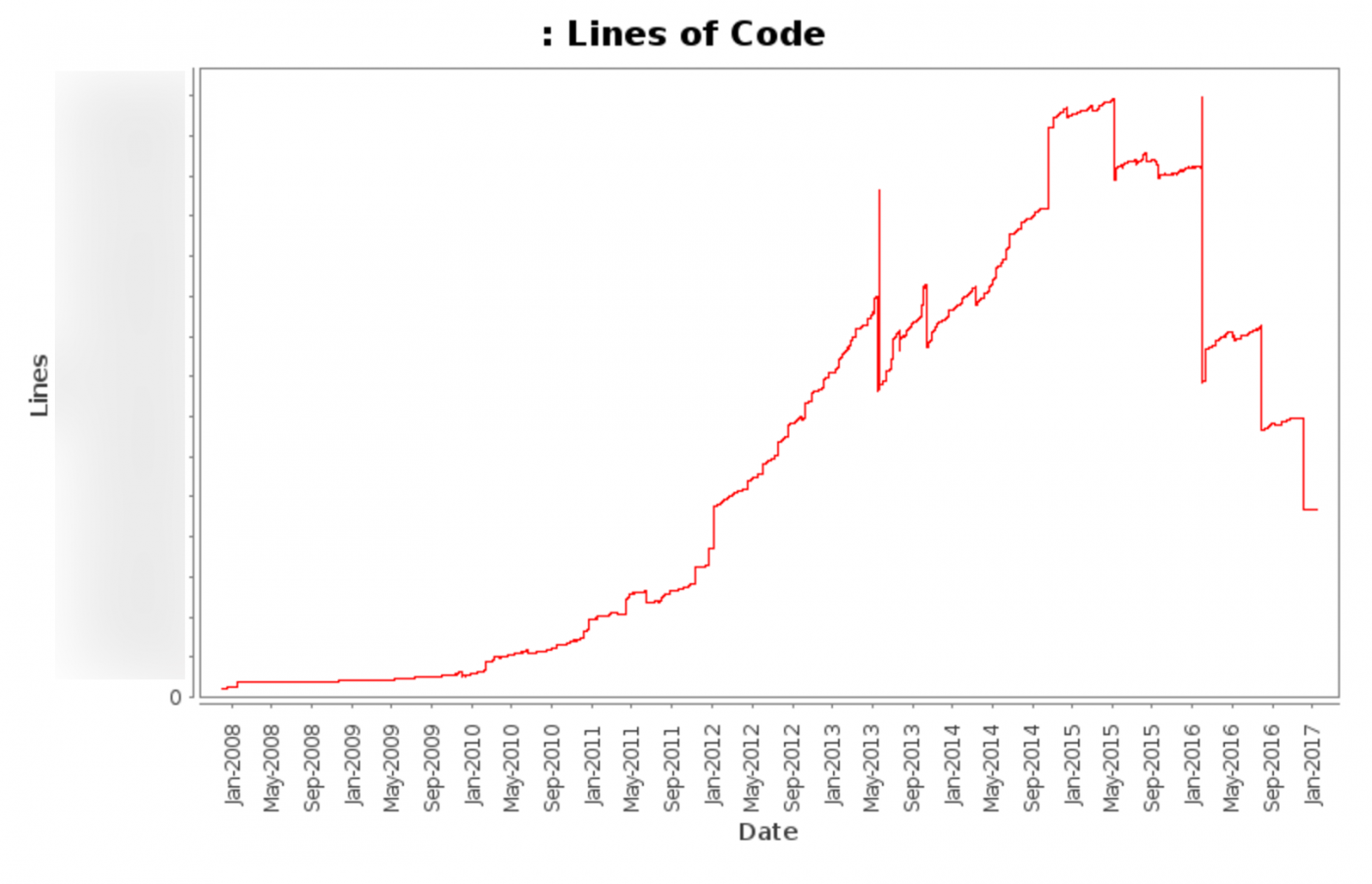
This graph shows our total lines of code (not including various automatically updated files) from 2008 to today.
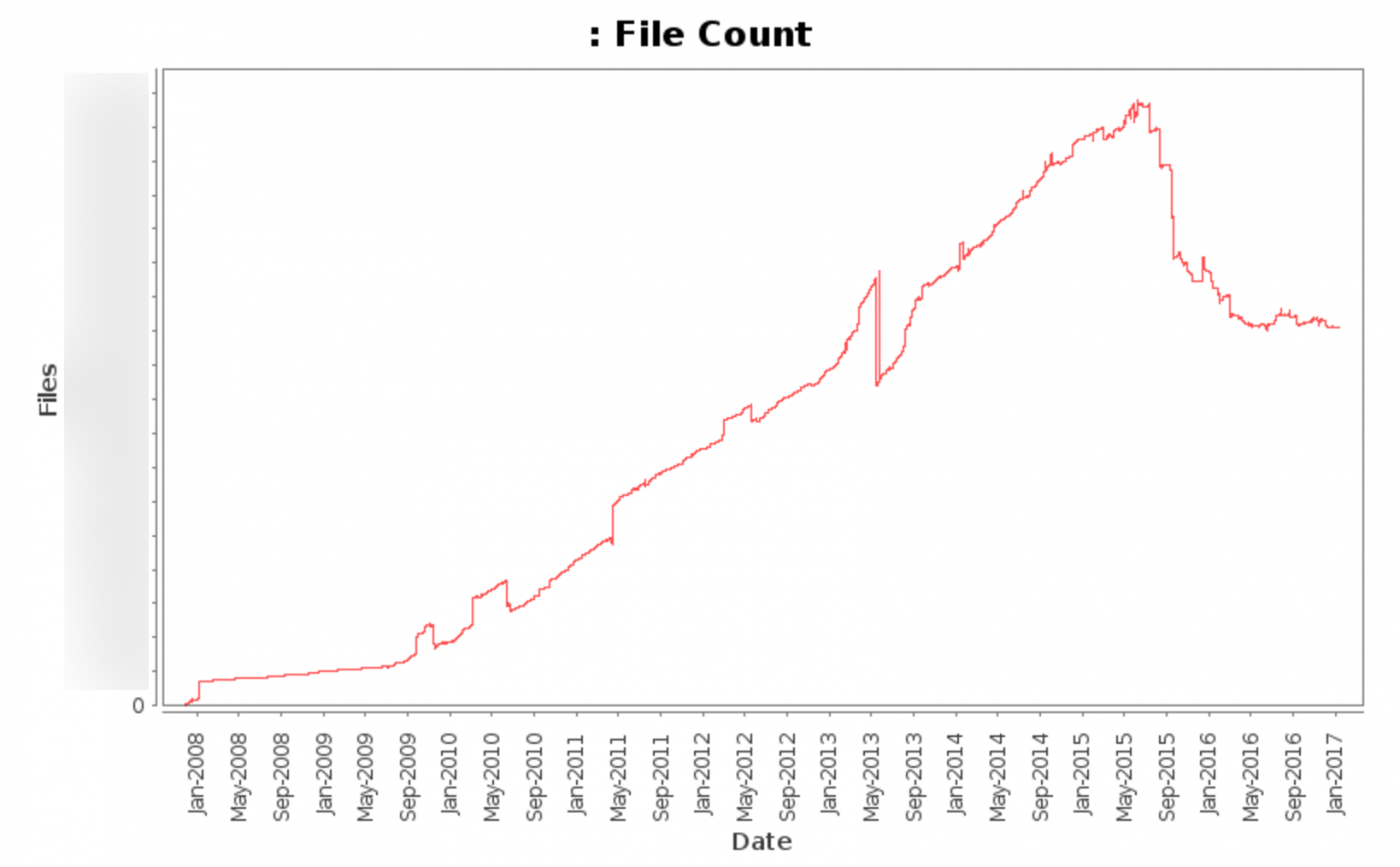
This graph shows our total file count (not including various automatically updated files) from 2008 to today.
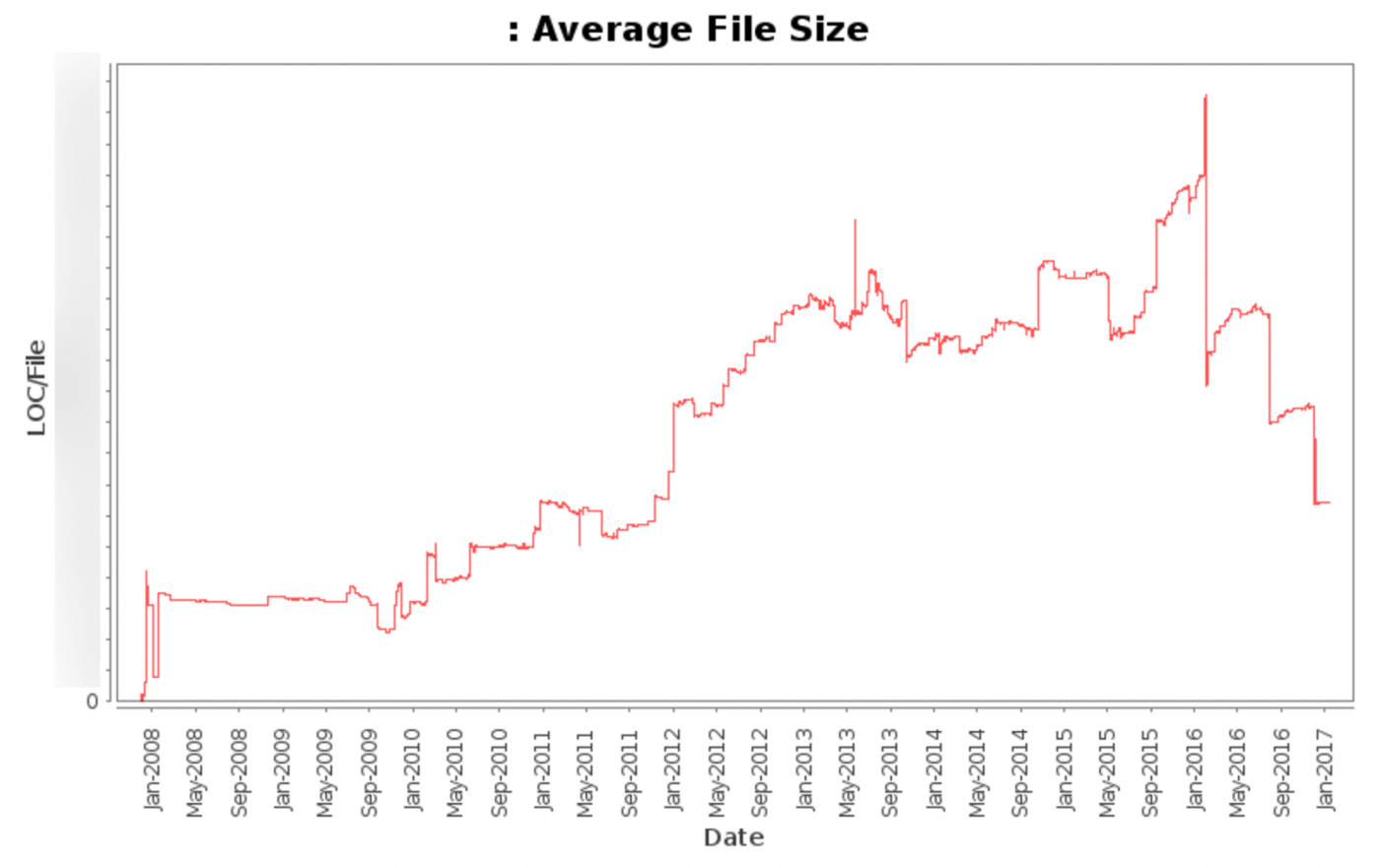
This graph shows our average file size (not including various automatically updated files) from 2008 to today.
The biggest wins to our codebase have been code linting, style check hooks, documenting of our best practices, and holding regular office hours
With linting tooling (puppet-lint) we were able to conform to common community linting standards. We reduced our linting errors and warnings in our codebase by 10s of thousands of lines and touched more than 20% of the codebase.
After an initial cleanup, making smaller changes in the codebase is now easier, and incorporating automated style checking as a version control hook has dramatically cut down on style errors in our codebase.
With over 100 Puppet committers throughout the organization, documenting internal and community best practices has been a force multiplier. Having a single document to reference has improved the quality and speed at which code can be shipped.
Holding regular office hours for assistance (sometimes by invite) has allowed for 1:1 help where tickets and chat channels don’t offer high enough communication bandwidth or didn’t convey the larger picture of what was trying to be accomplished. As a result, most committers have improved their code quality and speed by understanding the community, best practices, and how to best apply changes.
System metrics are not generally useful (see Caitlin McCaffrey’s Monitorama’s 2016 talk here) but do provide additional context to the metrics that we have found useful.
Some of the most useful metrics that we alert upon and graph are:
Each of these metrics is collected per host and aggregated by role. This allows for instant alerting and identification when there are problems across a specific role, set of roles, or a broader impacting event.
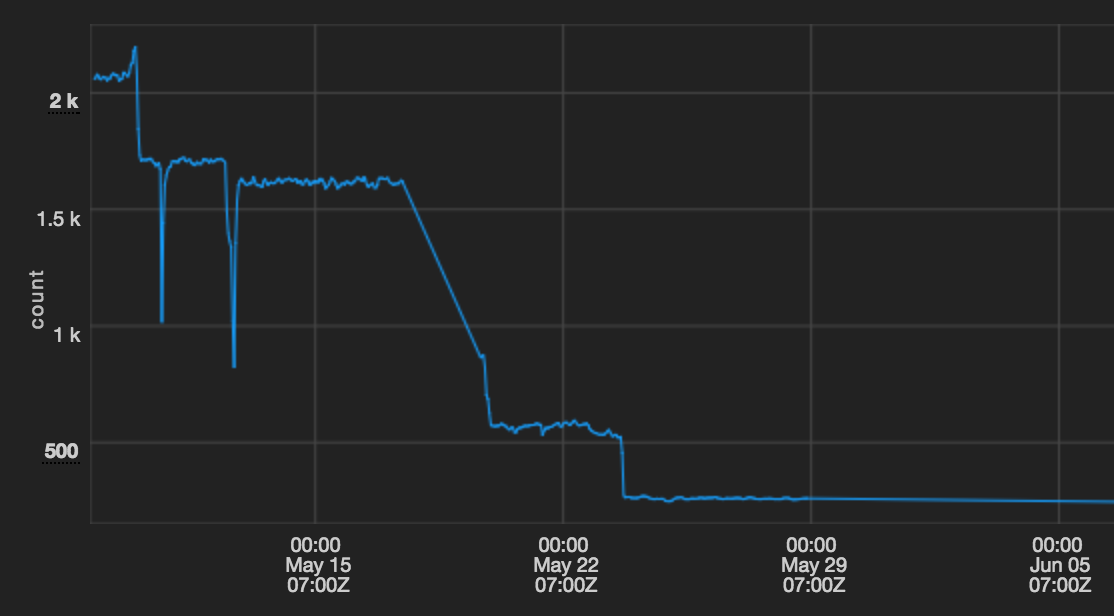
By migrating from Puppet 2 to Puppet 3 and upgrading Passenger (both posts for another time), we were able to reduce our average Puppet runtimes on our Mesos clusters from well over 30 minutes to under 5 minutes.
This graphs shows our average Puppet runtime in seconds on our Mesos clusters.
If you are interested in helping us with our Puppet infrastructure, we are hiring!
If you are interested in the more general system provisioning process, metadata database (Audubon), and lifecycle management (Wilson) the Provisioning Engineering team recently presented at our #Compute event and it was recorded here.
We couldn’t have achieved this without the hard work and dedication of everyone across Twitter Engineering. Kudos to all the current & former engineers who built & contributed to the reliability of Twitter.
Special thanks to Brian Martin, Chris Woodfield, David Barr,Drew Rothstein, Matt Getty, Pascal Borghino, Rafal Waligora, Scott Engstrom, Tim Hoffman, and Yogi Sharma for their contributions to this blog post.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.